
包阅导读总结
1. 关键词:RPC、远程过程调用、自定义框架、Netty、通信协议
2. 总结:
本文介绍了 RPC 的概念、特点、应用场景,重点阐述如何基于 Netty 实现自定义的 RPC 框架,包括通信协议定义、客户端调用及相关功能实现、服务端接收数据及处理等环节。
3. 主要内容:
– 远程过程调用概述
– RPC 概念及特点
– 透明性、客户端-服务器模型、序列化及反序列化、同步及异步调用、错误处理、协议及传输层
– RPC 应用场景
– 分布式系统、客户端-服务器架构、跨平台调用、API 服务、大数据处理、云计算、跨网络服务调用
– 常见的 RPC 框架
– 实现自定义的 RPC
– 主要问题
– 客户端调用、参数序列化、服务端数据接收、执行远程过程、返回结果、客户端接收调用结果
– 自定义通信协议
– 分为 Header 及 Body Content 两部分,规定各部分的作用
– 客户端调用
– 客户端的使用
– 客户端代理工厂的核心功能
– 请求参数序列化
– 请求参数通过网络发送
– Netty 消息编码器
– 服务端接收数据
– 消息解码器
– 请求参数反序列化
思维导图: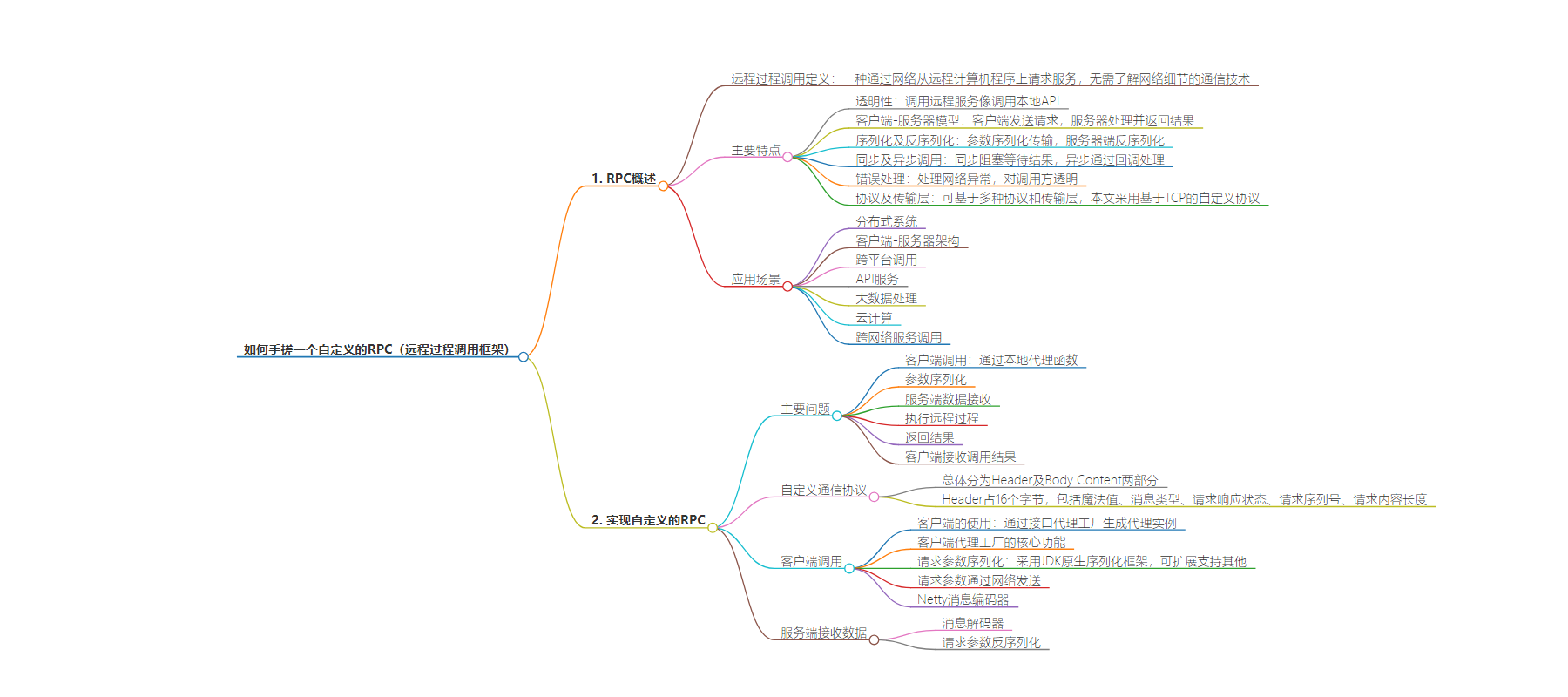
文章地址:https://mp.weixin.qq.com/s/dQUebz5N5WFSoe56VO898A
文章来源:mp.weixin.qq.com
作者:京东科技??陈国友
发布时间:2024/8/1 8:41
语言:中文
总字数:6873字
预计阅读时间:28分钟
评分:86分
标签:RPC,Netty,动态代理,序列化,分布式系统
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

RPC(远程过程调用概述)
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
远程过程调用(RPC, Remote Procedure Call)是一种通过网络从远程计算机程序上请求服务,而无需了解网络细节的通信技术。在分布式系统中,RPC是一种常用的技术,能够简化客户端与服务器之间的交互。本文将介绍如何基于Netty(网络编程框架)实现一个自定义的简单的RPC框架。
1.1 RPC远程过程调用的主要特点
-
透明性:调用方(客户端)调用远程服务就像调用本地API函数一样,而无需关心执行过程中的底层的网络通信细节。
-
客户端-服务器模型:RPC通常基于客户端-服务器模型,客户端发送请求到服务器,服务器处理请求并返回结果。
-
序列化及反序列化:RPC需要将请求参数序列化成字节流(即数据转换成网络可传输的格式)并通过网络传输到服务器端,服务器端接收到字节流后,需按照约定的协议将数据进行反序列化(即恢复成三原始格式)
-
同步及异步调用:RPC支持同步、异步调用。同步调用会阻塞直到服务器返回结果,或超时、异常等。而异步调用则可以立即返回,通过注册一个回调函数,在有结果返回的时候再进行处理。从而让客户端可以继续执行其它操作。
-
错误处理:PRC由于涉及网络通信,因此需要处理各种可能的网络异常,如网络故障,服务宕机,请求超时,服务重启、或上下线、扩缩容等,这些对调用方来说需要保持透明。
-
协议及传输居:RPC可以基于多种协议和传输层实现,如HTTP、TCP等,本文采用的是基于TCP的自定义协议。
1.2 RPC的应用场景
-
分布式系统:多个服务之间进行通信,如微服务框架。
-
客户端-服务器架构:如移动应用与后台服务器的交互。
-
跨平台调用:不同技术栈之间的服务调用。
-
API服务:通过公开API对外提供功能,使用客户端能方便使用服务提供的功能,如支付网关,身份验证服务等。
-
大数据处理:在大数据处理框架中,不同节点之间需要频繁通信来协调任务和交接数据,RPC可以提供高效的节点通信机制,如Hadoop 和Spark等大数据框架中节点间的通信。
-
云计算:在云计算环境中,服务通常分布在多个虚拟机或容器中,通过RPC实现实现服务间的通信和管理。
-
跨网络服务调用:当应用需要调用部署在不同网络中的服务时,RPC提供了一种简单而建议目前的调用方式,如。跨数据中心或嘴唇地域的服务调用。
1.3 常见的RPC框架
-
JSF:京东开源的分布式服务框架,提供高性能、可扩展、稳定的服务治理能力,支持服务注册及发现,负载均衡、容错机制、服务监控、多种协议支持等。
-
gRPC:基于HTTP/2和Protocol Buffers的高性能RPC框架,由Google开发。
-
Dubbo:一个高性能、轻量级的Java RPC框架,用于提供基于接口的远程服务调用,支持负载均衡、服务自动注册及服务、容错等。
-
JSON-RPC:使用JSON格式编码调用和结果的RPC协议。
-
Apache Thrift:由Facebook开发,支持多种编程语言和协议
实现自定义的RPC
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
RPC(远程过程调用概述)
1.1 RPC远程过程调用的主要特点
-
透明性:调用方(客户端)调用远程服务就像调用本地API函数一样,而无需关心执行过程中的底层的网络通信细节。
-
客户端-服务器模型:RPC通常基于客户端-服务器模型,客户端发送请求到服务器,服务器处理请求并返回结果。
-
序列化及反序列化:RPC需要将请求参数序列化成字节流(即数据转换成网络可传输的格式)并通过网络传输到服务器端,服务器端接收到字节流后,需按照约定的协议将数据进行反序列化(即恢复成三原始格式)
-
同步及异步调用:RPC支持同步、异步调用。同步调用会阻塞直到服务器返回结果,或超时、异常等。而异步调用则可以立即返回,通过注册一个回调函数,在有结果返回的时候再进行处理。从而让客户端可以继续执行其它操作。
-
错误处理:PRC由于涉及网络通信,因此需要处理各种可能的网络异常,如网络故障,服务宕机,请求超时,服务重启、或上下线、扩缩容等,这些对调用方来说需要保持透明。
-
协议及传输居:RPC可以基于多种协议和传输层实现,如HTTP、TCP等,本文采用的是基于TCP的自定义协议。
1.2 RPC的应用场景
-
分布式系统:多个服务之间进行通信,如微服务框架。
-
客户端-服务器架构:如移动应用与后台服务器的交互。
-
跨平台调用:不同技术栈之间的服务调用。
-
API服务:通过公开API对外提供功能,使用客户端能方便使用服务提供的功能,如支付网关,身份验证服务等。
-
大数据处理:在大数据处理框架中,不同节点之间需要频繁通信来协调任务和交接数据,RPC可以提供高效的节点通信机制,如Hadoop 和Spark等大数据框架中节点间的通信。
-
云计算:在云计算环境中,服务通常分布在多个虚拟机或容器中,通过RPC实现实现服务间的通信和管理。
-
跨网络服务调用:当应用需要调用部署在不同网络中的服务时,RPC提供了一种简单而建议目前的调用方式,如。跨数据中心或嘴唇地域的服务调用。
1.3 常见的RPC框架
-
JSF:京东开源的分布式服务框架,提供高性能、可扩展、稳定的服务治理能力,支持服务注册及发现,负载均衡、容错机制、服务监控、多种协议支持等。
-
gRPC:基于HTTP/2和Protocol Buffers的高性能RPC框架,由Google开发。
-
Dubbo:一个高性能、轻量级的Java RPC框架,用于提供基于接口的远程服务调用,支持负载均衡、服务自动注册及服务、容错等。
-
JSON-RPC:使用JSON格式编码调用和结果的RPC协议。
-
Apache Thrift:由Facebook开发,支持多种编程语言和协议
实现自定义的RPC
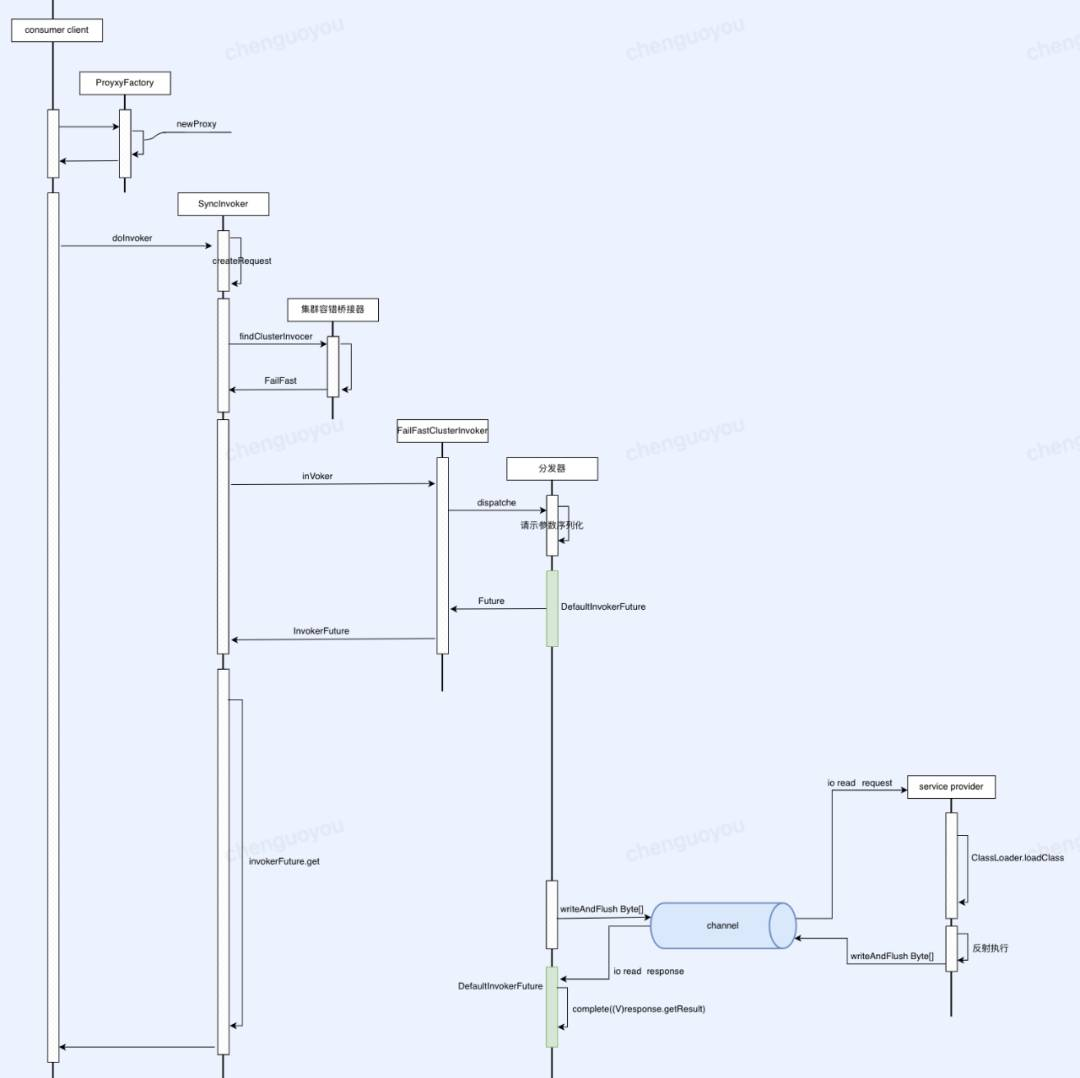
1.客户端调用:客户端调用本地的代理函数(stub代码,这个函数负责将调用转换为RPC请求)。这其实就是一个接口描述文件,它可以有多种形式如JSON、XML、甚至是一份word文档或是口头约定均可,只要客户端及服务端都是遵守这份接口描述文件契约即可。在我们的实际开发中一种常见的方式是服务提供者发布一个包含服务接口类的jar包到maven 中央仓库,调用方通过pom文件将之依赖到本地。
2.参数序列化:代理函数将调用参数进行序列化,并将请求发送到服务器。
3.服务端数据接收:服务器端接收到请求,并将其反序列化,恢复成原始参数。
4.执行远程过程:服务端调用实际的服务过程(函数)并获取结果。
5.返回结果:服务端将调用结果进行序列化,并通过网络传给客户端。
2.1 自定义通信协议
2.2 客户端调用
2.2.1 客户端的使用
首先看一下客户端的使用方式,本文假设一个IShoppingCartService (购物车)的接口类,基中有一个方法根据传入的用户pin,返回购物车详情。
ShoppingCart shopping(String pin);
IShoppingCartService serviceProxy = ProxyFactory.factory(IShoppingCartService.class).setSerializerType(SerializerType.JDK).newProxyInstance();
ShoppingCart result = serviceProxy.shopping("userPin");log.info("result={}", JSONObject.toJSONString(result));
2.2.2 客户端代理工厂的核心功能
public class ProxyFactory<I> {public I newProxyInstance() {ServiceData serviceData = new ServiceData(group,providerName,StringUtils.isNotBlank(version) ? version : "1.0.0");Calller caller = newCaller().timeoutMillis(timeoutMillis);Strategy strategy = StrategyConfigContext.of(strategy, retries);Object handler = null;switch (invokeType) {case "syncCall":handler = new SyncCaller(serviceData, caller);break;case "asyncCall":handler = new AsyncCaller(client.appName(), serviceData, caller, strategy);break;default:throw new RuntimeException("未知类型: " + invokeType);}return ProxyEnum.getDefault().newProxy(interfaceClass, handler);}}
代码 ProxyEnum.getDefault().newProxy(interfaceClass, handler) 返回一个具体的代理实例,此方法要求传入两个参数,interfaceClass 被代理的接口类class,即服务方所发布的服务接口类。
1.JDK动态代码,如采用此方式,handler 需要实现接口 InvocationHandler
本文默认采用第二种方式,通过代码简单展示一下代理实例的的生成方式。
public <T> T newProxy(Class<T> interfaceType, Object handler) {Class<? extends T> cls = new ByteBuddy().subclass(interfaceType).method(ElementMatchers.isDeclaredBy(interfaceType)).intercept(MethodDelegation.to(handler, "handlerInstance")).make().load(interfaceType.getClassLoader(), ClassLoadingStrategy.Default.INJECTION).getLoaded();try {return cls.newInstance();} catch (Throwable t) {……}}
public class SyncCaller extends AbstractCaller {@RuntimeTypepublic Object syncCall(@Origin Method method, @AllArguments @RuntimeType Object[] args) throws Throwable {StarGateRequest request = createRequest(methodName, args);Invoker invoker = new FastFailInvoker();Future<?> future = invoker.invoke(request, method.getReturnType());if (sync) {Object result = future.getResult();return result;} else {return future;}}}
2.2.3 请求参数序列化
我们将请求参数序列化的目的就是将具体的请求参数转换成字节组,填充进入上述自定义协议的 body content 部分。下面通过代码演示一下如何进行反序列化。
public <T> Future<T> invoke(StarGateRequest request, Class<T> returnType) throws Exception {final Serializer _serializer = serializer();final Message message = request.message();Channel channel = selectChannel(message.getMetadata());byte code = _serializer.code();byte[] bytes = _serializer.writeObject(message);request.bytes(code, bytes);return write(channel, request, returnType);}
public <T> byte[] writeObject(T obj) {ByteArrayOutputStream buf = OutputStreams.getByteArrayOutputStream();try (ObjectOutputStream output = new ObjectOutputStream(buf)) {output.writeObject(obj);output.flush();return buf.toByteArray();} catch (IOException e) {ThrowUtil.throwException(e);} finally {OutputStreams.resetBuf(buf);}return null;}
2.2.4 请求参数通过网络发送
protected <T> DefaultFuture<T> write(final Channel channel,final StarGateRequest request,final Class<T> returnType) {final Future<T> future = DefaultFuture.newFuture(request.invokeId(), channel, timeoutMillis, returnType);channel.writeAndFlush(request).addListener((ChannelFutureListener) listener -> {if (listener.isSuccess()) {……} else {DefaultFuture.errorFuture(channel, response, dispatchType);}});return future;}
2.2.4.1 Netty 消息编码器
public class StarGateEncoder extends MessageToByteEncoder<Payload> {private void doEncodeRequest(RequestPayload request, ByteBuf out) {byte sign = StarGateProtocolHeader.toSign(request.serializerCode(), StarGateProtocolHeader.REQUEST);long invokeId = request.invokeId();byte[] bytes = request.bytes();int length = bytes.length;out.writeShort(StarGateProtocolHeader.Head).writeByte(sign).writeByte(0x00).writeLong(invokeId).writeInt(length).writeBytes(bytes);}}
至此,通过上述核心代码,客户的请求已经按照自定义的协议格式进行了序列化,并把数据写入到Netty channel中,最后通过物理网络传输到服务器端。
2.3 服务端接收数据
2.3.1 消息解码器
服务器端接收到客户端的发送的数据后,需要进行正确的消息解码,下面是解码器的实现。
public class StarGateDecoder extends ReplayingDecoder<StarGateDecoder.State> {@Overrideprotected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {switch (state()) {case HEAD:checkMagic(in.readShort());checkpoint(State.HEAD);case SIGN:header.sign(in.readByte());checkpoint(State.STATUS);case STATUS:header.status(in.readByte());checkpoint(State.ID);case ID:header.id(in.readLong());checkpoint(State.BODY_SIZE);case BODY_SIZE:header.bodySize(in.readInt());checkpoint(State.BODY);case BODY:switch (header.messageCode()) {case StarGateProtocolHeader.REQUEST: {int length = checkBodySize(header.bodySize());byte[] bytes = new byte[length];in.readBytes(bytes);RequestPayload request = new RequestPayload(header.id());request.bytes(header.serializerCode(), bytes);out.add(request);break;}default:throw new Exception("错误标志位");}checkpoint(State.HEAD);}}}
2.3.2 请求参数反序列化
public class ServiceHandler extends ChannelInboundHandlerAdapter {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {Channel ch = ctx.channel();if (msg instanceof RequestPayload) {StarGateRequest request = new StarGateRequest((RequestPayload) msg);byte code = request.serializerCode();Serializer serializer = SerializerFactory.getSerializer(code);byte[] bytes = payload.bytes();Message message = serializer.readObject(bytes, Message.class);log.info("message={}", JSONObject.toJSONString(message));request.message(message);process(message);} else {ReferenceCountUtil.release(msg);}}}
2.3.3 处理客户端请求
经过反序列化后,服务端可以知道用户所请求的是哪个接口、方法、以及实际的参数值,下一步就可进行真实的方法调用。
public void process(Message message) {try {ServiceMetadata metadata = msg.getMetadata();String providerName = metadata.getProviderName();providerName = findServiceImpl(providerName);String methodName = msg.getMethodName();Object[] args = msg.getArgs();ClassLoader classLoader = Thread.currentThread().getContextClassLoader();Class<?> clazz = classLoader.loadClass(providerName);Object instance = clazz.getDeclaredConstructor().newInstance();Method method = null;Class<?>[] parameterTypes = new Class[args.length];for (int i = 0; i < args.length; i++) {parameterTypes[i] = args[i].getClass();}method = clazz.getMethod(methodName, parameterTypes);Object invokeResult = method.invoke(instance, args);} catch (Exception e) {log.error("调用异常:", e);throw new RuntimeException(e);}doProcess(invokeResult);}
2.3.4 返回调用结果
private void doProcess(Object realResult) {ResultWrapper result = new ResultWrapper();result.setResult(realResult);byte code = request.serializerCode();Serializer serializer = SerializerFactory.getSerializer(code);Response response = new Response(request.invokeId());byte[] bytes = serializer.writeObject(result);response.bytes(code, bytes);response.status(Status.OK.value());channel.writeAndFlush(response).addListener(new ChannelFutureListener() {@Overridepublic void operationComplete(ChannelFuture channelFuture) throws Exception {if (channelFuture.isSuccess()) {log.info("响应成功");} else {log.error("响应失败, channel: {}, cause: {}.", channel, channelFuture.cause());}}});}
同样的,消息写入channel 后,先依次经过pipline 上所安装的 消息编码器,再发送给客户端。具体编码方式同客户端编码器类似,此处不再赘述。
2.4 客户端接收调用结果
客户端收到服务端写入响应消息后,同样经过Netty channel pipline 上所安装的解码器,进行正确的解码。然后再对解码后的对象进行正确的反序列化,最终获得调用结果 。具体的解码,反序列化过程不再赘述,流程基本同上面服务端的解码及反序列化类似。
public class consumerHandler extends ChannelInboundHandlerAdapter {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {Channel ch = ctx.channel();if (msg instanceof ResponseMessage) {try {ResponseMessage responseMessage= (ResponseMessage)msgStarGateResponse response = new StarGateResponse(ResponseMessage.getMsg());byte code = response.serializerCode();Serializer serializer = SerializerFactory.getSerializer(code);byte[] bytes = responseMessage.bytes();Result result = serializer.readObject(bytes, Result.class);response.result(result);long invokeId = response.id();DefaultFuture<?> future = FUTURES_MAP.remove(invokeId);byte status = response.status();if (status == Status.OK.value()) {complete((V) response.getResult());} else {}} catch (Throwable t) {log.error("调用记录: {}, on {} #channelRead().", t, ch);}} else {log.warn("消息类型不匹配: {}, channel: {}.", msg.getClass(), ch);ReferenceCountUtil.release(msg);}}}
结尾
本文首先简单介绍了一下RPC的概念、应用场景及常用的RPC框架,然后讲述了一下如何自己手动实现一个RPC框架的基本功能。目的是想让大家对RPC框架的实现有一个大概思路,并对Netty 这一高效网络编程框架有一个了解,通过对Netty 的编、解码器的学习,了解如何自定义一个私有的通信协议。限于篇幅本文只简单讲解了RPC的核心的调用逻辑的实现。真正生产可用的RPC框架还需要有更多复杂的功能,如限流、负载均衡、融断、降级、泛型调用、自动重连、自定义可扩展的拦截器等等。
另外RPC框架中一般有三种角色,服务提供者、服务消费者、注册中心,本文并没有介绍注册中心如何实现。并假定服务提供者已经将服务发布到了注册中心,服务消费者跟服务提供者之间建立起了TCP 长连接。
后续会通过其它篇章介绍注册中心,服务自动注册,服务发现等功能的实现原理。
▪功能支撑:会员成长体系、等级计算策略、权益体系、营销底层能力支持
▪用户活跃:会员关怀、用户触达、活跃活动、业务线交叉获客、拉新促活