
包阅导读总结
1. 关键词:GenAI 、Superlinked 、Redis 、Vector Database 、Recommender Systems
2. 总结:本文介绍了使用 Superlinked 和 Redis 构建更智能和快速的 GenAI 应用,重点阐述了其在解决 GenAI 推荐系统面临的挑战方面的优势,并通过电商平台案例展示效果,还提供了构建应用的步骤指南。
3. 主要内容:
– 背景
– GenAI 应用潜力大,但许多企业在将其推向生产时遇阻。
– 解决 GenAI 推荐系统的挑战
– 真实数据复杂,LLMs 处理结构化数据能力差。
– 仅用非结构化数据的推荐器在生产中表现不佳。
– Redis 和 Superlinked 的组合优势
– Superlinked 能创建结合结构化和非结构化数据的向量嵌入。
– Redis 向量数据库响应快,适用于客户需求。
– Superlinked 框架简化生产流程。
– 电商平台案例
– 某电商平台因推荐问题导致收益机会流失。
– 使用 Superlinked 和 Redis 构建实时个性化推荐系统,平均订单价值提升 4 倍。
– 构建应用的步骤
– 安装 Superlinked ,定义数据模式。
– 创建数据空间,定义查询映射。
– 加载数据,进行实验。
– 部署,安装 Superlinked 服务器,连接 Redis 实例,配置 Superlinked 服务器。
思维导图:
文章地址:https://redis.io/blog/build-genai-apps-with-superlinked-and-redis/
文章来源:redis.io
作者:kevin.wiley@redis.com
发布时间:2024/8/7 14:38
语言:英文
总字数:1511字
预计阅读时间:7分钟
评分:87分
标签:生成式 AI 应用,向量数据库,推荐系统,Redis,Superlinked
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Build smarter and faster GenAI apps with Superlinked and Redis
It’s no secret. GenAI apps can boost operations, enhance customer experience, and cut costs. But many enterprise tech teams get stuck in the proof-of-concept (POC) phase, struggling to move these high-performing apps to production.
That’s where Redis’ blazing-fast vector database and Superlinked’s vector compute framework come in handy. For complex data, it just might be the solution you’ve been looking for.
Overcome the challenge of GenAI recommenders
Real data is complex, and large language models (LLMs) are notoriously bad at understanding and handling structured data types like prices, dates, product categories, and popularity metrics. These data types are critical for high-quality information retrieval across multiple use cases, and in particular in recommender systems, and personalized semantic search.
Recommenders that only use unstructured data might work well on a small scale, but they often underperform in production. Customers want fast recommendations that match their recent behavior, category, and price range. To make this happen, tech teams often develop and train custom embedding and re-ranking models, a challenging endeavor for most enterprise tech teams. That’s why most GenAI-powered recommender systems get stuck in the POC phase and rarely deliver on their promise.
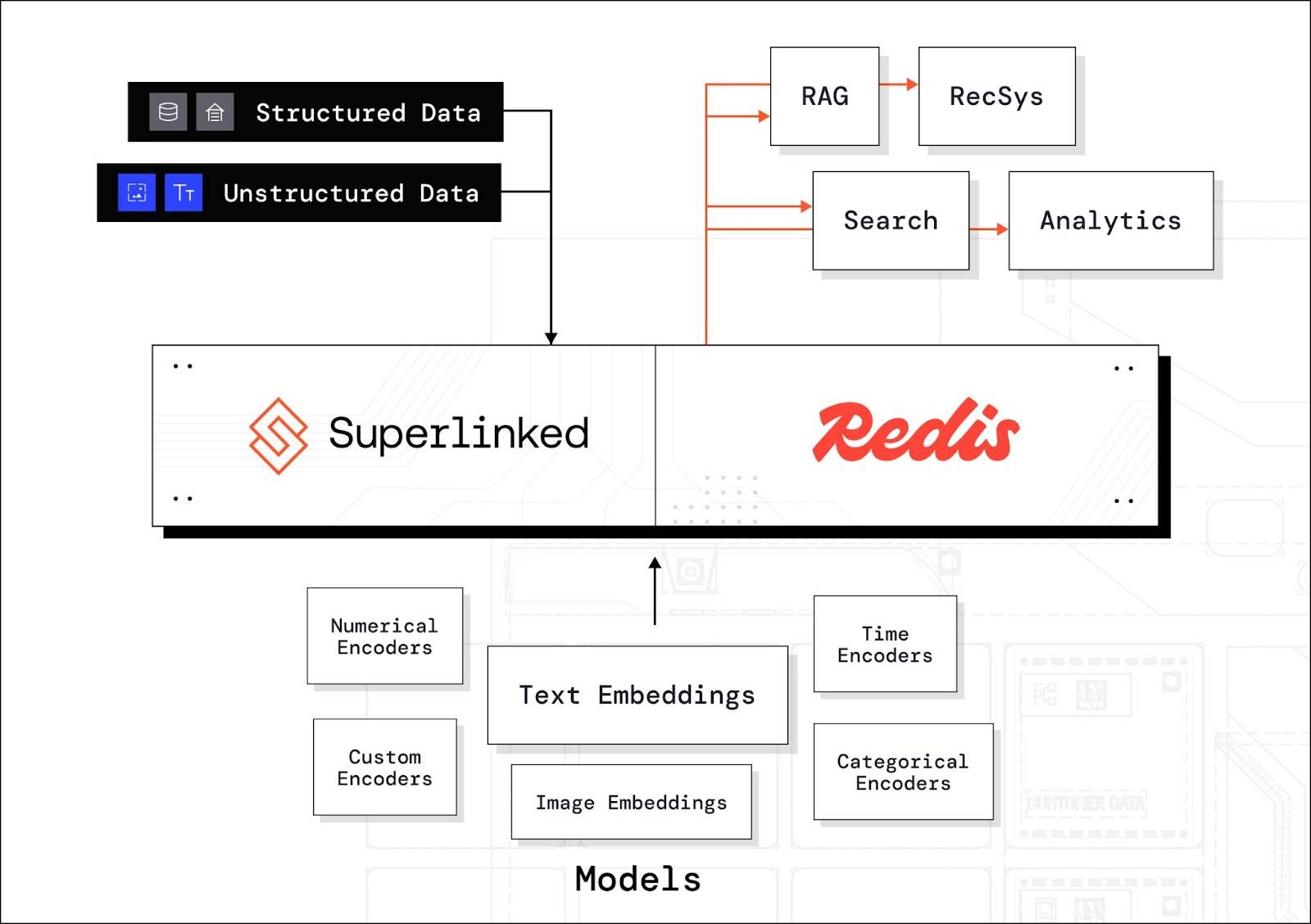
Redis and Superlinked is a winning combination
Superlinked‘s vector compute framework lets data science teams create custom vector embeddings that combine structured and unstructured data in one unified vector space. This aligns with user insights and delivers custom model performance with pre-trained model convenience.
Redis’ lightning-fast vector database, based on in-memory storage, is perfect for customer-facing use cases that need quick responses like real-time recommender systems. Users respond better to recommendations that match their interests now, not later, when they’ve moved on.
Superlinked’s framework also simplifies the route to production, saving time for data and ML engineering resources. Data scientists can build and test their solutions in a Python notebook and compile them directly to a cloud service. This seamless transition from development to deployment accelerates time-to-market and ensures robust, scalable solutions.
See how this large e-commerce platform hit 4x AOV growth
A major e-commerce platform faced low engagement with product recommendations. The issue stemmed from their constantly changing product catalog and reliance on static, non-personalized recommendation methods, resulting in missed revenue opportunities.
Using Superlinked to generate the vector embeddings from structured and unstructured product data, and Redis to deliver the vector search results in real-time, the client was able to launch a real-time personalized recommender system within weeks. The system presented users with highly relevant and timely recommendations, taking into account their browsing behavior within seconds, resulting in a 4x uplift in Average Order Value (AOV) for exposed users.
Get started with Superlinked and Redis
Below you’ll find a step-by-step guide for building your first simple application with Superlinked, using Redis as the vector database and search solution. This semantic search application allows users to perform a free text search within a database of product reviews and demonstrates how combining the unstructured text of the review with the star ratings of the product embedded as a numeric value in the same vector space delivers higher-quality and more relevant results.
You can try a complete example of an app, and, as always, refer to the official README for the latest details. Once you master this example, explore additional notebooks, including an example of an e-commerce recommender system.
Experiment in your Python notebook environment
Step 1: Install Superlinked
Step 2: Define the data schema
# we are going to create 2 representations of the data## 1. separate text and ranking for multimodal superlinked embeddings## 2. full_review_as_text for LLM embedding of stringified review and rating@schemaclass Review: id: IdField review_text: String rating: Integer full_review_as_text: String
Step 3: Create the spaces to encode different parts of data
# Embed review data separatelyreview_text_space = TextSimilaritySpace( text=review.review_text, model="all-MiniLM-L6-v2")rating_maximizer_space = NumberSpace(review.rating, min_value=1, max_value=5, mode=Mode.MAXIMUM)## Embed the full review as textfull_review_as_text_space = TextSimilaritySpace( text=review.full_review_as_text, model="all-MiniLM-L6-v2"# Combine spaces as vector parts to an index.## Create one for the stringified review naive_index = Index([full_review_as_text_space])## and one for the structured multimodal embeddingsadvanced_index = Index([review_text_space, rating_maximizer_space])
Step 4: Define the query mapping to each index type
openai_config = OpenAIClientConfig(api_key=userdata.get("openai_api_key"), model="gpt-4o")# Define your query using dynamic parameters for query text and weights.## first a query on the naive index - using natural languagenaive_query = ( Query( naive_index, weights={ full_review_as_text_space: Param('full_review_as_text_weight') }, ) .find(review) .similar(full_review_as_text_space.text, Param("query_text")) .limit(Param('limit')) .with_natural_query(Param("natural_query"), openai_config))## and another on the advanced multimodal index - also using natural languagesuperlinked_query = ( Query( advanced_index, weights={ review_text_space: Param('review_text_weight'), rating_maximizer_space: Param('rating_maximizer_weight'), }, ) .find(review) .similar(review_text_space.text, Param("query_text")) .limit(Param('limit')) .with_natural_query(Param("natural_query"), openai_config))
Note: Superlinked supports two ways of setting weights for the different query parts:
- “Natural language queries” – using .with_natural_query – dynamically and automatically parse user queries and set the weights
- Pre-defined weights – developers can set weights for each part of the query based on business logic or known user preferences
Step 5: Load the data
# Run the appsource: InMemorySource = InMemorySource(review, parser=DataFrameParser(schema=review))executor = InMemoryExecutor(sources=[source], indices=[naive_index, advanced_index]])app = executor.run()# Download datasetdata = pd.read_json("https://storage.googleapis.com/superlinked-preview-test-data/amazon_dataset_1000.jsonl",lines=True)# Ingest data to the framework.source.put([data])
Step 6: Run experiments with different representations, until you are satisfied with the results
# query that is based on the LLM embedded reviewsnaive_positive_results = app.query( naive_query, natural_query='High rated quality products', limit=10)naive_positive_results.to_pandas()# query based on multimodal Superlinked embeddingssuperlinked_positive_results = app.query( superlinked_query, natural_query='High rated quality products', limit=10)superlinked_positive_results.to_pandas()
See for yourself
Notice how creating a multimodal vector using custom embeddings improves the quality of the results. Compare the top three results for the query “High rated quality products” in the table below, and you’ll see how the LLM “misinterprets” the query and fetches a clearly wrong result in the third position.
| Results based solely on the text | Results based on text and rating | ||
| Review text | Rating | Review text | Rating |
| Good Product Good Product | Good Product Good Product | ||
| Can’t beat this deal! Great amount of products for the price. A lot of sample sizes but the value on some of the products is insane. Loved trying so many things that I wouldn’t consider normally. | Can’t beat this deal! Great amount of products for the price. A lot of sample sizes but the value on some of the products is insane. Loved trying so many things that I wouldn’t consider normally. | 5 | |
| Cheap product Not good | Good product Works great | 5 | |
Ready to deploy?
Step 7: Install Superlinked server (refer to the server README for the latest instructions)
# Clone the repositorygit clone https://github.com/superlinked/superlinkedcd <repo-directory>/server./tools/init-venv.shcd runnersource "$(poetry env info --path)/bin/activate"cd ..# Make sure you have your docker engine running and activate the virtual environment./tools/deploy.py up
Step 8: Connect to your Redis instance (refer to Redis documentation for instructions)
from superlinked.framework.dsl.storage.redis_vector_database import RedisVectorDatabasevector_database = RedisVectorDatabase(# Your Redis URL without port or any extra fields "<your_redis_host>",# Port number, which should be an integer 12315, # The params can be found here: https://redis.readthedocs.io/en/stable/connections.html username="<username>", password="<password>")
Step 9: Configure the Superlinked server – add your configuration from the notebook (Steps 2, 3) and append the deployment setup
# Copy your configuration to app.py# ...# Create a data source to bulk load your production data.config = DataLoaderConfig("https://storage.googleapis.com/superlinked-sample-datasets/amazon_dataset_ext_1000.jsonl", DataFormat.JSON, pandas_read_kwargs={"lines": True, "chunksize": 100})source = DataLoaderSource(review, config)executor = RestExecutor( # Add your data source sources=[source], # Add the indices that contains your configuration indices=[index], # Create a REST endpoint for your query. queries=[RestQuery(RestDescriptor("naive_query"), naive_query), RestQuery(RestDescriptor("superlinked_query"), superlinked_query)], # Connect to Redis vector_database=RedisVectorDatabase())SuperlinkedRegistry.register(executor)
Step 10: Test your deployment
# Trigger the data load curl -X POST 'http://localhost:8080/data-loader/review/run'# Check the status of the loader curl -X GET 'http://localhost:8080/data-loader/review/status'# Send your first querycurl -X POST \ 'http://localhost:8080/api/v1/search/superlinked_query' \ --header 'Accept: */*' \ --header 'Content-Type: application/json' \ --data-raw '{ "natural_query": "High rated quality products", "limit": 10 }'
Congratulations. You learned how to build your first solution that combines numeric and unstructured data in the same embedding space to deliver high-quality results. We’re excited to see the amazing applications that you’ll build with Superlinked and Redis — don’t hesitate to share your work with us.
Conclusion
In the words of Ash Vijayakanthan, SVP of Cloud Sales and Partnerships at Redis: “Redis is partnering with Superlinked to make vector databases easier to apply to complex data for use cases like RAG with LLMs and e-commerce recommendation systems”. It’s a partnership that helps enterprises overcome the hurdles of moving from proof-of-concept to production and realize the full potential of their GenAI apps.
Related resources
Solutions
Redis vector database
Build real-time apps that exceed expectations for responsiveness and include complex processing with low latency.
Solutions
Superlinked
Superlinked is a compute framework for your information retrieval and feature engineering systems, focused on turning complex data into vector embeddings.
Solutions
Superlinked examples
Compute tooling for vector-powered apps.