
包阅导读总结
1. 关键词:Bigtable、SQL、Plaid、NoSQL、灵活数据模型
2. 总结:Bigtable 现支持 SQL,这对开发者是重大改变。介绍了 Bigtable 的特点、SQL 支持带来的新功能和对灵活数据模型的支持,强调其在保持 NoSQL 特性基础上为开发者提供便利。
3. 主要内容:
– Bigtable 支持 SQL,Plaid 称其增强的支持和计数器是变革
– Bigtable 是大数据运动的先驱技术,数据模型灵活但与传统关系型数据库不同
– Bigtable SQL 支持新增类型和函数,增强时间序列能力,默认确保基本查询类似常见 SQL
– Bigtable 仍是 NoSQL 系统,需优化模式,为寻求低延迟、可扩展且不想学新查询 API 的开发者提供选择
– Bigtable 用 MAP 数据类型支持灵活数据模型,列族在 SQL 中变为地图数据类型,维持灵活模式
– 举例展示如何从地址列族中返回街道列属性
思维导图: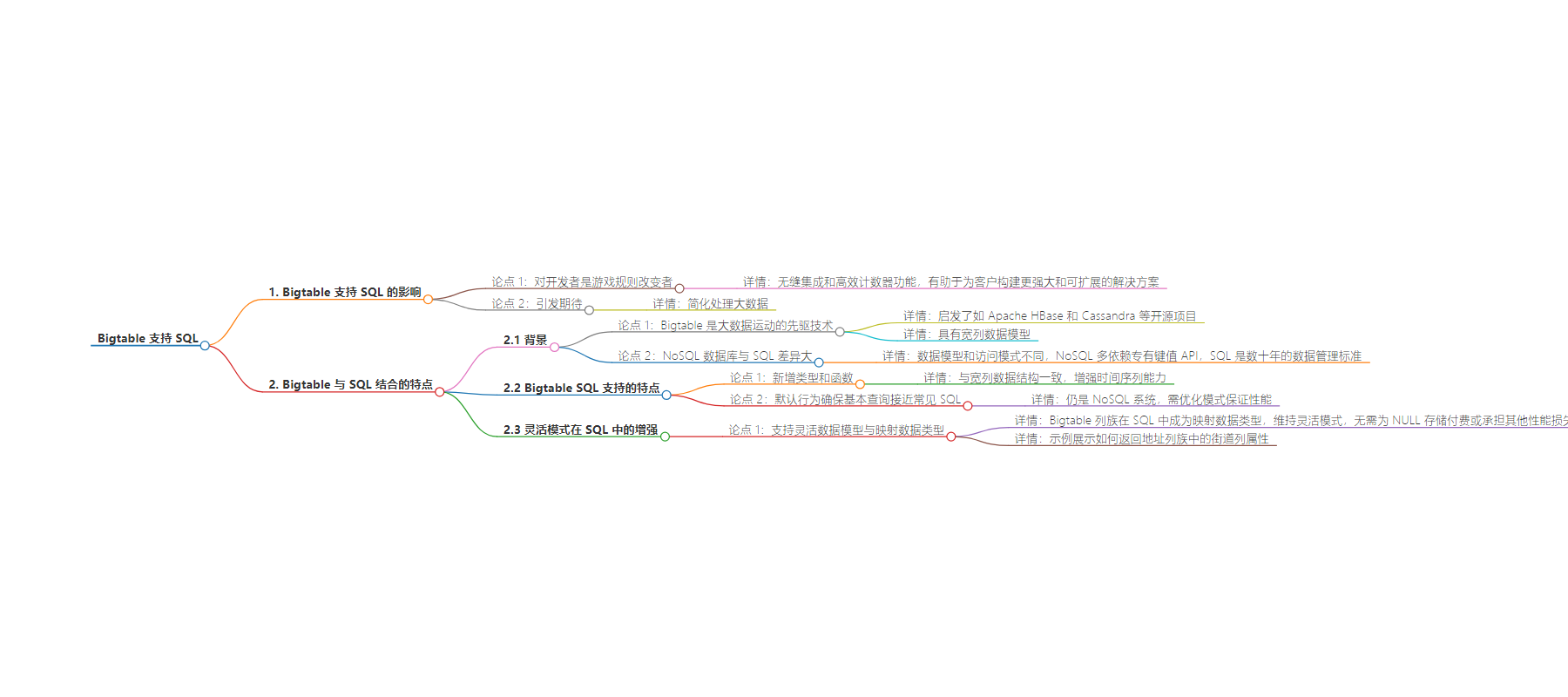
文章地址:https://cloud.google.com/blog/products/databases/announcing-sql-support-for-bigtable/
文章来源:cloud.google.com
作者:Christopher Crosbie,Gary Elliott
发布时间:2024/8/2 0:00
语言:英文
总字数:1533字
预计阅读时间:7分钟
评分:85分
标签:大表,SQL 支持,NoSQL,谷歌云平台,数据处理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
At Plaid, a leading provider of customer experience (CX) solutions, Bigtable’s enhanced SQL support and counters are game-changers for developers.
“Seamless SQL integration and efficient counter functionality will empower us to build more robust and scalable solutions for our customers. We applaud Bigtable’s commitment to innovation and eagerly anticipate leveraging these enhancements to simplify working with big, complex, and fast moving data.” – Jun Kusahana, Executive Officer, VP of Engineering, Plaid
Let’s get started and explore how GoogleSQL can enhance your Bigtable experience.
A SQL interface for a NoSQL database? How does that work?
Bigtable is one of the pioneering techs of the big data movement, inspiring popular open-source projects such as Apache HBase and Cassandra. One of its defining characteristics is its wide-column data model, which allows each row to have a different set of columns — and many thousands of them if necessary. This flexibility is beneficial for many use cases but leads to data models and access patterns that are quite different from the typical relational databases where SQL originated. Because of this, most NoSQL database systems had to rely on proprietary key-value APIs, even though SQL has been a skill in every developer’s tool belt as the de-facto data management standard for decades.
Bigtable SQL support adds new types and functions that align with wide-column data structures and enhance SQL with time-series capabilities. But while Bigtable SQL introduces expanded capabilities, its default behavior is designed to ensure that basic queries still behave as close to common SQL as possible. That said, Bigtable remains a NoSQL system, so you’ll still need to optimize your schemas for performance using schema design best practices. This means that if you’re looking for a low-latency, scalable NoSQL database but don’t want to learn a new query API, SQL on Bigtable is an option that provides data model flexibility.
Let’s learn more about how to get started with some of these enhancements for flexible schema in SQL.
Support for flexible data models with map data types
In Bigtable’s wide column model, there is a row key and then a set of values, each grouped within a column family. When these column families are queried through SQL, Bigtable treats existing tables as a collection of SQL columns of type MAP<key, value> and a _key column for the row key. In essence, the Bigtable column family becomes a map data type in SQL.
With this approach, a flexible schema is maintained within the confines of SQL. Each Bigtable row can have many thousands of columns (if necessary) within column families and can be completely different between rows without having to pay for NULL storage or take other performance penalties.
The below example shows how you would return a column attribute of street from within the column family of address.