
包阅导读总结
1. 关键词:Photon、Feature Engineering、Databricks、Speed Up、Machine Learning
2. 总结:Photon Engine 能在 Databricks Machine Learning Runtime 中启用,大幅加速 Spark 作业和特征工程工作负载,通过新的点即时连接等方式实现,用户可在特定版本的 ML Runtime 集群中选择使用 Photon 加速。
3. 主要内容:
– 训练高质量机器学习模型需要精心准备数据和特征
– 处理大数据表时,ETL 管道和特征工程可能耗时
– Photon Engine 能加速 Spark 作业和特征工程,在 Databricks Machine Learning Runtime 可用
– 举例说明 Photon 能大幅减少生成训练数据集的时间
– 介绍 Photon 是高性能查询引擎,以 C++实现,替换特定 Spark 执行单元
– 阐述 Photon 对机器学习工作负载的帮助,如加速 ETL 和特征工程
– 给出不同规模特征表点即时连接时 Photon 的加速效果对比
– 说明在 Databricks Machine Learning Runtime 集群中选择 Photon 的方法及相关版本
思维导图:
文章地址:https://www.databricks.com/blog/accelerate-feature-engineering-photon
文章来源:databricks.com
作者:Databricks
发布时间:2024/8/2 19:09
语言:英文
总字数:569字
预计阅读时间:3分钟
评分:91分
标签:Photon 引擎,特征工程,Databricks,机器学习,ETL
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Training a high-quality machine learning model requires careful data and feature preparation. To fully utilize raw data stored as tables in Databricks, running ETL pipelines and feature engineering may be required to transform the raw data into helpful feature tables. If your table is large, this step could be very time-consuming. We are excited to announce that the Photon Engine can now be enabled in Databricks Machine Learning Runtime, capable of speeding up spark jobs and feature engineering workloads by 2x or more.
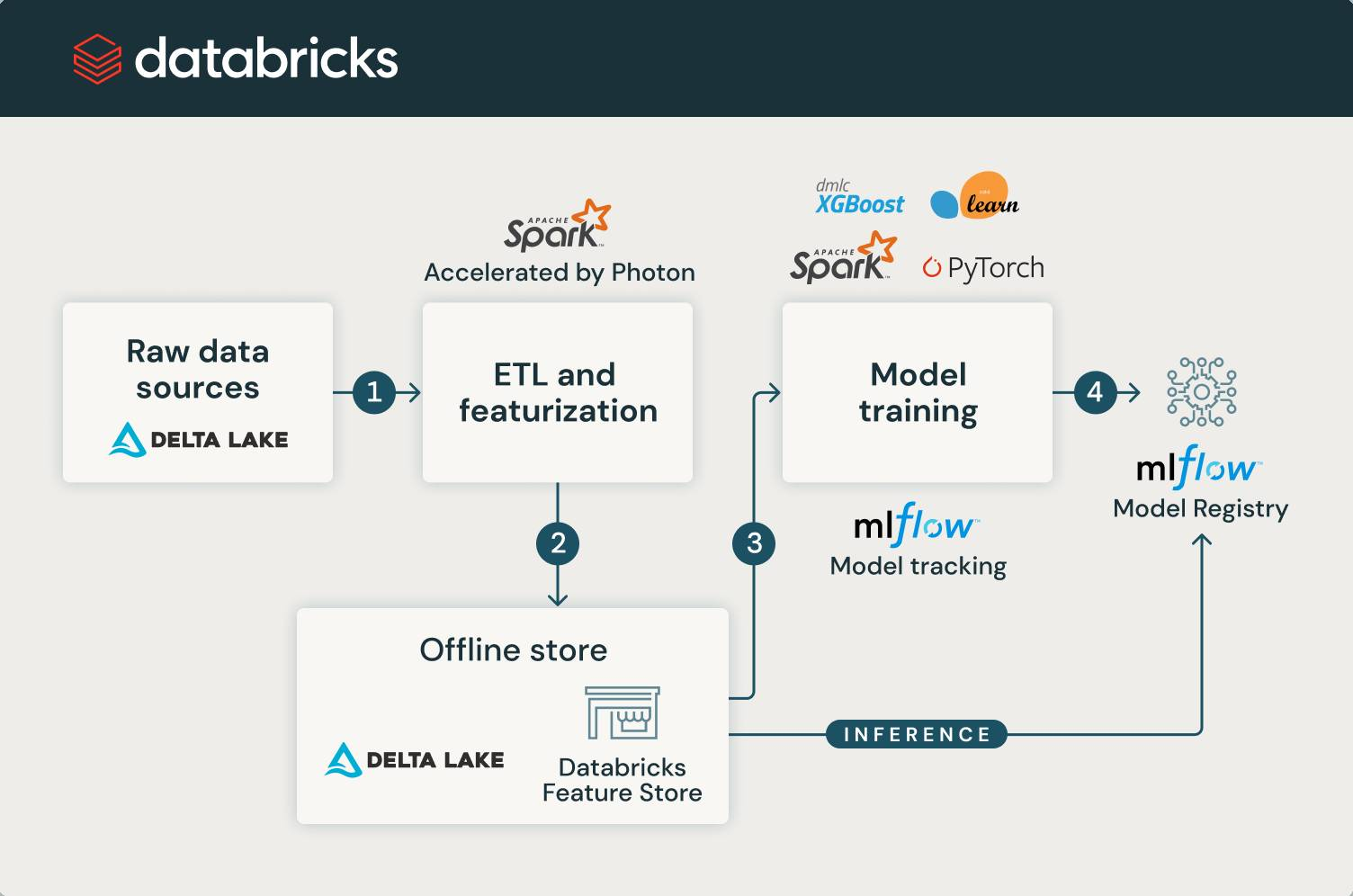
“By enabling Photon and using a new PIT join, the time required to generate the training dataset using our Feature Store was reduced by more than 20 times.” – Sem Sinchenko, Advanced Analytics Expert Data Engineer, Raiffeisen Bank International AG
What is Photon?
The Photon Engine is a high-performance query engine that can run Spark SQL and Spark DataFrame faster, reducing the total cost per workload. Under the hood, Photon is implemented with C++, and specific Spark execution units are replaced with Photon’s native engine implementation.
How does Photon help machine learning workloads?
Now that Photon can be enabled in Databricks Machine Learning Runtime, when does it make sense to integrate a Photon-enabled cluster for machine learning development workflows? Here are some of the main considerations:
- Faster ETL: Photon speeds up Spark SQL and Spark DataFrame workloads for data preparation. Early customers of Photon have observed an averagespeedup of2x-4xfor their SQL queries.
- Faster feature engineering: When using the Databricks Feature Engineering Python API for time series feature tables, point-in-time join becomes faster when Photon is enabled.
Faster feature engineering with Photon
The Databricks Feature Engineering library has implemented a new version of point-in-time join for time series data. The new implementation, which was inspired by a suggestion from Semyon Sinchenko of Databricks customer Raiffeisen Bank International, uses native Spark instead of the Tempo library, making it more scalable and robust than the previous version. Moreover, the native Spark implementation hugely benefits from the Photon Engine. The larger the tables, the more improvements Photon can bring.
- When joining a feature table of 10M rows (10k unique IDs, with 1000 timestamps per ID) with a label table (100k unique IDs, with 100 timestamps per ID), Photon speeds up the point-in-time join by 2.0x
- When joining a feature table of 100M rows (100k unique IDs), Photon speeds up the point-in-time join by 2.1x
- When joining a feature table of 1B rows (1M unique IDs), Photon speeds up the point-in-time join by 2.4x
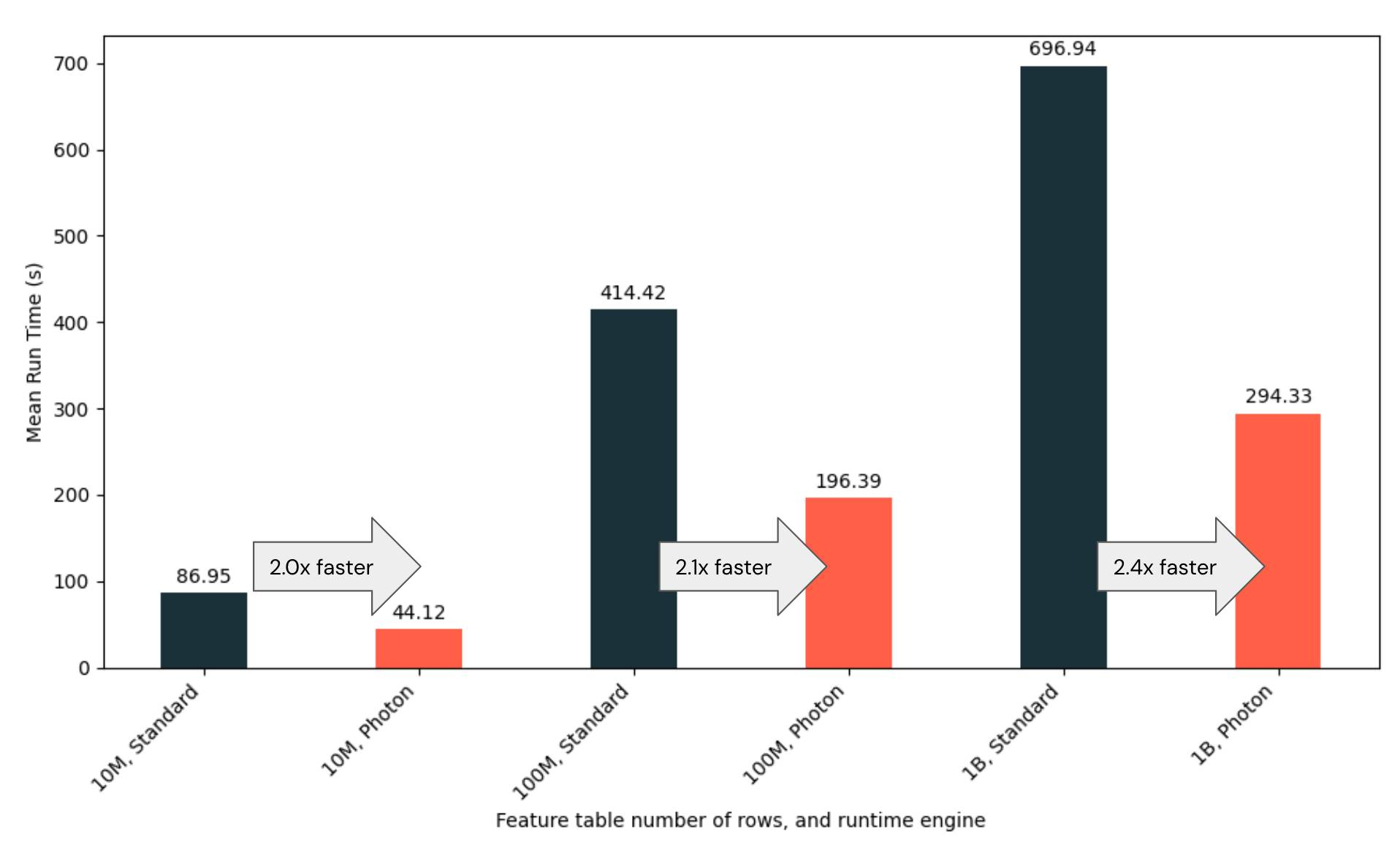
The figure above compares the run time of joining feature tables of 3 different sizes with the same label table. Each experiment was performed on a Databricks AWS cluster with an r6id.xlarge instance type and one worker node. The setup was repeated five times to calculate the average run time.
Select Photon in Databricks Machine Learning Runtime cluster
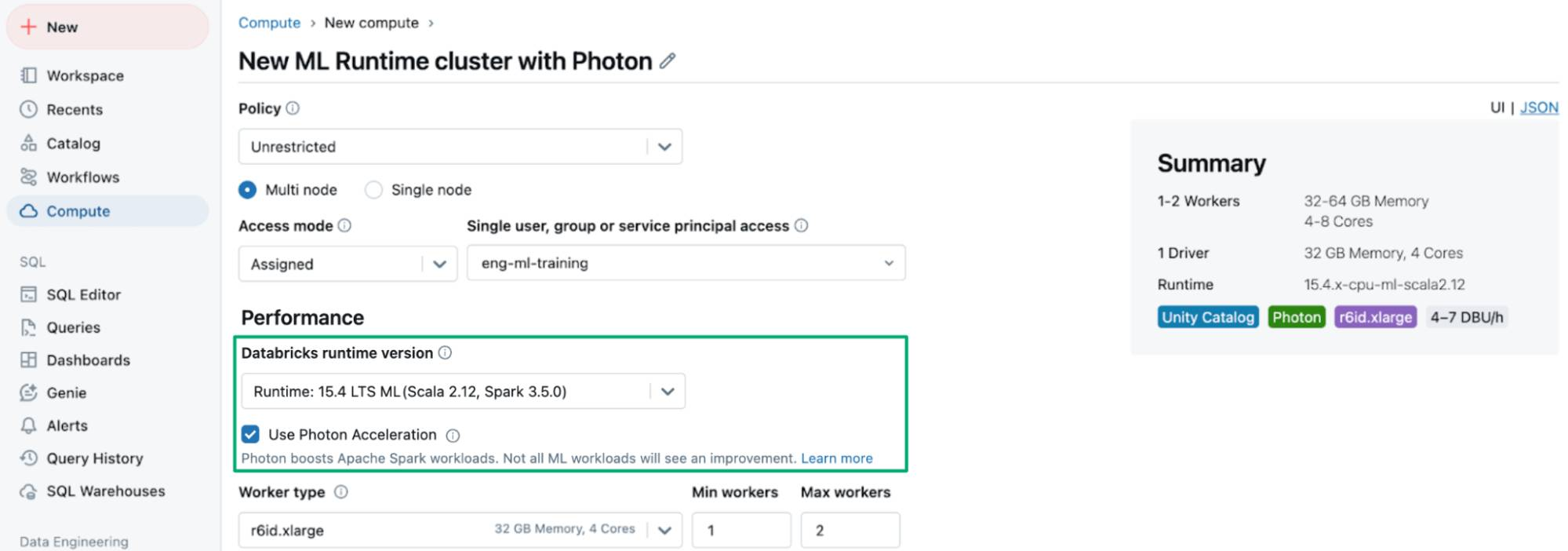
The query performance of Photon and the pre-built AI infrastructure of Databricks ML Runtime make it faster and easier to build machine learning models. Starting from Databricks Machine Learning Runtime 15.2 and above, users can create an ML Runtime cluster with Photon by selecting “Use Photon Acceleration”. Meanwhile, the native Spark version of point-in-time join comes with ML Runtime 15.4 LTS and above.
To learn more about Photon and feature engineering with Databricks, consult the following documentation pages for more information.