
包阅导读总结
1. 大库大表治理、MySQL数据库、磁盘空间、QPS、慢SQL
2.
总结:本文主要讲述了部门核心应用依赖的 MySQL 数据库因高水位运行需治理,包括数据库的基本情况、存在问题,如机器老化、磁盘空间紧张、大表问题、QPS 分布不均和慢 SQL 等,并提出了治理目标和具体方案,如大表数据结转、拦截无参数查询、查询切从库等。
3.
主要内容:
– 背景
– 部门核心应用的 MySQL 数据库高水位运行,大促前需治理。
– 基本情况
– 一主两从架构,机器老化过保,从库存在风险。
– 各库硬件资源、版本等信息。
– 磁盘空间占用高。
– 存在大表,数据糅合。
– 主库 QPS 远大于从库,慢 SQL 偶发。
– 治理目标
– 对大表集中结转,常态化按天结转。
– 主库高频查询切从库,降低主库 QPS。
– 优化慢 SQL 情况。
– 治理方案
– 大表数据结转,不同类型采取不同方式。
– 拦截无参数查询,dao 层用插件机制拒绝。
– 利用 JSF 和 UMP 统计接口调用量,将高频查询切从库。
思维导图: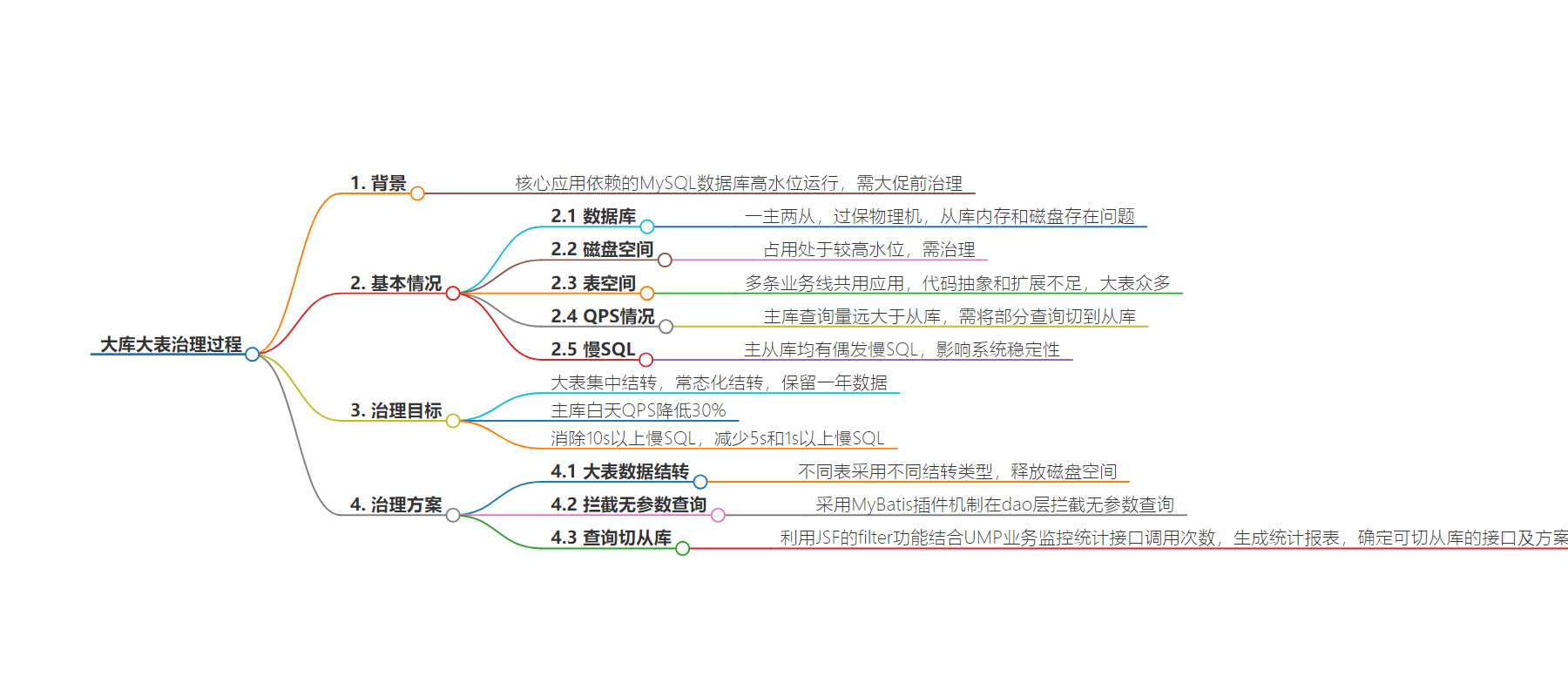
文章地址:https://mp.weixin.qq.com/s/tr63TaHgL90HFVWcTcLNFA
文章来源:mp.weixin.qq.com
作者:京东物流??林群
发布时间:2024/7/26 10:48
语言:中文
总字数:4843字
预计阅读时间:20分钟
评分:84分
标签:数据库治理,MySQL优化,高负载处理,京东技术,大表数据结转
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

背景
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
部门中一核心应用,因为各种原因其依赖的MySQL数据库一直处于高水位运行,无论是硬件资源,还是磁盘使用率或者QPS等都处于较高水位,急需在大促前完成对应的治理,降低各项指标,以保障在大促期间平稳运行,以期更好的支撑前端业务。
基本情况
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
背景
部门中一核心应用,因为各种原因其依赖的MySQL数据库一直处于高水位运行,无论是硬件资源,还是磁盘使用率或者QPS等都处于较高水位,急需在大促前完成对应的治理,降低各项指标,以保障在大促期间平稳运行,以期更好的支撑前端业务。
基本情况
2.1 数据库
| 域名 | 主/从 | CPU | 内存 | 容量 | DISK(/export)使用率(%) | Memory使用率(%) | 数据库版本 | |
| 1x.x.x.36 | xxx_m.mysql.jddb.com | 主 | 64 | 256G | 16T | 66.3% | 87.7% | 5.5.14 |
| 1x.x.x.73 | xxx_sb.mysql.jddb.com | 从 | 64 | 256G | 16T | 66.6% | 85.2% | 5.5.14 |
| 1x.x.x.135 | xxx_sa.mysql.jddb.com | 从 | 64 | 128G | 128T | 76.5% | 57.2% | 5.5.14 |
2.2 磁盘空间
截止到2月底,各数据库磁盘空间占用情况如下:
| IP | 主从 | 使用大小(G) | 已用比例(%) | 剩余空间(G) | 周增长量(G) | 预计报警(d) | 预计可用(d) | binlog(G) | 日志(G) |
| 1x.x.x.36 | M | 5017 | 69 | 2151 | 9 | 617.1 | 1735.8 | 159.45543 | 6 |
| 1x.x.x.73 | S | 5017 | 71 | 2151 | 14.8 | 333.2 | 1012.7 | 158.52228 | 1 |
| 1x.x.x.135 | S | 5017 | 4 | 129000 | 14.4 | 2986 | 8958 | 158.13548 | 0 |
从上表咱们可以看出,各数据库的磁盘空间占用已处于较高水位,急需需要治理,通过结转或删除数据来降低磁盘占用比例。
2.3 表空间
数据库存在大表其中一个原因是多条业务线共用一个应用,同时代码层面抽象的部分不够抽象,扩展部分又不容易扩展,导致数据都糅合和一起。
2.4 QPS情况
黄色的为主库的QPS,可以看出主库的查询量远大于从库,由于各种原因,应用代码里只有少部分的查询是走的从库,急需将部分流量大的查询接口从主库切到从库去查询。
2.5 慢SQL
不论是主库还是从库,都有偶发的慢SQL查询,引发磁盘繁忙,影响系统稳定性。
治理目标
4.1 大表数据结转
| 表名 | 表空间GB | 索引空间GB | 大数据 | 结转类型 | 开始值 | 完成值 |
| xxx_status | 991.65 | 265.29 | 是 | 删除 | 2020-04-30 01:00:00 | 2022-01-01 |
| xxx_main | 611.80 | 149.91 | 是 | 结转 | 2021-09-30 | 2022-01-01 |
| xxx_exception | 382.80 | 24.65 | 否 | 删除 | 2018-05-16 20:30:04 | 2022-01-01 |
| xxx_product_code | 244.18 | 61.54 | 是 | 删除 | 23亿 | |
| xxx_item | 208.66 | 85.46 | 是 | 结转 | 2016-12-29 13:20:33 | 2022-01-01 |
| xxx_freights_info | 128.78 | 109.03 | 是 | 结转 | 2018-11-29 13:26:00 | |
| xxx_extend | 127.36 | 26.07 | 是 | 结转 | 2019-03-29 14:30:00 | 2022-01-01 |
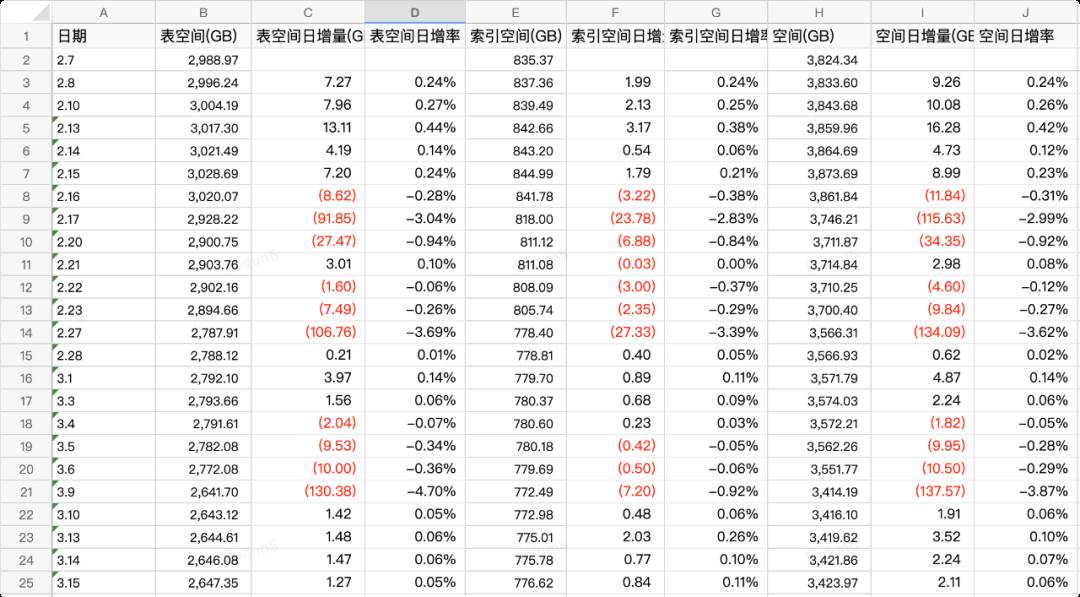 PS:红色数字部分为负值,也就是磁盘的释放空间。
PS:红色数字部分为负值,也就是磁盘的释放空间。
4.2 拦截无参数查询
mybatis-config.xml里的plugin配置:

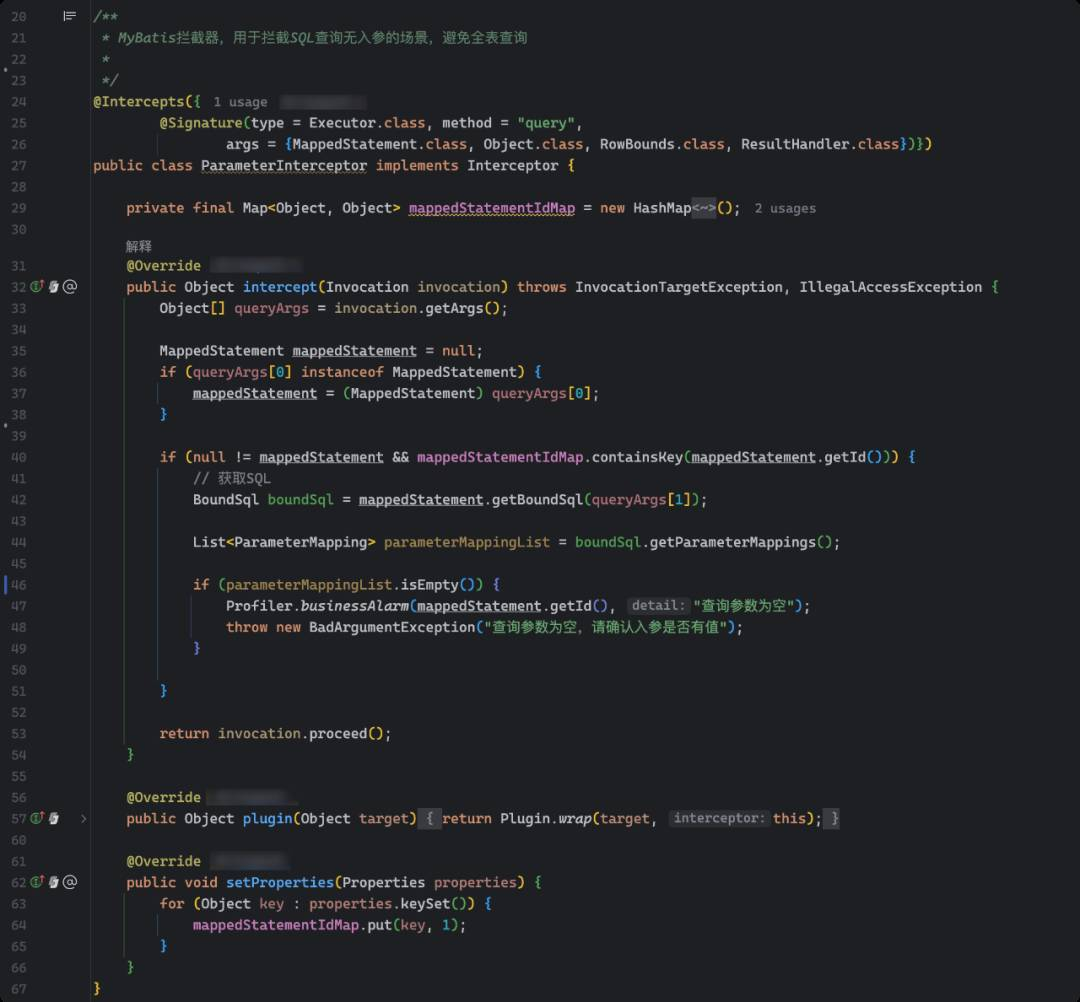
import org.apache.ibatis.executor.Executor;import org.apache.ibatis.mapping.BoundSql;import org.apache.ibatis.mapping.MappedStatement;import org.apache.ibatis.mapping.ParameterMapping;import org.apache.ibatis.plugin.*;import org.apache.ibatis.session.ResultHandler;import org.apache.ibatis.session.RowBounds;import java.lang.reflect.InvocationTargetException;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.Properties;@Intercepts({@Signature(type = Executor.class, method = "query",args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})})public class ParameterInterceptor implements Interceptor {private final Map<Object, Object> mappedStatementIdMap = new HashMap<Object, Object>();@Overridepublic Object intercept(Invocation invocation) throws InvocationTargetException, IllegalAccessException {Object[] queryArgs = invocation.getArgs();MappedStatement mappedStatement = null;if (queryArgs[0] instanceof MappedStatement) {mappedStatement = (MappedStatement) queryArgs[0];}if (null != mappedStatement && mappedStatementIdMap.containsKey(mappedStatement.getId())) {BoundSql boundSql = mappedStatement.getBoundSql(queryArgs[1]);List<ParameterMapping> parameterMappingList = boundSql.getParameterMappings();if (parameterMappingList.isEmpty()) {Profiler.businessAlarm(mappedStatement.getId(), "查询参数为空");throw new BadArgumentException("查询参数为空,请确认入参是否有值");}}return invocation.proceed();}@Overridepublic Object plugin(Object target) {return Plugin.wrap(target, this);}@Overridepublic void setProperties(Properties properties) {for (Object key : properties.keySet()) {mappedStatementIdMap.put(key, 1);}}}
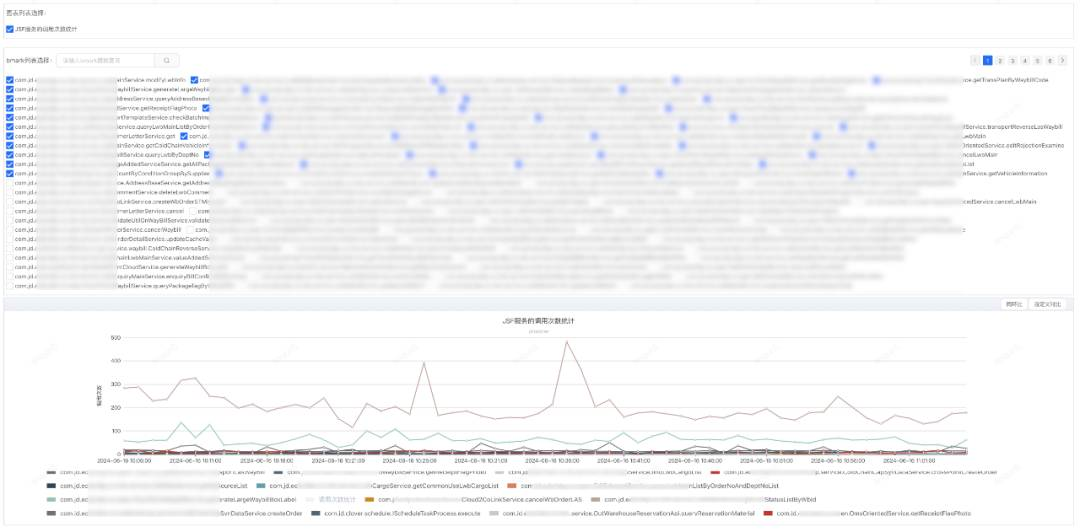
4.3 查询切从库
JSF的配置文件新增filter
<jsf:filterid="callFilter"ref="jsfInvokeFilter"/>import com.jd.jsf.gd.filter.AbstractFilter;import com.jd.jsf.gd.msg.RequestMessage;import com.jd.jsf.gd.msg.ResponseMessage;import com.jd.jsf.gd.util.RpcContext;import com.jd.ump.profiler.proxy.Profiler;import org.springframework.stereotype.Component;import java.util.HashMap;import java.util.Map;@Componentpublic class JsfInvokeFilter extends AbstractFilter {private static final String API_PROVIDER_METHOD_COUNT_KEY = "api.jsf.provider.method.count.key";private static final String API_CONSUMER_METHOD_COUNT_KEY = "api.jsf.consumer.method.count.key";@Overridepublic ResponseMessage invoke(RequestMessage requestMessage) {String key;if (RpcContext.getContext().isProviderSide()) {key = API_PROVIDER_METHOD_COUNT_KEY;} else {key = API_CONSUMER_METHOD_COUNT_KEY;}String method = requestMessage.getClassName() + "." + requestMessage.getMethodName();Map<String, String> tags = new HashMap<String, String>(2);tags.put("bMark", method);tags.put("bCount", "1");Profiler.sourceDataByStr(key, tags);return getNext().invoke(requestMessage);}}
明细项
import osimport openpyxlimport jsonimport requestsfrom cookies import Cookieimport timeheaders = {'Cookie': Cookie,'Content-Type': 'application/json','token': '******','erp': '******'}def get_jsf(start_time, end_time):url = 'http://xxx.taishan.jd.com/api/xxx/xxx/xxx/'body = {}params = {'startTime': start_time,'endTime': end_time,'endPointKey': 'api.jsf.provider.method.count.key','quickTime': int((end_time - start_time) / 1000),'markFlag': 'true','markLimit': 500}res = requests.post(url=url, data=json.dumps(body), params=params, headers=headers)print('url: ', res.request.url)res_json = json.loads(res.text)title = ['序号', 'jsf key', '次数', '占比%', '峰值', '次/秒', '峰值时间']i = 0keys = {}marks = res_json['response_data']['marks']for mark in marks:keys.setdefault(mark, [0, 0, 0, ''])data = []records = res_json['response_data']['monitorData']print(len(records))for key, value in records.items():count = 0max_val = 0max_time = ''for val in value:v = val['value']count += vif v > max_val:max_val = vmax_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(int(val['dateTime'] / 1000)))keys[key] = [count, max_val, int(max_val / 1200), max_time]key_list = sorted(keys.items(), key=lambda x: x[1], reverse=True)all_count = key_list[0][1][0]for key in key_list:values = [i, key[0], key[1][0], str(round(key[1][0] / all_count * 100, 2)) + '%', key[1][1], key[1][2], key[1][3]]data.append(values)i += 1path = r"/Users/xxx/Documents/治理/QPS治理/"os.chdir(path)workbook = openpyxl.Workbook()sheet = workbook.activesheet.title = 'JSF接口调用次数统计'sheet.append(title)for record in data:sheet.append(record)workbook.save('JSF接口调用次数统计-' + str(start_time / 1000) + '-' + str(end_time / 1000) + '.xlsx')def change_time(dt):time_array = time.strptime(dt, "%Y-%m-%d %H:%M:%S")timestamp = time.mktime(time_array)return int(timestamp * 1000)if __name__ == '__main__':start_time = '2024-03-06 12:20:00'end_time = '2024-03-07 12:20:00'get_jsf(change_time(start_time), change_time(end_time))
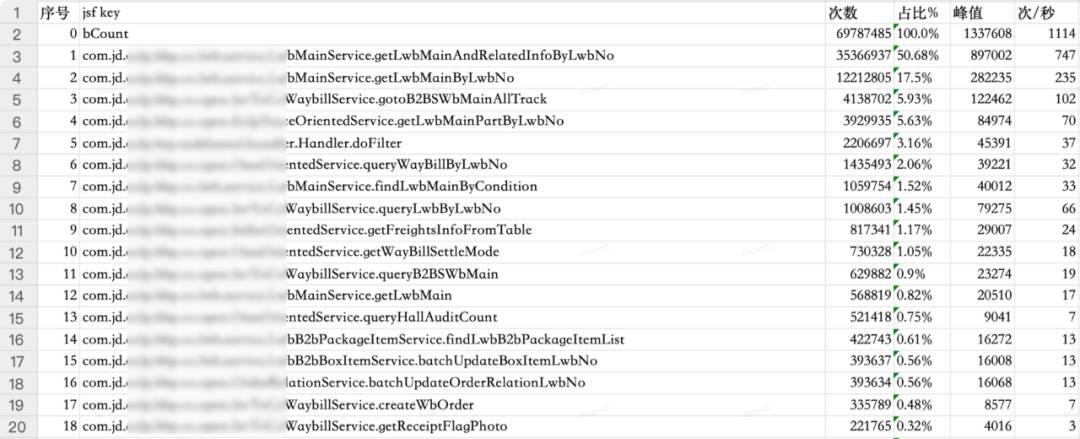
| 接口 | 日调用量 | 占比% | 次/秒 | 涉及到的表 | 是否可以切从库 | 切从库方案 | |
| 0 | 总调用量 | 69787485 | 100.0% | 1114 | |||
| 1 | com.jd.xxx.service.xxx.getLwbMainAndRelatedInfoByLwbNo | 35366937 | 50.68% | 747 | lxxx_mainxxx_goods_itemextend_infoxxx_extend | 是 | 单查询,在Service层加注解走从库查询 |
| 2 | com.jd.xxx.service.xxx.getLwbMainByLwbNo | 12212805 | 17.5% | 235 | xxx_mainxxx_main_ext_coldchainxxx_product_codexxx_extend | 是 | 有很多地方引用这个方法,切从库需要新增API接口,在Service新增的方法上加走从库注解 |
| 3 | com.jd.xxx.open.xxx.getLwbMainPartByLwbNo | 4138702 | 5.93% | 102 | xxx_main | 是 | 在Service层加注解走从库查询 |
| 4 | com.jd.xxx.open.xxx.gotoB2BSWbMainAllTrack | 3929935 | 5.63% | 70 | xxx_main 两次xxx_main_ext_coldchain | 是 | 在Service层加注解走从库查询 |
| 5 | com.jd.xxx.btp.taskfunnel.handler.Handler.doFilter | 2206697 | 3.16% | 37 | 否 | 接单框架(实现方法太多) | |
| 6 | com.jd.xxx.service.xxx.findLwbMainByCondition | 1435493 | 2.06% | 32 | xxx_main 列表查询xxx_item 是否查明细package_added_servicepackage_added_service_item 取旧服务xxx_pay_mainxxx_extendxxx_product_codexxx_main_ext_coldchain | 是 | 有很多地方引用这个方法,切从库需要新增API接口,在Service新增的方法上加走从库注解 |
| 7 | com.jd.xxx.open.OmsOrientedService.queryWayBillByLwbNo | 1059754 | 1.52% | 33 | xxx_mainfreights_infoxxx_enquiry_mainxxx_status 两次xxx_b2b_box_itemxxx_coupon 两次xxx_extend 积分 | 是 | 在Service层加注解走从库查询 |
| 8 | com.jd.xxx.open.SellerOrientedService.getFreightsInfoFromTable | 1008603 | 1.45% | 66 | xxx_mainxxx_b2b_packagexxx_extendxxx_product_codexxx_main_ext_coldchainxxx_main_ext_sitefreights_infofee_detailxxx_b2b_box_item | 是 | 在Service层加注解走从库查询 |
| 9 | com.jd.xxx.service.xxx.getLwbMain | 817341 | 1.17% | 24 | xxx_mainxxx_b2b_packagexxx_extendxxx_product_codexxx_main_ext_coldchainxxx_main_ext_site | 是 | 有很多地方引用这个方法,切从库需要新增API接口,在Service新增的方法上加走从库注解 |
| 10 | com.jd.xxx.open.OmsOrientedService.getWayBillSettleMode | 730328 | 1.05% | 18 | 无数据库查询 |
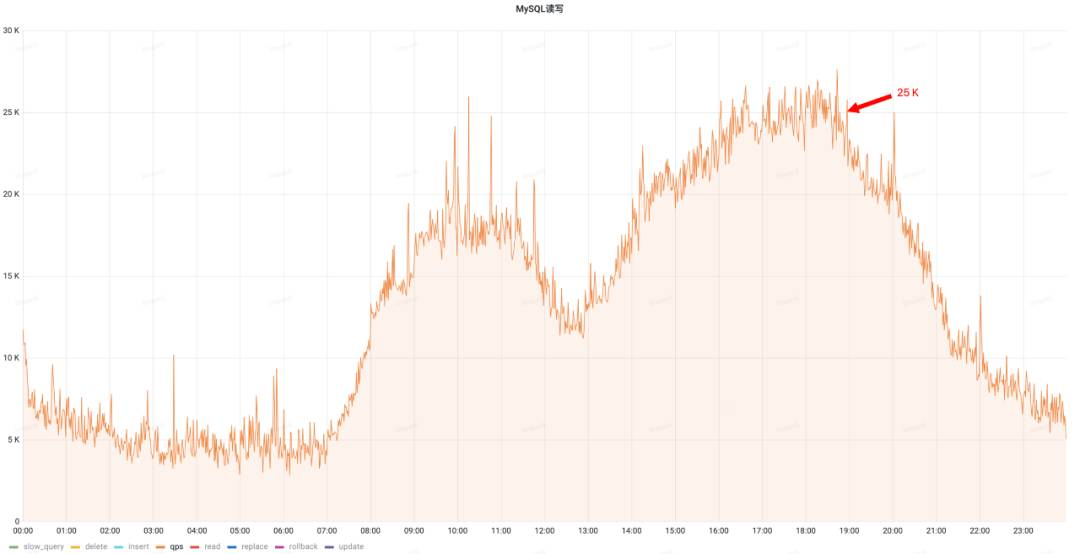 治理前QPS(峰值25k)
治理前QPS(峰值25k)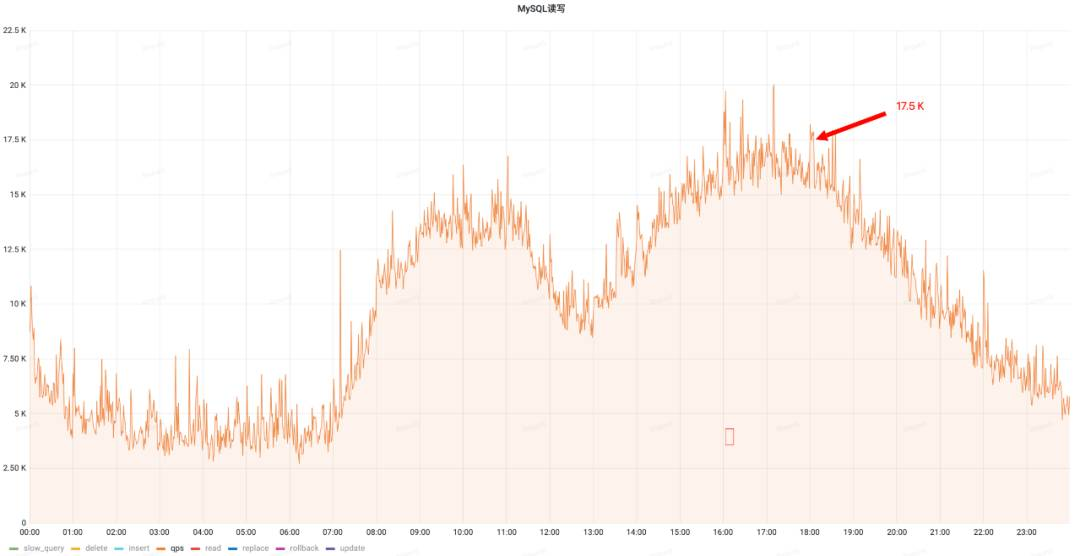 治理后QPS(峰值17.5k)
治理后QPS(峰值17.5k)
4.4 慢SQL治理
写在最后
探讨
▪功能支撑:会员成长体系、等级计算策略、权益体系、营销底层能力支持
▪用户活跃:会员关怀、用户触达、活跃活动、业务线交叉获客、拉新促活