
包阅导读总结
1. 关键词:TreeUtil、树形结构、工具类、阿里大神、代码分析
2. 总结:作者介绍了阿里大神写的TreeUtil工具类,对其进行深入分析,包括树形结构的介绍、在 Java 中的应用、TreeUtil 代码分析及方法拆解,还提到了树的遍历、打平、排序等操作。
3. 主要内容:
– 引言
– 作者在 CR 时看到阿里同事写的树操作工具类,进行分析整理分享
– 树形结构介绍
– 简单的二叉树
– 树的应用场景
– JAVA 中的树形数据结构
– JAVA 树形结构对象定义
– JSON 数据格式中的树形结构
– 树形数据结构的储存
– TreeUtil 代码分析
– makeTree()构建树及使用示例
– 神方法拆解
– 其它操作 Tree 方法
– 遍历 Tree
– flat 打平树
– sort()排序
思维导图: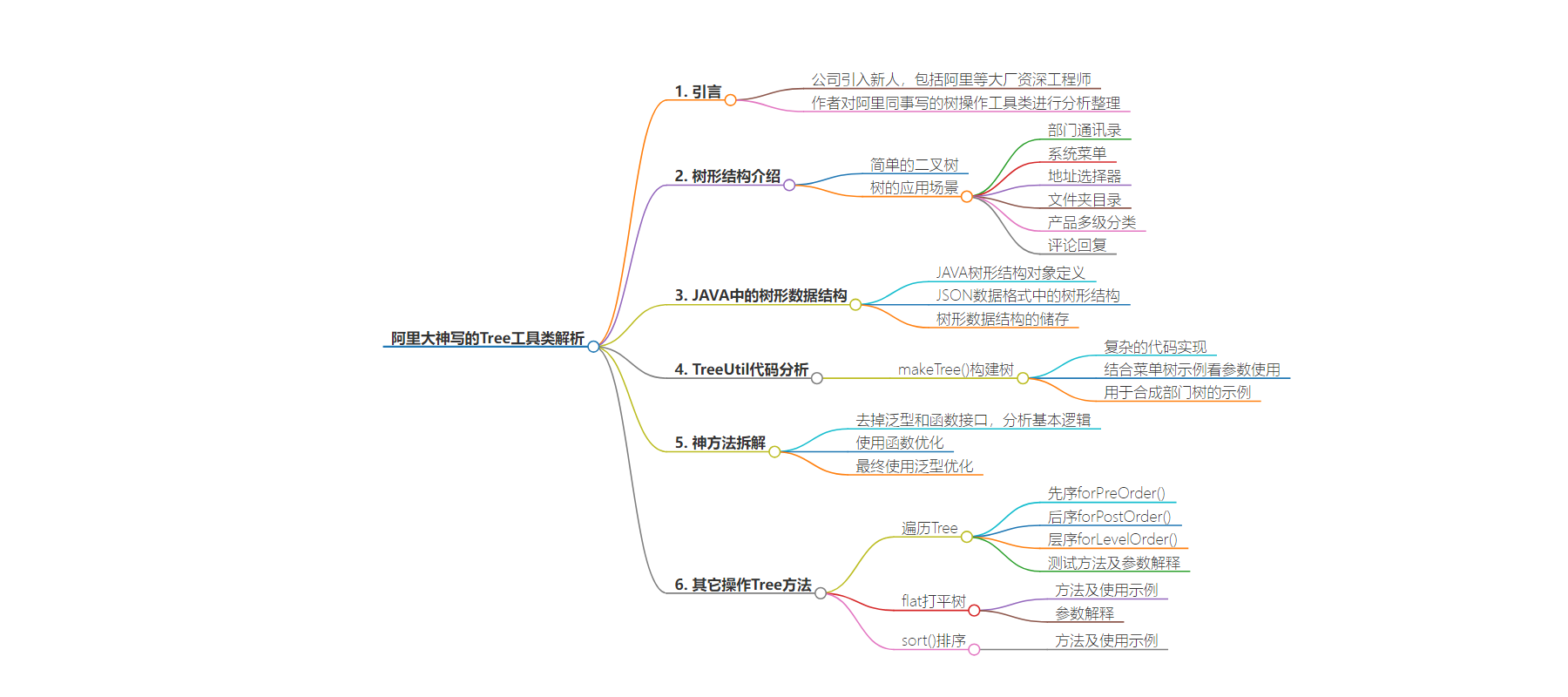
文章地址:https://juejin.cn/post/7395902224218488869
文章来源:juejin.cn
作者:赵侠客
发布时间:2024/7/27 14:30
语言:中文
总字数:4648字
预计阅读时间:19分钟
评分:85分
标签:Java,树形数据结构,工具类,算法,数据结构
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
首发公众号:赵侠客
一、引言
最近公司新进了不少新人,包括一些来自阿里、网易等大型企业的资深工程师。我们组的一位新同事是阿里来的专家,我在CR(Code Review, 简称CR)时看到了他编写的一个关于树操作的工具类,对其设计和实现深感佩服。为了进一步理解和学习,我对这个工具类进行了深入分析和整理,现在在本文中与大家分享。
二、树形结构介绍
2.1 简单的二叉树
首页简单简介一下树形数据结构,树形数据结构是一种层级化的数据组织方式,广泛用于表示具有层次关系的数据。由于其层级化组织特点,树形数据结构能够高效支持多种查找、插入和删除操作,因此在计算机科学和实际应用中得到了广泛应用。下面是一个简单的二叉树示例:
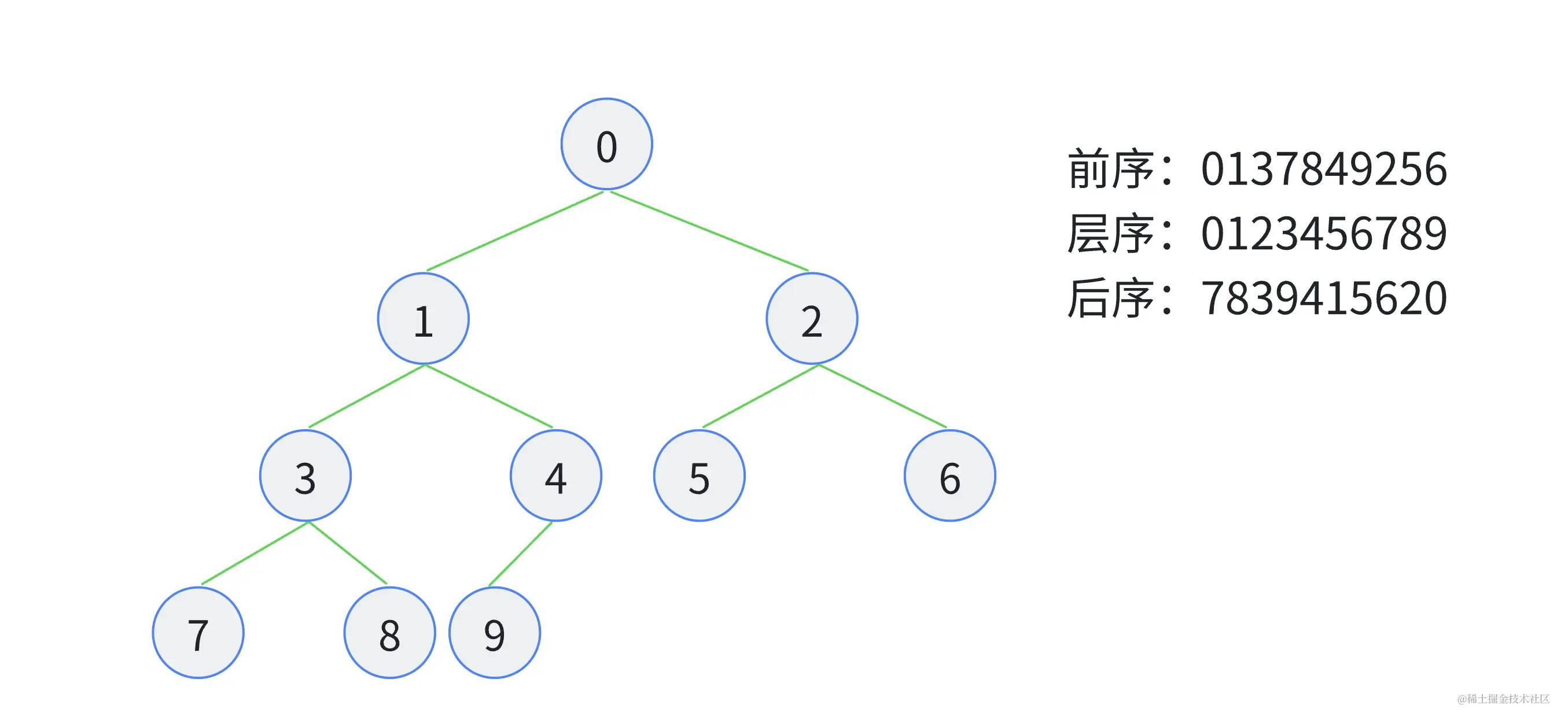
▲二叉树及遍历算法
2.2 树的应用场景
树形数据结构的应用场景是通过ID关联上下级关系的对象,然后将这些对象组织成一棵树。主要有以下常用应用场景:
- 部门通讯录:通讯录中可以通过树形结构展示不同部门及其上下级关系,便于用户快速找到联系人
- 系统菜单: 系统中的菜单通常是分层的,通过树形结构可以方便地展示和管理各级菜单项
- 地址选择器:地理地址通常有多级关系,如省、市、县,通过树形结构可以方便用户选择具体的地址
- 文件夹目录: 文件系统中的文件夹和文件可以通过树形结构来组织和展示,便于用户进行文件操作
- 产品多级分类: 通过树形结构可以直观地展示和管理各级分类
- 评论回复: 通过树形结构可以展示帖子的回复关系,便于查看讨论的脉络
树形数据结构的应用场景通常是分层的,通过树形结构可以展示和管理各级流程节点及其关系。 这些场景中,树形结构的应用可以显著提升数据的组织和展示效率,帮助用户更直观地理解和操作系统。

▲:树形结构在电商分类中的应用
三、JAVA中的树形数据结构
3.1 JAVA树形结构对象定义
在JAVA中树形结构是通过对象嵌套方式来定义的,如MenuVo对象中有一个子对象subMenus:
@Datapublic class MenuVo { private Long id; private Long pId; private String name; private Integer rank=0; private List<MenuVo> subMenus=new ArrayList<>();}3.2 JSON数据格式中的树形结构
JSON数据天然就是树形结果,如以下展示一个简单的JSON树形结构:
[ { "id": 0, "subMenus": [ { "id": 2, "subMenus": [ { "id": 5, "pid": 2 } ], "pid": 0 } ], "pid": -1 }]3.3 树形数据结构的储存
像文档型数据库MongDB、ElasticSearch可以直接存储JSON这种树形数据,而像Mysql这种关系型数据库不太适合直接存储具有上下级关系的树形数据,大都是按行存储然后通过id、pid之间关联上下级关系,这就导致我们需要经常将Mysql中的关系型数据转成JSON这种数据结构,因而TreeUtil这类数据转换工具类就起诞生了。
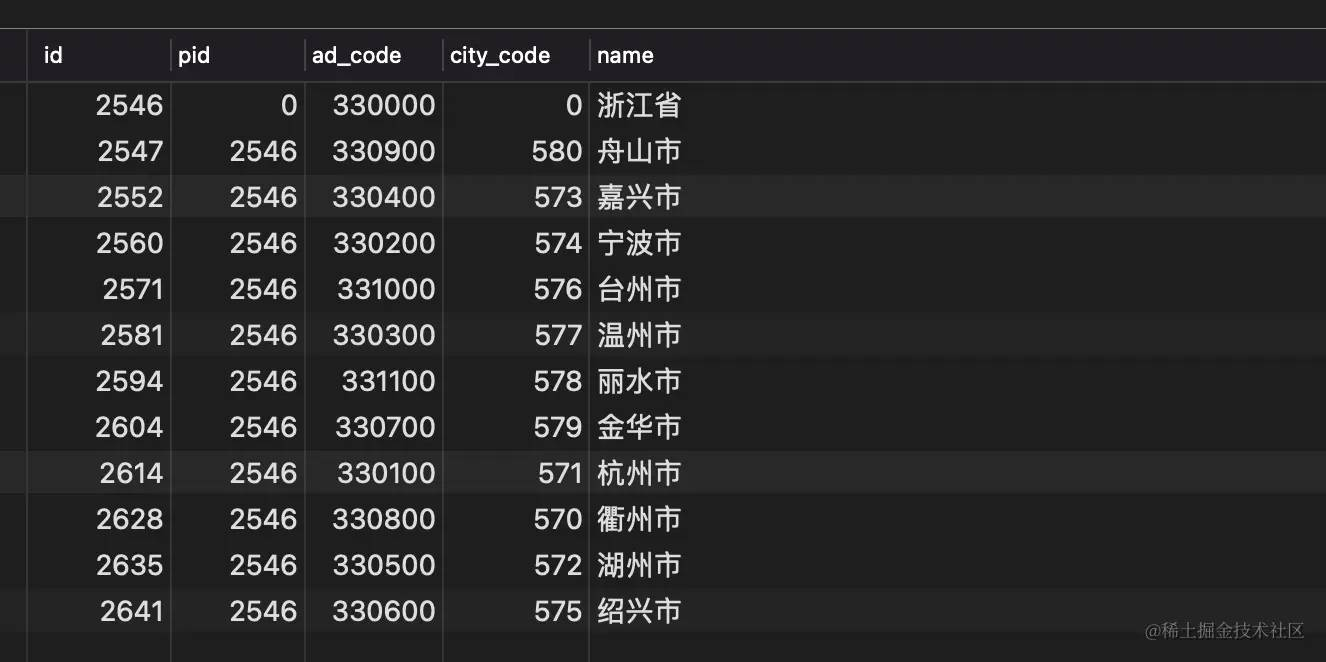
▲:数据库中存储的城市数据结构
四、TreeUtil代码分析
4.1 makeTree()构建树
直接看这神一样的方法makeTree():
public class TreeUtil { public static <E> List<E> makeTree(List<E> list, Predicate<E> rootCheck, BiFunction<E, E, Boolean> parentCheck, BiConsumer<E, List<E>> setSubChildren) { return list.stream().filter(rootCheck).peek(x -> setSubChildren.accept(x, makeChildren(x, list, parentCheck, setSubChildren))).collect(Collectors.toList()); } private static <E> List<E> makeChildren(E parent, List<E> allData, BiFunction<E, E, Boolean> parentCheck, BiConsumer<E, List<E>> setSubChildren) { return allData.stream().filter(x -> parentCheck.apply(parent, x)).peek(x -> setSubChildren.accept(x, makeChildren(x, allData, parentCheck, setSubChildren))).collect(Collectors.toList()); }}是不是完全看不懂?像看天书一样?makeTree方法为了通用使用了泛型+函数式编程+递归,正常人一眼根本看不这是在干什么的,我们先不用管这个makeTree合成树的代码原理,先直接看如何使用:
MenuVo menu0 = new MenuVo(0L, -1L);MenuVo menu1 = new MenuVo(1L, 0L);MenuVo menu2 = new MenuVo(2L, 0L);MenuVo menu3 = new MenuVo(3L, 1L);MenuVo menu4 = new MenuVo(4L, 1L);MenuVo menu5 = new MenuVo(5L, 2L);MenuVo menu6 = new MenuVo(6L, 2L);MenuVo menu7 = new MenuVo(7L, 3L);MenuVo menu8 = new MenuVo(8L, 3L);MenuVo menu9 = new MenuVo(9L, 4L);List<MenuVo> menuList = Arrays.asList(menu0,menu1, menu2,menu3,menu4,menu5,menu6,menu7,menu8,menu9);List<MenuVo> tree= TreeUtil.makeTree(menuList, x->x.getPId()==-1L,(x, y)->x.getId().equals(y.getPId()), MenuVo::setSubMenus);System.out.println(JsonUtils.toJson(tree));我们结合这个简单的合成菜单树看一下这个makeTree()方法参数是如何使用的:
- 第1个参数List list,为我们需要合成树的List,如上面Demo中的menuList
- 第2个参数Predicate rootCheck,判断为根节点的条件,如上面Demo中pId==-1就是根节点
- 第3个参数parentCheck 判断为父节点条件,如上面Demo中 id==pId
- 第4个参数setSubChildren,设置下级数据方法,如上面Demo中: Menu::setSubMenus
有了上面这4个参数,只要是合成树场景,这个TreeUtil.makeTree()都可以适用,比如我们要合成一个部门树:
@Datapublic class GroupVO { private String groupId; private String parentGroupId; private String groupName; private List<GroupVO> subGroups=new ArrayList<>();}groupId是部门ID, 根部门的条件是parentGroupId=null, 那么调用合成树的方法为:
List<GroupVO> groupTree=TreeUtil.makeTree(groupList, x->x.getParentGroupId==null,(x, y)->x.getGroupId().equals(y.getParentGroupId), GroupVO::setSubGroups);是不是很优雅?很通用?完全不需要实现什么接口、定义什么TreeNode、增加什么TreeConfig,静态方法直接调用就搞定。 一个字:绝!
五、神方法拆解
5.1 去掉泛型和函数接口
第一步我们可以把泛型和函数接口去掉,再看一下一个如何使用递归合成树:
public static List<MenuVo> makeTree(List<MenuVo> allDate,Long rootParentId) { List<MenuVo> roots = new ArrayList<>(); for (MenuVo menu : allDate) { if (Objects.equals(rootParentId, menu.getPId())) { roots.add(menu); } } for (MenuVo root : roots) { makeChildren(root, allDate); } return roots; } public static MenuVo makeChildren(MenuVo root, List<MenuVo> allDate) { for (MenuVo menu : allDate) { if (Objects.equals(root.getId(), menu.getPId())) { makeChildren(menu, allDate); root.getSubMenus().add(menu); } } return root; }调用方法:
List<MenuVo> tree2 = parseTree(menuList,-1L);通过上面的两个方法可以合成树的基本逻辑,主要分为三步
- 找到所有根节点
- 遍历所有根节点设置子节点
- 遍历allDate查询子节点
5.2 使用函数优化
看懂上面的代码后,我们再给加上函数式接口:
public static List<MenuVo> makeTree(List<MenuVo> allDate, Predicate<MenuVo> rootCheck, BiFunction<MenuVo, MenuVo, Boolean> parentCheck, BiConsumer<MenuVo, List<MenuVo>> setSubChildren) { List<MenuVo> roots = allDate.stream().filter(x->rootCheck.test(x)).collect(Collectors.toList());; roots.stream().forEach(x->makeChildren(x,allDate,parentCheck,setSubChildren)); return roots; } public static MenuVo makeChildren(MenuVo root, List<MenuVo> allDate,BiFunction<MenuVo, MenuVo, Boolean> parentCheck, BiConsumer<MenuVo, List<MenuVo>> setSubChildren) { allDate.stream().filter(x->parentCheck.apply(root,x)).forEach(x->{ makeChildren(x, allDate,parentCheck,setSubChildren); setSubChildren.accept(x,allDate); }); return root; }结合前面的方式再来看这个函数式接口是不是简单多了,只是写法上函数化了而已。使用函数优化的整体结构和最终的方法有点像了,最后再使用泛型优化就成了最终版本。从这个例子来看代码还是要不断优化的,大神可以直接写出神一样的代码,小弟一步步优化,一点点进步也是能写出大神一样的代码的。
六、其它操作Tree方法
6.1 遍历Tree
学习过二叉树都知道遍历二叉树有先序、中序、后序、层序,如果这些不清楚的可以先去学习一下,针对Tree的遍历这里提供了三个方法: 先序forPreOrder(),后序forPostOrder(),层序forLevelOrder():
public static <E> void forPreOrder(List<E> tree, Consumer<E> consumer, Function<E, List<E>> getSubChildren) { for (E l : tree) { consumer.accept(l); List<E> es = getSubChildren.apply(l); if (es != null && es.size() > 0) { forPreOrder(es, consumer, getSubChildren); } }}public static <E> void forLevelOrder(List<E> tree, Consumer<E> consumer, Function<E, List<E>> getSubChildren) { Queue<E> queue = new LinkedList<>(tree); while (!queue.isEmpty()) { E item = queue.poll(); consumer.accept(item); List<E> childList = getSubChildren.apply(item); if (childList != null && !childList.isEmpty()) { queue.addAll(childList); } }}public static <E> void forPostOrder(List<E> tree, Consumer<E> consumer, Function<E, List<E>> getSubChildren) { for (E item : tree) { List<E> childList = getSubChildren.apply(item); if (childList != null && !childList.isEmpty()) { forPostOrder(childList, consumer, getSubChildren); } consumer.accept(item); }} 我们看测试方法:
StringBuffer preStr=new StringBuffer();TreeUtil.forPreOrder(tree,x-> preStr.append(x.getId().toString()),Menu::getSubMenus);Assert.assertEquals("0137849256",preStr.toString());StringBuffer levelStr=new StringBuffer();TreeUtil.forLevelOrder(tree,x-> levelStr.append(x.getId().toString()),Menu::getSubMenus);Assert.assertEquals("0123456789",levelStr.toString());StringBuffer postOrder=new StringBuffer();TreeUtil.forPostOrder(tree,x-> postOrder.append(x.getId().toString()),Menu::getSubMenus);Assert.assertEquals("7839415620",postOrder.toString());通过这个Demo我们解释一下遍历中的几个参数:
- tree 需要遍历的树,就是makeTree()合成的对象
- Consumer consumer 遍历后对单个元素的处理方法,如:x-> System.out.println(x)、 postOrder.append(x.getId().toString())
- Function<E, List> getSubChildren,获取下级数据方法,如Menu::getSubMenus
有了这三个方法遍历Tree是不是和遍历List一样简单方便了?二个字:绝了!!
6.2 flat打平树
我们可以将一个List使用markTree()构建成树,就可以使用flat()将树还原成List
public static <E> List<E> flat(List<E> tree, Function<E, List<E>> getSubChildren, Consumer<E> setSubChildren) { List<E> res = new ArrayList<>(); forPostOrder(tree, item -> { setSubChildren.accept(item); res.add(item); }, getSubChildren); return res; }使用方法:
List<Menu> flat = TreeUtil.flat(tree, Menu::getSubMenus,x->x.setSubMenus(null)); Assert.assertEquals(flat.size(),menuList.size()); flat.forEach(x->{ Assert.assertTrue(x.getSubMenus()==null); });flat()参数解释:
- tree 需要打平的树,就是makeTree()合成的对象
- Function<E, List> getSubChildren,获取下级数据方法,如Menu::getSubMenus
- Consumer setSubChildren,设置下级数据方法,如: x->x.setSubMenus(null)
6.3 sort()排查
我们知道针对List,可以使用list.sort()直接排序,那么针对树,就可以调用sort()方法直接对树中所有子节点直接排序:
public static <E> List<E> sort(List<E> tree, Comparator<? super E> comparator, Function<E, List<E>> getChildren) { for (E item : tree) { List<E> childList = getChildren.apply(item); if (childList != null && !childList.isEmpty()) { sort(childList,comparator,getChildren); } } tree.sort(comparator); return tree; }比如MenuVo有一个rank值,表明排序权重
MenuVo menu0 = new MenuVo(0L, -1L); MenuVo menu1 = new MenuVo(1L, 0L); menu1.setRank(100); MenuVo menu2 = new MenuVo(2L, 0L); menu2.setRank(1); MenuVo menu3 = new MenuVo(3L, 1L); MenuVo menu4 = new MenuVo(4L, 1L); MenuVo menu5 = new MenuVo(5L, 2L); menu5.setRank(5); MenuVo menu6 = new MenuVo(6L, 2L); MenuVo menu7 = new MenuVo(7L, 3L); menu7.setRank(5); MenuVo menu8 = new MenuVo(8L, 3L); menu8.setRank(1); MenuVo menu9 = new MenuVo(9L, 4L); List<MenuVo> menuList = Arrays.asList(menu0,menu1, menu2,menu3,menu4,menu5,menu6,menu7,menu8,menu9); List<MenuVo> tree= TreeUtil.makeTree(menuList, x->x.getPId()==-1L,(x, y)->x.getId().equals(y.getPId()), MenuVo::setSubMenus); System.out.println(JsonUtils.toJson(tree));如查我们想按rank正序:
List<MenuVo> sortTree= TreeUtil.sort(tree, Comparator.comparing(MenuVo::getRank), MenuVo::getSubMenus);如果我们想按rank倒序:
List<MenuVo> sortTree= TreeUtil.sort(tree, (x,y)->y.getRank().compareTo(x.getRank()), MenuVo::getSubMenus);sort参数解释:
- tree 需要排序的树,就是makeTree()合成的对象
- Comparator<? super E> comparator 排序规则Comparator,如:Comparator.comparing(MenuVo::getRank)按Rank正序 ,(x,y)->y.getRank().compareTo(x.getRank()),按Rank倒序
- Function<E, List> getChildren 获取下级数据方法,如:MenuVo::getSubMenus
这个给树排序是不是和对List排序一样的简单:三个字:太绝了!!!
七、总结
看完这位大神编写的TreeUtil工具类后,我深感佩服,其设计与实现真是令人叹为观止。该工具类不仅优雅且高效,使得以往需要递归处理的树形结构操作变得更加简洁和便捷。未来处理树形数据时,只需直接使用该工具类即可,无需再编写复杂的递归代码。
最后附完成代码方便CV工程师,还不赶快点赞、关注、收藏
public class TreeUtil { public static <E> List<E> makeTree(List<E> list, Predicate<E> rootCheck, BiFunction<E, E, Boolean> parentCheck, BiConsumer<E, List<E>> setSubChildren) { return list.stream().filter(rootCheck).peek(x -> setSubChildren.accept(x, makeChildren(x, list, parentCheck, setSubChildren))).collect(Collectors.toList()); } public static <E> List<E> flat(List<E> tree, Function<E, List<E>> getSubChildren, Consumer<E> setSubChildren) { List<E> res = new ArrayList<>(); forPostOrder(tree, item -> { setSubChildren.accept(item); res.add(item); }, getSubChildren); return res; } public static <E> void forPreOrder(List<E> tree, Consumer<E> consumer, Function<E, List<E>> setSubChildren) { for (E l : tree) { consumer.accept(l); List<E> es = setSubChildren.apply(l); if (es != null && es.size() > 0) { forPreOrder(es, consumer, setSubChildren); } } } public static <E> void forLevelOrder(List<E> tree, Consumer<E> consumer, Function<E, List<E>> setSubChildren) { Queue<E> queue = new LinkedList<>(tree); while (!queue.isEmpty()) { E item = queue.poll(); consumer.accept(item); List<E> childList = setSubChildren.apply(item); if (childList != null && !childList.isEmpty()) { queue.addAll(childList); } } } public static <E> void forPostOrder(List<E> tree, Consumer<E> consumer, Function<E, List<E>> setSubChildren) { for (E item : tree) { List<E> childList = setSubChildren.apply(item); if (childList != null && !childList.isEmpty()) { forPostOrder(childList, consumer, setSubChildren); } consumer.accept(item); } } public static <E> List<E> sort(List<E> tree, Comparator<? super E> comparator, Function<E, List<E>> getChildren) { for (E item : tree) { List<E> childList = getChildren.apply(item); if (childList != null && !childList.isEmpty()) { sort(childList,comparator,getChildren); } } tree.sort(comparator); return tree; } private static <E> List<E> makeChildren(E parent, List<E> allData, BiFunction<E, E, Boolean> parentCheck, BiConsumer<E, List<E>> children) { return allData.stream().filter(x -> parentCheck.apply(parent, x)).peek(x -> children.accept(x, makeChildren(x, allData, parentCheck, children))).collect(Collectors.toList()); }}