
包阅导读总结
1.
关键词:WorkQueue 、重构 、优化 、排序堆 、接口设计
2.
总结:作者分享了对 WorkQueue 项目的重构思路,指出 v1 版存在诸多问题,分析痛点后明确预期目标和思考顺序,最终通过重新设计排序堆、接口等实现优化。
3.
主要内容:
– WorkQueue 项目重构背景
– 随着用户增多,v1 版出现性能、设计、实现等问题。
– 其他业务组在处理延迟订单时出现顺序不准确等问题。
– 痛点分析
– 排序堆不稳定且性能差。
– 接口设计混乱。
– 功能不符合预期。
– 代码质量低。
– 架构设计混乱。
– 预期目标
– 排序堆稳定高效。
– 接口通用易用。
– 功能符合预期。
– 提升代码质量。
– 设计清晰架构。
– 思考过程
– 解决问题有顺序,先排序堆,再接口设计,接着功能问题,最后代码质量。
– 重构和优化
– 选择红黑树实现排序堆,使用链表避免内存碎片,利用 sync.Pool 提升性能。
思维导图: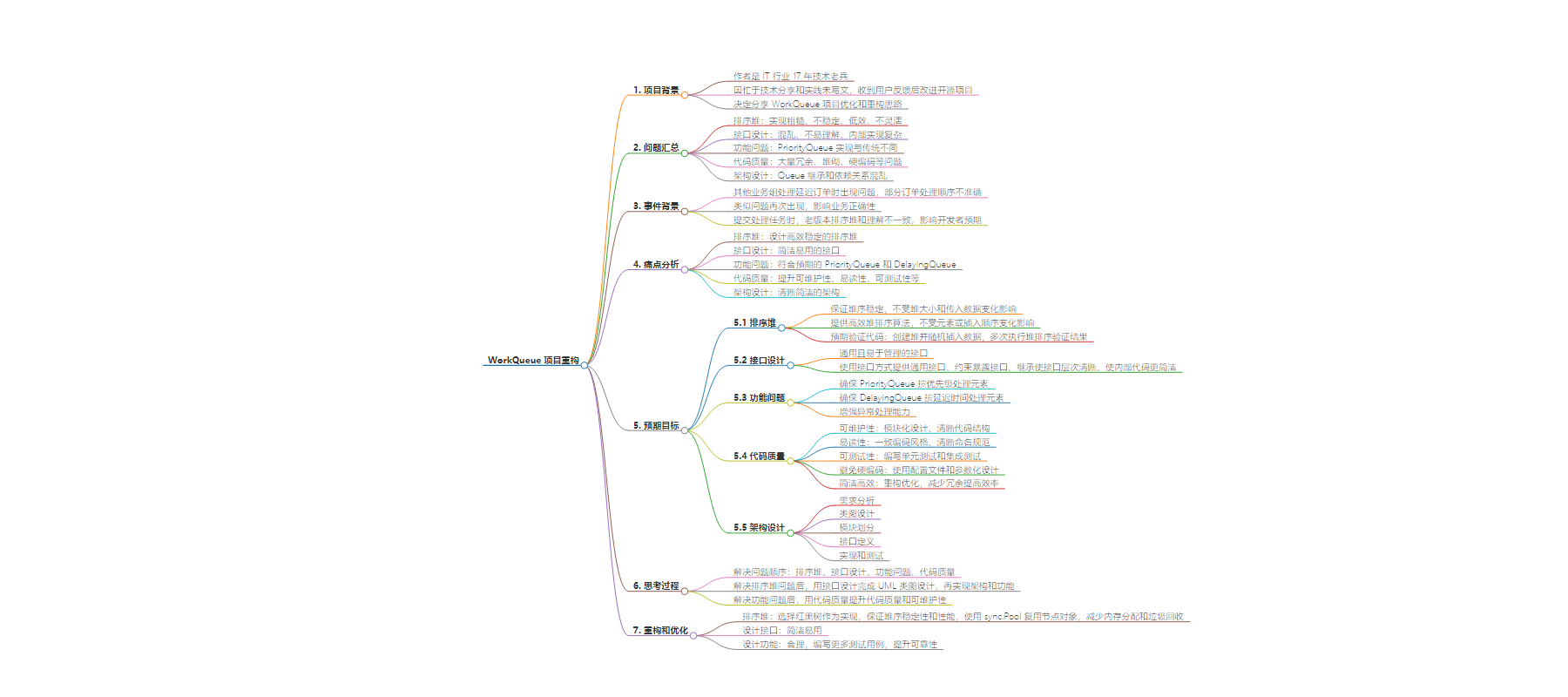
文章地址:https://juejin.cn/post/7395969637877743670
文章来源:juejin.cn
作者:路口IT大叔_KUMA
发布时间:2024/7/28 8:59
语言:中文
总字数:14526字
预计阅读时间:59分钟
评分:84分
标签:开源项目,技术重构,代码优化,架构设计,红黑树
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
点击公众关注号,“技术干货”及时达!
我是 LEE,老李,一个在 IT 行业摸爬滚打 17 年的技术老兵。
有一段时间没有写文章了,主要是最近忙于技术分享和技术实践,没有时间写文章。同时,我也收到了一些使用我开源项目的用户的反馈,因此我一直在不断改进我的开源项目。今天正好没有太多事情,所以决定与大家分享我最近对 WorkQueue 项目进行的优化和重构的思路和实现细节。请注意,本文主要是关于之前的 WorkQueue 项目的优化和重构。如果您对 WorkQueue 项目不熟悉,可以先阅读我之前的文章:《简约而不简单:WorkQueue 的轻量级高效之道》。
在开始之前,先分享一下最近 WorkQueue 项目的情况。随着项目的用户增多,一些用户提出了一些问题,例如性能问题、设计问题和实现细节问题等。其中,对于排序堆的争议最大,一些用户认为排序堆的实现过于粗糙、不稳定、不够高效和灵活。我总结了一些常见问题,主要包括以下几点:
-
「排序堆」:使用传统的四叉堆实现,与二叉堆类似,但存在不能稳定保持堆序的问题,导致在处理大量数据时性能下降严重。 -
「接口设计」:项目的接口设计整体上比较混乱,不容易理解,内部实现也较为复杂,不够简洁。 -
「功能问题」:PriorityQueue 的实现与传统的 PriorityQueue 不太一样,导致一些用户在使用时遇到问题。 -
「代码质量」:项目中存在大量冗余代码、堆砌代码和硬编码等低级问题。 -
「架构设计」:各种 Queue 的继承和依赖关系比较混乱,缺乏清晰的 UML 类图,导致一些用户阅读源码时困难重重。
为了解决这些问题,我决定对 WorkQueue 项目进行全面的重构和优化。这次重构和优化不仅仅是简单地修改代码,而是对整个项目进行全面提升,包括架构设计、接口设计、代码质量和性能优化等方面。重构和优化的目的不是追求完美,而是提升项目的质量、性能、易用性和可维护性。
此外,这次重构和优化也是为了解决我自己的实际问题。因为我的许多开源项目都依赖于 WorkQueue 项目,所以我希望通过这次重构和优化,提升我的开源项目的质量和可维护性。同时,我也希望能够为大家提供一个更好的开源项目,使大家在使用时更加方便、高效和稳定。
事件背景
万物皆可故事,这次重构和优化的背景也是从一个故事开始的。
主要爆雷的地方来自我们其他业务组。他们反映在处理延迟订单时,使用老版本的 WorkQueue(归档为 「v1」 版)出现了一些问题。部分订单的处理时间点靠后的订单(如:2023/3/1 23:0:59)会莫名其妙地在处理时间点靠前的订单(如:2023/3/1 23:0:15)之前被处理,导致订单处理的顺序不准确,产生了不可预期的结果。
当初我以为是业务方的代码问题,并没有太过关注。这个问题只是影响了审计的结果,对业务本身并没有太大的影响。这个问题就此搁置了。然而,不巧的是,这个问题又出现了,这次是来自一个 WorkQueue 的使用者。他们也是在处理延迟任务时使用 WorkQueue,出现了类似的问题。这个问题就比较严重了,直接影响到了业务的正确性,导致了一些不可预期的结果。
另外一个问题是,在提交处理任务时,WorkQueue 会因为之前版本(「v1」 版)排序堆的实现问题以及与大家传统理解的不一致,导致一些使用者在使用时遇到问题。这严重影响了开发者对最终结果的预期。当然,这个问题也得到了外部 WorkQueue 的使用者的反馈。
当我完成 WorkQueue 「v2」 的开发和测试后,回头看之前的第一版 WorkQueue,我意识到当时的设计确实有些草率,虽然在一些地方注意了内存和性能设计,但整体项目和功能设计还是相对粗糙的,甚至存在一些问题。因此,这次重构和优化的目的就是为了解决这些问题。
痛点分析
在开始重构和优化之前,我们先来分析一下 WorkQueue 项目存在的一些痛点,主要有以下几个:
-
「排序堆」:需要设计一个高效稳定的排序堆,以保证堆序的稳定性并提升堆的性能。 -
「接口设计」:需要设计一个简洁易用的接口,以提升项目的易用性。 -
「功能问题」:需要设计一个符合大家理解的 PriorityQueue,以提升项目的易用性。 -
「代码质量」:需要提升项目的代码质量,以提高可维护性。 -
「架构设计」:需要设计一个清晰简洁的架构,以提升项目的可维护性。
考虑到老版本的 WorkQueue(归档为 「v1」 版)存在的问题较多,我认为可以将其归档,而不是基于该版本进行优化和重构。因此,我决定重新设计版本为 「v2」 的全新 WorkQueue 项目。
预期目标
1. 排序堆
为了实现稳定排序和优化整个 WorkQueue 项目的性能,排序堆需要满足以下要求:
-
保证堆序的稳定性,不受堆大小和传入数据变化的影响。 -
提供高效的堆排序算法,不受堆中元素或插入顺序变化的影响。
「预期验证代码:」
创建一个堆,随机插入一些数据,然后多次执行堆排序,验证排序结果的正确性。
funcHeapPush_Random(){
h:=New()
count:=4
//Pushthenodes
h.Push(&lst.Node{Priority:int64(2)})
h.Push(&lst.Node{Priority:int64(0)})
h.Push(&lst.Node{Priority:int64(1)})
h.Push(&lst.Node{Priority:int64(3)})
//Prrintthetreeorder
PrintRootIndexs(h)
PrintOrderTraversalIndexs(h.root)
}
2. 接口设计
为了实现一个通用且易于管理的接口,需要满足以下要求:
-
使用接口 Interface的方式,为使用者提供通用接口,方便扩展。 -
使用接口 Interface约束对外暴露的接口,方便统一管理。 -
使用接口 Interface的继承方式,根据整个项目的设计,使接口层次更加清晰。 -
在变量中使用接口 Interface,使整个项目的内部代码更加简洁且结果更可预期。
「预期验证代码:」
以 PriorityQueue 为例,创建一个 PriorityQueue 实例,并使用接口 Interface 的方式定义配置参数、回调参数以及继承底层接口。
「PriorityQueue 结构体」
直接使用实现了 Queue 接口的结构体作为 PriorityQueue 的继承,并实现了 PriorityQueue 的接口。
//PriorityQueue接口继承了Queue接口,并添加了一个PutWithPriority方法,用于将元素按优先级放入队列。
//ThePriorityQueueinterfaceinheritsfromtheQueueinterfaceandaddsaPutWithPrioritymethodtoputanelementintothequeuewithpriority.
typePriorityQueue=interface{
Queue
//PutWithPriority方法用于将元素按优先级放入队列。
//ThePutWithPrioritymethodisusedtoputanelementintothequeuewithpriority.
PutWithPriority(valueinterface{},priorityint64)error
//HeapRange方法用于遍历sorted堆中的所有元素。
//TheHeapRangemethodisusedtotraverseallelementsinthesortedheap.
HeapRange(fnfunc(valueinterface{},delayint64)bool)
}
//priorityQueueImpl结构体,实现了PriorityQueue接口
//ThepriorityQueueImplstruct,whichimplementsthePriorityQueueinterface
typepriorityQueueImplstruct{
//Queue是一个队列接口
//Queueisaqueueinterface
Queue
...
}
「PriorityQueue 配置参数」
使用 PriorityQueueConfig 结构体作为 PriorityQueue 的配置参数。PriorityQueueConfig 结构体继承了 QueueConfig 结构体,并添加了一个 callback 参数,用于回调函数。
//PriorityQueueConfig结构体,用于配置优先队列
//ThePriorityQueueConfigstruct,usedforconfiguringthepriorityqueue
typePriorityQueueConfigstruct{
//QueueConfig是队列的配置
//QueueConfigistheconfigurationofthequeue
QueueConfig
//callback是优先队列的回调函数
//callbackisthecallbackfunctionofthepriorityqueue
callbackPriorityQueueCallback
}
「PriorityQueue 回调函数」
使用 PriorityQueueCallback 接口作为 PriorityQueue 的回调函数。PriorityQueueCallback 接口继承了 QueueCallback 接口,并添加了一个 OnPriority 方法,用于在元素按优先级放入队列时被调用。
//PriorityQueueCallback接口继承了QueueCallback接口,并添加了OnPriority方法。
//ThePriorityQueueCallbackinterfaceinheritsfromtheQueueCallbackinterfaceandaddstheOnPrioritymethod.
typePriorityQueueCallback=interface{
QueueCallback
//OnPriority方法在元素被按优先级放入队列时被调用。
//TheOnPrioritymethodiscalledwhenanelementisputintothequeuewithpriority.
OnPriority(valueinterface{},priorityint64)
}
「PriorityQueue 创建方法」
创建一个新的 PriorityQueue,并返回一个实现了 PriorityQueue 接口的对象。
//NewPriorityQueue函数用于创建一个新的PriorityQueue
//TheNewPriorityQueuefunctionisusedtocreateanewPriorityQueue
funcNewPriorityQueue(config*PriorityQueueConfig)PriorityQueue{
...
}
3. 功能问题
为解决设计与预期不一致的问题,我们需要重新实现符合预期的 PriorityQueue 和 DelayingQueue。具体要求如下:
-
「功能一致性」:确保 PriorityQueue严格按照优先级处理元素。 -
「延迟处理」:确保 DelayingQueue根据设定的延迟时间处理元素。 -
「错误处理」:增强异常处理能力,确保队列在各种边界条件下正常工作。
4. 代码质量
为提升代码质量,我们需关注以下方面:
-
「可维护性」:采用模块化设计和清晰的代码结构,使代码易于理解和修改。 -
「易读性」:保持一致的编码风格和清晰的命名规范,使代码易读易懂。 -
「可测试性」:编写单元测试和集成测试,确保代码的正确性和稳定性。 -
「避免硬编码」:使用配置文件和参数化设计,减少硬编码,提升代码灵活性。 -
「简洁高效」:通过重构和优化,减少冗余代码,提高执行效率。
5. 架构设计
为提升项目可维护性,我们将设计一个清晰简洁的架构,具体步骤如下:
-
「需求分析」:详细分析项目需求,明确各模块的功能和关系。 -
「类图设计」:根据需求分析,设计 UML类图,明确各类的职责和关系。 -
「模块划分」:将项目划分为低耦合高内聚的多个模块。 -
「接口定义」:为各模块定义清晰的接口,确保模块间的通信和协作。 -
「实现和测试」:逐步实现各模块,并编写测试用例,确保模块的正确性和稳定性。
通过以上步骤,我们可以确保项目架构清晰简洁,代码质量高,功能实现符合预期。
思考过程
针对上面的痛点分析,我认为解决这些问题存在非常重要的顺序,并且这个顺序不宜颠倒。经过反复思考,我认为解决这些问题的顺序应该是:
-
「排序堆」:首先解决排序堆的问题,因为排序堆是整个项目的核心,也是整个项目的性能瓶颈,所以首先解决排序堆的问题。 -
「接口设计」:其次解决接口设计的问题,因为接口设计是整个项目的基础,也是整个项目的灵魂,所以其次解决接口设计的问题。 -
「功能问题」:再次解决功能问题,因为功能问题是整个项目的核心功能,也是整个项目的使用者关心的问题,所以再次解决功能问题。 -
「代码质量」:最后解决代码质量的问题,因为代码质量是整个项目的基础,也是整个项目的可维护性,所以最后解决代码质量的问题。
当然,以上只是整体思路。在解决了「排序堆」的问题后,可以使用「接口设计」来完成 UML 类图的设计,然后根据 UML 类图来实现整个项目的架构和功能。在解决了「功能问题」后,可以使用「代码质量」来提升项目的代码质量和可维护性。
重构和优化
有了上面的分析,现在可以开始重构和优化 WorkQueue 项目了。主要分为以下几个步骤:
-
「排序堆」:设计一个高效稳定的排序堆,保证堆序的稳定性并提升堆的性能。 -
「设计接口」:设计一个简洁易用的接口,提升项目的易用性。 -
「设计功能」:设计合理的功能,并编写更多的测试用例,提升项目的可靠性。
1. 排序堆
要优化排序堆,主要是对排序堆的实现进行优化,包括提升排序堆的性能和保证堆序的稳定性。在选择排序算法之前,我们先来看一下排序堆的实现。
1.1. 排序堆的种类
实际上,研究排序堆的种类就是研究排序算法。下面列举了一些常见的排序算法及其特点:
「常见排序算法对比表」
| 排序算法 | 优点 | 缺点 | 最佳时间复杂度 | 平均时间复杂度 | 最差时间复杂度 | 空间复杂度 | 排序结果 | 额外空间 |
|---|---|---|---|---|---|---|---|---|
| 冒泡排序 | 实现简单,适用于小数据集 | 效率低,特别是对于大数据集 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 | 否 |
| 选择排序 | 实现简单,不需要额外的内存 | 效率低,特别是对于大数据集 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 | 否 |
| 插入排序 | 对于几乎已经排序的数据效率高,简单易实现 | 效率低,对于大数据集不适用 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 | 否 |
| 归并排序 | 稳定,适用于大数据集 | 需要额外的内存 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 | 是 |
| 快速排序 | 平均情况下效率高 | 最差情况可能退化为 O(n^2) | O(nlogn) | O(nlogn) | O(n^2) | O(logn) | 不稳定 | 否 |
| 堆排序 | 不需要额外的内存,适用于大数据集 | 实现复杂,不稳定 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 | 否 |
| 希尔排序 | 适用于中等大小数据集,效率较高 | 不稳定,时间复杂度分析复杂 | O(nlog^2n) | O(nlog^2n) | O(n^2) | O(1) | 不稳定 | 否 |
| 基数排序 | 对特定类型的数据非常高效 | 需要额外的内存,不适用于所有类型的数据 | O(nk) | O(nk) | O(nk) | O(n + k) | 稳定 | 是 |
| AVL 树 | 自平衡,查找、插入和删除操作时间复杂度低 | 只要节点变动都需要重新平衡,整个树趋近于平衡 | O(logn) | O(logn) | O(logn) | O(n) | 稳定(*) | 否 |
| 红黑树 | 自平衡,查找、插入和删除操作时间复杂度低 | 插入节点树发生重平衡,整个树存在一定的不平衡 | O(logn) | O(logn) | O(logn) | O(n) | 稳定(*) | 否 |
需要注意的是,表中将 AVL 树 和 红黑树 也列入了排序算法对比表中。虽然 AVL 树 和 红黑树 是一种基于树的排序算法,但它们也可以满足我们对堆的稳定性的需求。
1.2. 排序堆的实现
在排序堆的实现中,我选择了使用 红黑树 作为排序堆的实现。红黑树 是一种自平衡二叉搜索树,可以保证堆序的稳定性,并且具有较好的性能。尽管 红黑树 的实现较为复杂,但我认为这个实现是值得的,因为它可以保证堆序的稳定性并提升堆的性能。
「注意」:AVL 树 和 红黑树 并非能满足严格意义上的对序堆肯定性严格意义,但是它们能够保证在堆内数值的严格排序性,这个是满足我们的设计需要的。
有人可能会问,为什么不使用 go 官方的 container/heap 包呢?这是因为 container/heap 包是基于「数组」实现的,而我需要的是基于「链表」实现的堆。因此,我只能自己实现一个基于「链表」的排序堆。
(★) 内存碎片化对比
在大多数编程语言中,使用 new 关键字在「堆内存」中分配对象。
| 特性 | 栈内存 | 堆内存 |
|---|---|---|
| 「碎片化原因」 | 按顺序分配和释放,不会产生碎片 | 随机分配和释放,可能产生碎片 |
| 「碎片化表现」 | 无 | 内存空洞,影响大块内存分配 |
| 「应对策略」 | 不需要 | 内存池、紧凑化、最佳适配算法等 |
根据上表,我们可以看出,「堆内存」可能会产生碎片,而「栈内存」不会产生碎片。如果使用「数组」作为「堆」的实现,那么在「堆」的插入和删除操作中,可能会产生大量的内存碎片,导致内存空洞,影响大块内存分配。因此,我选择使用「链表」作为「堆」的实现,因为「链表」可以充分利用内存中的空间,不会产生内存碎片。我在之前的文章《简约而不简单:WorkQueue 的轻量级高效之道》中详细介绍了这一点。
在排序堆的实现中,我还使用了 go 中的 sync.Pool 来复用堆中的节点对象,以减少内存分配和垃圾回收的次数,提升堆的性能。
「示意图」
示意图仅仅是一个简单的示意图,并不能完全覆盖 红黑树 的插入的所有情况和完整步骤。
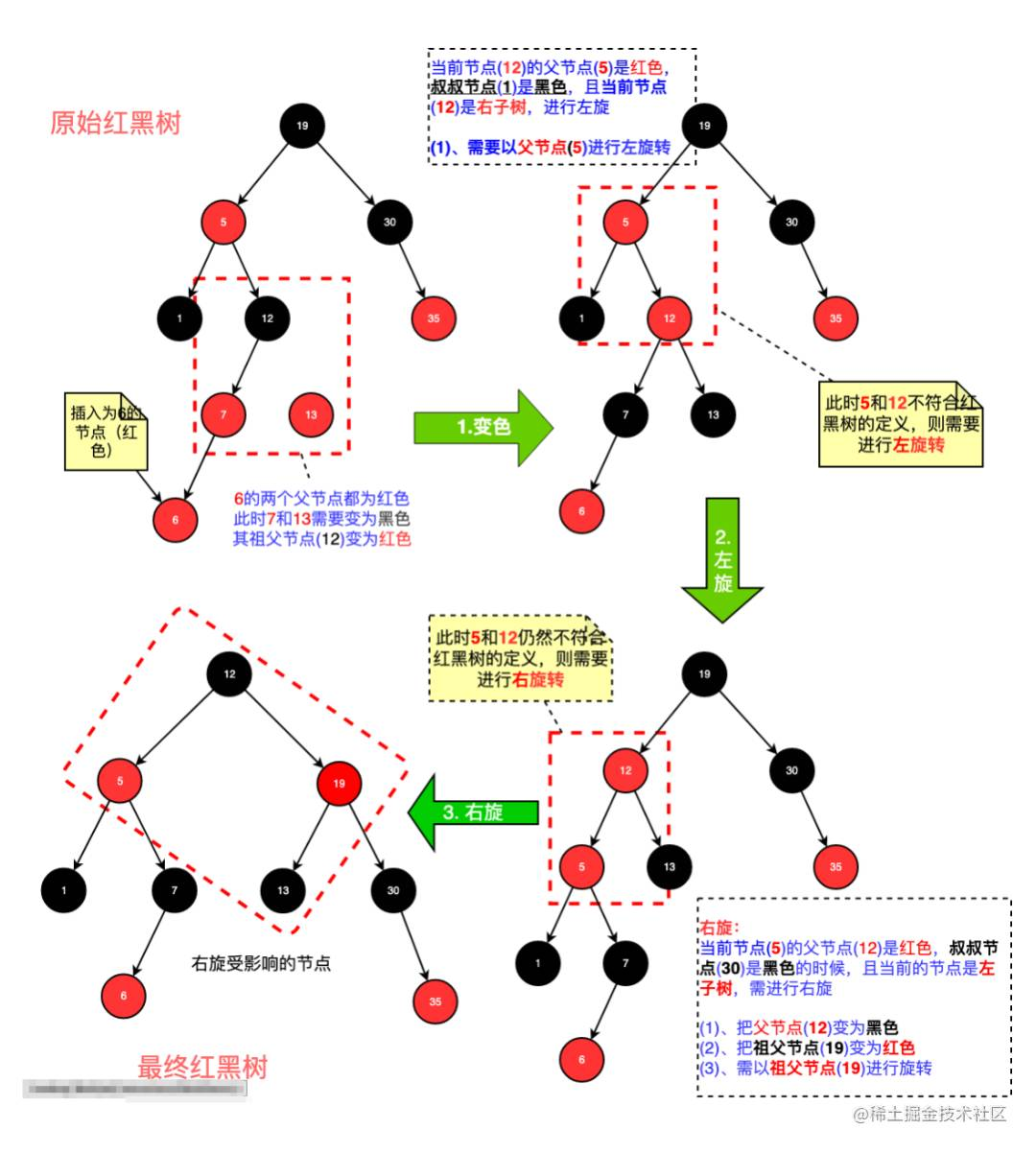
「演示代码」
-
插入节点
//insert方法用于向红黑树中插入一个节点
//TheinsertmethodisusedtoinsertanodeintotheRED-BLACKtree
func(tree*RBTree)insert(node*lst.Node){
//parent用于保存当前节点的父节点
//parentisusedtosavetheparentofthecurrentnode
varparent*lst.Node
//current用于保存当前正在处理的节点,初始为树根
//currentisusedtosavethenodecurrentlybeingprocessed,initiallytherootofthetree
current:=tree.root
//当current不为空时,进行循环
//Loopwhencurrentisnotnil
forcurrent!=nil{
//将parent设置为current
//Setparenttocurrent
parent=current
//如果node的优先级小于current的优先级
//Ifthepriorityofnodeislessthanthepriorityofcurrent
ifnode.Priority<current.Priority{
//将current设置为其左子节点
//Setcurrenttoitsleftchild
current=current.Left
}else{
//将current设置为其右子节点
//Setcurrenttoitsrightchild
current=current.Right
}
}
//将node的父节点设置为parent
//Settheparentofnodetoparent
node.Parent=parent
//如果parent为空
//Ifparentisnil
ifparent==nil{
//将树根设置为node
//Settherootofthetreetonode
tree.root=node
}elseifnode.Priority<parent.Priority{//如果node的优先级小于parent的优先级
//将parent的左子节点设置为node
//Settheleftchildofparenttonode
parent.Left=node
}else{
//将parent的右子节点设置为node
//Settherightchildofparenttonode
parent.Right=node
}
//将node的左子节点和右子节点都设置为nil
//Setboththeleftchildandrightchildofnodetonil
node.Left=nil
node.Right=nil
//将node的颜色设置为红色
//SetthecolorofnodetoRED
node.Color=lst.RED
//调用insertFixUp方法对树进行调整
//CalltheinsertFixUpmethodtoadjustthetree
insertFixUp(tree,node)
//将树的节点数量加一
//Increasethenumberofnodesinthetreebyone
tree.count++
//如果树的头节点为空或node的优先级小于头节点的优先级
//Iftheheadofthetreeisnilorthepriorityofnodeislessthanthepriorityofthehead
iftree.head==nil||node.Priority<tree.head.Priority{
//将树的头节点设置为node
//Settheheadofthetreetonode
tree.head=node
}
//如果树的尾节点为空或node的优先级大于尾节点的优先级
//Ifthetailofthetreeisnilorthepriorityofnodeisgreaterthanthepriorityofthetail
iftree.tail==nil||node.Priority>tree.tail.Priority{
//将树的尾节点设置为node
//Setthetailofthetreetonode
tree.tail=node
}
} -
删除节点
//delete函数用于删除红黑树中的节点
//ThedeletefunctionisusedtodeleteanodeintheRED-BLACKtree
func(tree*RBTree)delete(node*lst.Node){
//定义child和target节点
//Definechildandtargetnodes
varchild,target*lst.Node
//如果node的左子节点为空或右子节点为空
//Iftheleftchildofnodeisnilortherightchildisnil
ifnode.Left==nil||node.Right==nil{
//target设置为node
//Settargettonode
target=node
}else{
//target设置为node的后继节点
//Settargettothesuccessorofnode
target=tree.successor(node)
}
//如果target的左子节点不为空
//Iftheleftchildoftargetisnotnil
iftarget.Left!=nil{
//child设置为target的左子节点
//Setchildtotheleftchildoftarget
child=target.Left
}else{
//child设置为target的右子节点
//Setchildtotherightchildoftarget
child=target.Right
}
//如果child不为空
//Ifchildisnotnil
ifchild!=nil{
//将child的父节点设置为target的父节点
//Settheparentofchildtotheparentoftarget
child.Parent=target.Parent
}
//如果target的父节点为空
//Iftheparentoftargetisnil
iftarget.Parent==nil{
//将树根设置为child
//Settherootofthetreetochild
tree.root=child
}elseiftarget==target.Parent.Left{//如果target是其父节点的左子节点
//将target的父节点的左子节点设置为child
//Settheleftchildoftheparentoftargettochild
target.Parent.Left=child
}else{//如果target是其父节点的右子节点
//将target的父节点的右子节点设置为child
//Settherightchildoftheparentoftargettochild
target.Parent.Right=child
}
//如果target不等于node
//Iftargetisnotequaltonode
iftarget!=node{
//将node的值设置为target的值
//Setthevalueofnodetothevalueoftarget
node.Value=target.Value
//将node的优先级设置为target的优先级
//Setthepriorityofnodetothepriorityoftarget
node.Priority=target.Priority
}
//如果target的颜色为黑色
//IfthecoloroftargetisBLACK
iftarget.Color==lst.BLACK{
//调用deleteFixUp函数调整红黑树
//CallthedeleteFixUpfunctiontoadjusttheRED-BLACKtree
deleteFixUp(tree,child)
}
//将树的节点数量减一
//Decreasethenumberofnodesinthetreebyone
tree.count--
//如果树的节点数量为零
//Ifthenumberofnodesinthetreeiszero
iftree.count==0{
//将树的头节点和尾节点设置为nil
//Settheheadandtailnodesofthetreetonil
tree.head=nil
tree.tail=nil
}else{
//如果树的头节点等于node
//Iftheheadnodeofthetreeisequaltonode
iftree.head==node{
//将树的头节点设置为树根的最小节点
//Settheheadnodeofthetreetotheminimumnodeoftheroot
tree.head=tree.minimum(tree.root)
}
//如果树的尾节点等于node
//Ifthetailnodeofthetreeisequaltonode
iftree.tail==node{
//将树的尾节点设置为树根的最大节点
//Setthetailnodeofthetreetothemaximumnodeoftheroot
tree.tail=tree.maximum(tree.root)
}
}
}
1.3. 排序堆的优化经历
当然,这个选择过程并不是一帆风顺的。在选择使用 红黑树 作为 排序堆 的实现之前,我也考虑了其他的排序算法,比如插入排序和AVL 树等。现在我来详细说明一下放弃 插入排序 和 AVL 树 的原因。
插入排序
插入排序 是一种简单直观的排序算法,但是它的时间复杂度是 O(n^2),不适合处理大数据集。虽然 插入排序 在处理小规模数据时性能较高,但是在处理大规模数据时性能较低。因此,我决定放弃 插入排序 算法。
在 排序堆的实现中,有一个循环会从 链表 的最后一个节点开始遍历。这个循环的目的是找到合适的位置来插入新的节点。
「示意图」

「演示代码」
//Push方法将一个新的节点添加到堆中。
//ThePushmethodaddsanewnodetotheheap.
func(h*Heap)Push(n*lst.Node){
//如果n是nil或者堆的长度为0,我们就直接在链表的后面添加n。
//Ifnisnilorthelengthoftheheapis0,wejustaddntothebackofthelist.
ifn==nil||h.list.Len()==0{
h.list.PushBack(n)
return
}
//获取链表的最后一个节点。
//Getthelastnodeofthelist.
current:=h.list.Back()
//如果当前节点不是nil并且n小于当前节点,我们就继续向前查找。
//Ifthecurrentnodeisnotnilandnislessthanthecurrentnode,wecontinuetolookforward.
forcurrent!=nil&&h.less(n,current){
current=current.Prev
}
//如果当前节点是nil,我们就在链表的前面添加n。
//Ifthecurrentnodeisnil,weaddntothefrontofthelist.
ifcurrent==nil{
h.list.PushFront(n)
}else{
//否则,我们就在当前节点的后面添加n。
//Otherwise,weaddnafterthecurrentnode.
h.list.InsertAfter(n,current)
}
}
AVL 树
AVL 树 是一种自平衡二叉搜索树,它能够保持堆序的稳定性,并且具有良好的性能。然而,AVL 树 的实现相对复杂,而且在树发生变化时需要进行复杂的平衡操作。无论是插入节点还是删除节点,都会触发这些平衡操作。因此,AVL 树 的性能相对较低。考虑到这一点,我决定不使用 AVL 树。
「示意图」

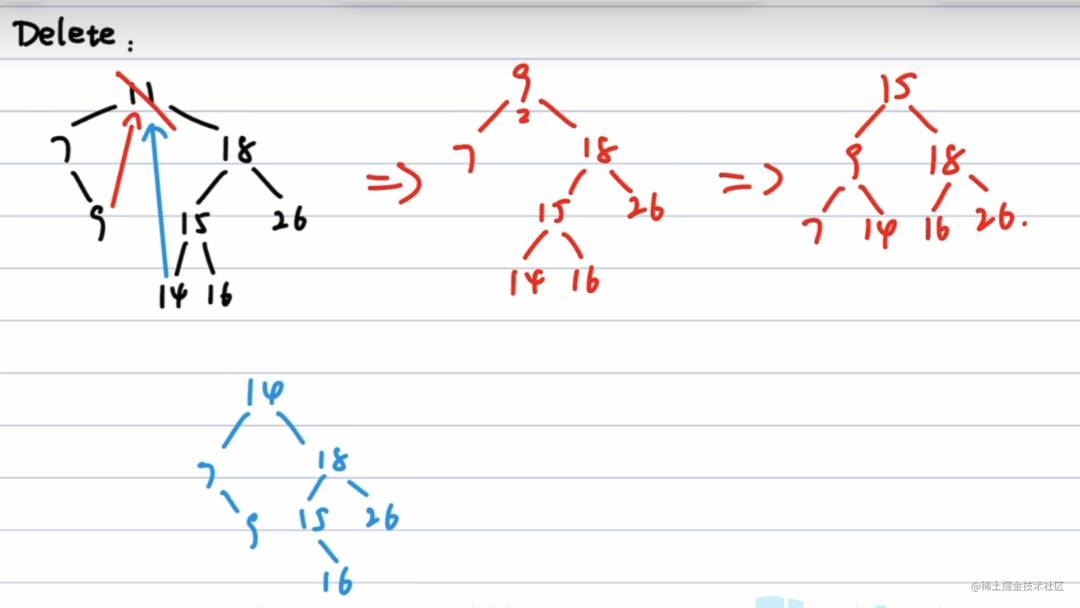
「演示代码」
//insert插入新节点
//insertinsertsanewnode
func(t*SortingTree)insert(node*Node,itemItem)*Node{
//如果节点为空,创建一个新节点并返回
//Ifthenodeisnil,createanewnodeandreturnit
ifnode==nil{
return&Node{item:item,height:1}
}
//如果插入项的值小于当前节点的值,或者值相等但序列号小于当前节点的序列号,则插入到左子树
//Iftheitem'svalueislessthanthecurrentnode'svalue,orthevaluesareequalbutthesequencenumberisless,insertintotheleftsubtree
ifitem.value<node.item.value||(item.value==node.item.value&&item.seqNum<node.item.seqNum){
node.left=t.insert(node.left,item)
}else{
//否则,插入到右子树
//Otherwise,insertintotherightsubtree
node.right=t.insert(node.right,item)
}
//更新节点的高度
//Updatetheheightofthenode
node.height=1+max(height(node.left),height(node.right))
//平衡节点并返回平衡后的节点
//Balancethenodeandreturnthebalancednode
returnt.balance(node)
}
//deleteMin删除最小节点
//deleteMindeletestheminimumnode
func(t*SortingTree)deleteMin(node*Node)(*Node,Item){
//如果节点的左子节点为空,返回右子节点和当前节点的项
//Iftheleftchildofthenodeisnil,returntherightchildandthecurrentnode'sitem
ifnode.left==nil{
returnnode.right,node.item
}
//定义一个变量来存储最小项
//Defineavariabletostoretheminimumitem
varminItemItem
//递归调用deleteMin函数,删除左子树中的最小节点,并更新左子节点
//RecursivelycalldeleteMintodeletetheminimumnodeintheleftsubtreeandupdatetheleftchild
node.left,minItem=t.deleteMin(node.left)
//更新节点的高度
//Updatetheheightofthenode
node.height=1+max(height(node.left),height(node.right))
//平衡节点并返回平衡后的节点和最小项
//Balancethenodeandreturnthebalancednodeandtheminimumitem
1.4. 排序堆的性能测试
对使用了红黑树排序堆的 Push、Pop 和 Remove 方法进行了性能测试。以下是排序堆的性能测试结果:
$gotest-benchmem-run=^$-bench^BenchmarkHeap*.
goos:darwin
goarch:amd64
pkg:github.com/shengyanli1982/workqueue/v2/internal/container/heap
cpu:Intel(R)Xeon(R)CPUE5-2643v2@3.50GHz
BenchmarkHeap_Push-125630415257.5ns/op0B/op0allocs/op
BenchmarkHeap_Pop-1216859534117.4ns/op0B/op0allocs/op
BenchmarkHeap_Remove-121484321728.197ns/op0B/op0allocs/op
2. 链表
实际上,这部分相当于对 WorkQueue 项目中的双向链表进行了重写,基本功能和性能与 container/list 包相似,只是增加了一些额外的功能,例如:「遍历」、「交换」 等,以方便日后的使用。
2.1. 链表的实现
链表的实现与传统的链表实现没有太大区别,甚至可以说是一样的。
//List结构体代表一个双向链表,它有一个头节点和一个尾节点,以及一个记录链表长度的字段。
//TheListstructrepresentsadoublylinkedlist.Ithasaheadnode,atailnode,andafieldtorecordthelengthofthelist.
typeListstruct{
//head是链表的头节点。
//headistheheadnodeofthelist.
//tail是链表的尾节点。
//tailisthetailnodeofthelist.
head,tail*Node
//count是链表的长度。
//countisthelengthofthelist.
countint64
}
2.2. 链表的扩展
这个可能是最大的亮点。我在链表中增加了一些额外的功能,比如「遍历」和「交换」等。这些功能对于依赖链表的 Queue 来说非常重要,例如,Queue 中的 Range 方法就依赖于链表的 Range 方法。
「Range 遍历链表」
//Range方法遍历链表,对每个节点执行fn函数,如果fn返回false,就停止遍历。
//TheRangemethodtraversesthelist,performsthefnfunctiononeachnode,andstopstraversingiffnreturnsfalse.
func(l*List)Range(fnfunc(node*Node)bool){
//我们从头节点开始,遍历整个链表。
//Westartfromtheheadnodeandtraversetheentirelist.
foriterNode:=l.head;iterNode!=nil;iterNode=iterNode.Right{
//我们对当前节点执行fn,如果fn返回false,我们就停止遍历。
//Weperformfnonthecurrentnode,iffnreturnsfalse,westoptraversing.
if!fn(iterNode){
break
}
}
}
「Swap 交换节点」
//Swap方法交换链表中的两个节点n和mark的位置。
//TheSwapmethodswapsthepositionsoftwonodesnandmarkinthelist.
func(l*List)Swap(node,mark*Node){
//如果n或mark是nil,或者n和mark是同一个节点,我们就直接返回,不做任何操作。
//Ifnormarkisnil,ornandmarkarethesamenode,wejustreturndirectlywithoutdoinganything.
ifnode==nil||mark==nil||node==mark{
return
}
//如果n或mark不是链表l的节点,我们就直接返回,不做任何操作。
//Ifnormarkisnotanodeoflistl,wejustreturndirectlywithoutdoinganything.
if!isPtrEqual(node.parentRef,l)||!isPtrEqual(mark.parentRef,l){
return
}
//如果n是mark的前一个节点,我们就移除n,然后将n插入到mark的后面。
//Ifnisthepreviousnodeofmark,weremovenandtheninsertnaftermark.
ifnode.Right==mark{
l.Remove(node)
l.InsertAfter(node,mark)
return
}
//如果n是mark的后一个节点,我们就移除n,然后将n插入到mark的前面。
//Ifnisthenextnodeofmark,weremovenandtheninsertnbeforemark.
ifnode.Left==mark{
l.Remove(node)
l.InsertBefore(node,mark)
return
}
//我们交换n和mark的Prev和Next。
//WeswapthePrevandNextofnandmark.
node.Left,mark.Left=mark.Left,node.Left
node.Right,mark.Right=mark.Right,node.Right
//如果n的Prev不是nil,我们就更新n的Prev的Next为n,否则,我们将链表的头节点设置为n。
//Ifn'sPrevisnotnil,weupdaten'sPrev'sNextton,otherwise,wesettheheadnodeofthelistton.
ifnode.Left!=nil{
node.Left.Right=node
}else{
l.head=node
}
//如果n的Next不是nil,我们就更新n的Next的Prev为n,否则,我们将链表的尾节点设置为n。
//Ifn'sNextisnotnil,weupdaten'sNext'sPrevton,otherwise,wesetthetailnodeofthelistton.
ifnode.Right!=nil{
node.Right.Left=node
}else{
l.tail=node
}
//如果mark的Prev不是nil,我们就更新mark的Prev的Next为mark,否则,我们将链表的头节点设置为mark。
//Ifmark'sPrevisnotnil,weupdatemark'sPrev'sNexttomark,otherwise,wesettheheadnodeofthelisttomark.
ifmark.Left!=nil{
mark.Left.Right=mark
}else{
l.head=mark
}
//如果mark的Next不是nil,我们就更新mark的Next的Prev为mark,否则,我们将链表的尾节点设置为mark。
//Ifmark'sNextisnotnil,weupdatemark'sNext'sPrevtomark,otherwise,wesetthetailnodeofthelisttomark.
ifmark.Right!=nil{
mark.Right.Left=mark
}else{
l.tail=mark
}
}
「Slice 链表元素切片」
//Slice方法将链表转换为一个切片,切片中的元素顺序和链表中的节点顺序一致。
//TheSlicemethodconvertsthelisttoaslice,theorderoftheelementsinthesliceisconsistentwiththeorderofthenodesinthelist.
func(l*List)Slice()[]interface{}{
//我们创建一个空的切片,切片的容量为链表的长度。
//Wecreateanemptyslice,thecapacityofthesliceisthelengthofthelist.
nodes:=make([]interface{},0,l.count)
//我们遍历链表,将每个节点的Value添加到切片中。
//WetraversethelistandaddtheValueofeachnodetotheslice.
l.Range(func(node*Node)bool{
nodes=append(nodes,node.Value)
returntrue
})
//返回切片。
//Returntheslice.
returnnodes
}
2.3. 链表性能测试
既然我们已经重写了链表,那么我们需要对链表进行性能测试,以评估其性能表现。链表的性能与 container/list 包的性能基本相同。
$gotest-benchmem-run=^$-bench^BenchmarkList*.
goos:darwin
goarch:amd64
pkg:github.com/shengyanli1982/workqueue/v2/internal/container/list
cpu:Intel(R)Xeon(R)CPUE5-2643v2@3.50GHz
BenchmarkList_PushBack-121869051076.447ns/op0B/op0allocs/op
BenchmarkList_PushFront-121573720527.701ns/op0B/op0allocs/op
BenchmarkList_PopBack-121795558466.645ns/op0B/op0allocs/op
BenchmarkList_PopFront-121800305826.989ns/op0B/op0allocs/op
BenchmarkList_InsertBefore-121892747716.406ns/op0B/op0allocs/op
BenchmarkList_InsertAfter-121600789816.490ns/op0B/op0allocs/op
BenchmarkList_Remove-121832507826.440ns/op0B/op0allocs/op
BenchmarkList_MoveToFront-121460212637.837ns/op0B/op0allocs/op
BenchmarkList_MoveToBack-121413364298.589ns/op0B/op0allocs/op
BenchmarkList_Swap-1210000000010.47ns/op0B/op0allocs/op
3. 接口设计
WorkQueue 的 v2 版本重新设计了接口,使其更加简单、直观和易用。在接口设计上,我们遵循了 Go 语言的接口设计原则,如面向接口编程、接口隔离原则和依赖倒置原则等。这样做的好处是降低耦合度、提高代码的可维护性和可扩展性。
在接口设计方面,我们也遵循了 UML 类图优先代码的原则,即先绘制 UML 类图,再编写代码。
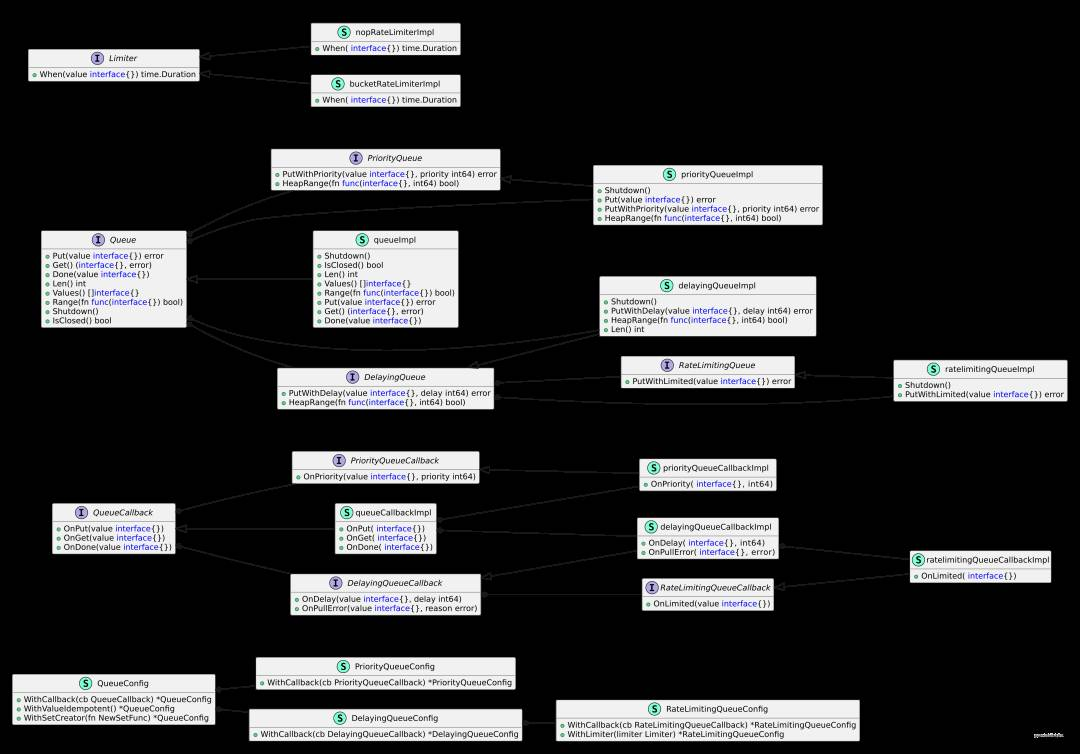
通过 UML 类图,我们可以更好地理解 WorkQueue 的 v2 版本的设计思路和实现原理,以及各个类之间的关系、属性和方法。
3.1. 接口设计原则
在设计接口时,我们遵循以下几个原则:
-
「面向接口编程」:通过定义接口来隔离具体实现,使得代码更加灵活和可扩展。 -
「接口隔离原则」:每个接口只包含客户端所需的方法,避免臃肿的接口。 -
「依赖倒置原则」:高层模块不应该依赖于低层模块,二者都应该依赖于抽象。
3.2. UML 类图解析
这份 .puml 文件是一个 PlantUML 图,描述了软件架构中各类和接口的结构及其关系。以下是文件内容的结构和关系的分析总结:
图表分为四个主要命名空间:config(配置),callback(回调),queue(队列) 和 limiter(限流器)。
3.2.1. 命名空间:config(配置)
-
-
QueueConfig(队列配置):方法包括WithCallback、WithValueIdempotent和WithSetCreator。 -
DelayingQueueConfig(延迟队列配置):方法WithCallback。 -
PriorityQueueConfig(优先队列配置):方法WithCallback。 -
RateLimitingQueueConfig(限流队列配置):方法WithCallback和WithLimiter。
-
-
-
QueueConfig是DelayingQueueConfig和PriorityQueueConfig的基类。 -
DelayingQueueConfig是RateLimitingQueueConfig的基类。
-
3.2.2. 命名空间:callback(回调)
-
-
QueueCallback(队列回调):方法包括OnPut、OnGet和OnDone。 -
DelayingQueueCallback(延迟队列回调):方法OnDelay和OnPullError。 -
PriorityQueueCallback(优先队列回调):方法OnPriority。 -
RateLimitingQueueCallback(限流队列回调):方法OnLimited。
-
-
-
queueCallbackImpl(队列回调实现):实现了QueueCallback。 -
delayingQueueCallbackImpl(延迟队列回调实现):实现了DelayingQueueCallback。 -
priorityQueueCallbackImpl(优先队列回调实现):实现了PriorityQueueCallback。 -
ratelimitingQueueCallbackImpl(限流队列回调实现):实现了RateLimitingQueueCallback。
-
3.2.3. 命名空间:queue(队列)
-
-
Queue(队列):方法包括Shutdown、Put、Get和Done。 -
delayingQueueImpl(延迟队列实现):方法包括Shutdown、PutWithDelay、HeapRange和Len。 -
priorityQueueImpl(优先队列实现):方法包括Shutdown、Put、PutWithPriority和HeapRange。 -
ratelimitingQueueImpl(限流队列实现):方法Shutdown和PutWithLimited。
-
-
-
Queue是delayingQueueImpl、priorityQueueImpl和ratelimitingQueueImpl的基类。 -
DelayingQueue是ratelimitingQueueImpl的基类。 -
PriorityQueue是priorityQueueImpl的基类。
-
3.2.4. 命名空间:limiter(限流器)
-
-
bucketRateLimiterImpl(桶限流器实现):实现了Limiter,方法When。 -
nopRateLimiterImpl(空限流器实现):实现了Limiter,方法When。## 4. 功能设计
-
在本节中,我们将详细介绍项目的主要功能模块及其设计思路。主要包括优先级队列和延迟队列的设计与实现。
4. 功能设计
本节将详细介绍项目的主要功能模块及其设计思路,主要包括优先级队列和延迟队列的设计与实现。
4.1 Priority Queue 优先级队列
优先级队列是一种特殊的队列数据结构,其中每个元素都有一个优先级,优先级高的元素会优先被处理。在设计优先级队列时,我们需要考虑以下几点:
-
「数据结构选择」:选择使用堆(Heap)来实现优先级队列,因为堆能够高效地进行插入和删除操作。 -
「接口设计」:优先级队列需要提供插入、删除、获取最高优先级元素等基本操作接口。 -
「性能优化」:通过优化堆的实现,确保优先级队列在高并发场景下的性能表现。 -
「测试与验证」:编写单元测试和性能测试,确保优先级队列的正确性和高效性。
在 WorkQueue 的 「v1」 版本中,我在 README.md 中这样描述:
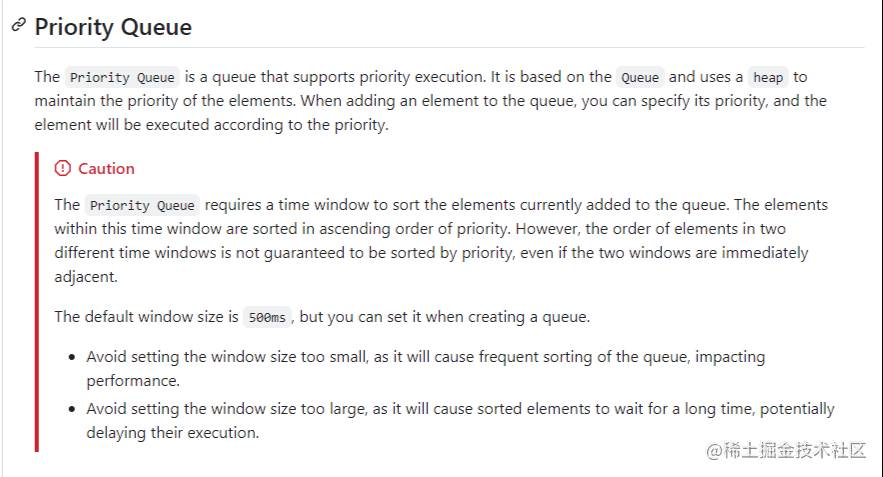
在优先级队列中,需要一个时间窗口来对当前添加到队列中的元素进行排序。在这个时间窗口内的元素按照优先级升序排序。然而,即使两个时间窗口紧邻,两个窗口中的元素的顺序也不能保证按照优先级排序。
这个 排序窗口 的概念让很多开发者感到困惑,因为在传统的优先级队列中并没有这样的概念。此外,开发者还需要考虑 排序窗口 的大小,根据窗口大小来决定是否需要对队列中的元素进行排序。
这样一来,导致了 PriorityQueue 的实现变得复杂,并且与传统的优先级队列有很大的不同。在 「v2」 版本中,我对 PriorityQueue 进行了重新设计,去掉了 排序窗口 的概念,遵循通用的 PriorityQueue 概念,使得 PriorityQueue 的实现更加简单、直观和易用。
使用通用的 PriorityQueue 概念,可能会出现一个问题:如果存在一个十分低优先级的任务,那么这个任务就会一直被堵塞在队列中,无法被处理。这个问题在 「v1」 版本中是不存在的,因为 排序窗口 的存在可以保证低优先级的任务也能被及时处理。然而,在 「v2」 版本中,这个问题是存在的,开发者需要注意这一点。
在 WorkQueue 的 「v2」 版本中,我在 README.md 中这样描述:
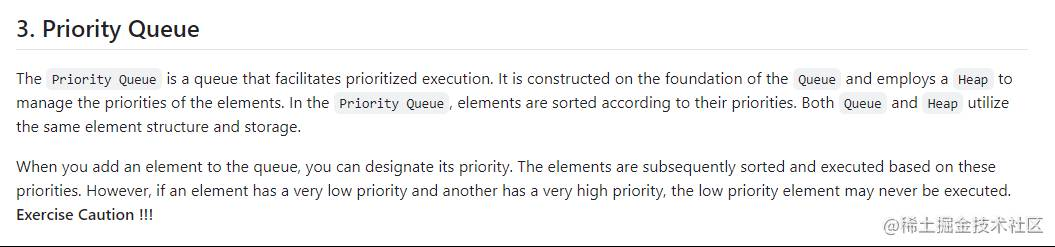
因此,在 「v2」 版本中,PriorityQueue 回归了传统的优先级队列的概念,使得开发者在使用 PriorityQueue 时更符合直觉,不会因为 排序窗口 的存在而感到困惑。
4.2 Delaying Queue 延迟队列
延迟队列是一种特殊的队列数据结构,其中每个元素都有一个延迟时间,只有当延迟时间到达后,元素才会被处理。在设计延迟队列时,我们主要考虑以下几点:
-
「数据结构选择」:选择使用时间堆(Time Heap)来实现延迟队列,因为时间堆能够高效地管理定时任务。 -
「接口设计」:延迟队列需要提供插入、删除、获取到期元素等基本操作接口。 -
「时间管理」:通过精确的时间管理,确保延迟队列能够准确地处理到期元素。 -
「测试与验证」:编写单元测试和性能测试,确保延迟队列的正确性和高效性。
DelayingQueue 是日常使用和项目开发中最常见的一种队列,它可以用来处理定时任务、延迟任务等。然而,处理延迟任务的过期问题一直困扰着我。
在设计过程中,我考虑了两种方案:使用 time.Timer 和使用 time.Ticker 来处理延迟任务的过期问题。经过深思熟虑和讨论,我最终选择了使用 time.Ticker。
首先,time.Timer 是一个单次触发的定时器,只能触发一次,而 time.Ticker 是一个周期触发的定时器,可以周期性地触发。在延迟队列中,我们需要周期性地检查延迟任务是否过期,因此 time.Ticker 更适合处理延迟任务的过期问题。
虽然 time.Ticker 的周期执行间隔是固定的,无法动态调整,但在延迟队列中,我们可以根据队列中的元素动态调整执行间隔。这是 time.Timer 支持者的一个观点,因为 time.Timer 可以通过 Reset 方法动态调整执行间隔。
然而,我选择使用 time.Ticker 的原因是如何处理延迟任务的到期和数据处理的问题。
-
如果逐一处理延迟任务,那么 time.Timer是最好的选择。每次处理完一个任务后,根据下一个任务的延迟时间调整time.Timer的执行时间。 -
如果批量处理延迟任务,那么 time.Ticker是最好的选择。每次time.Ticker触发时,我们处理所有到期的任务。
在大量延迟任务同时到期的情况下,逐一处理延迟任务并反复调整 time.Timer 的执行时间会导致性能下降。而批量处理延迟任务,一批任务一起处理,可以减少调整 time.Timer 的次数,提高性能。这里借鉴了 「v1」 版本中窗口的概念,将延迟任务分为多个窗口,每个窗口的大小是固定的,当窗口中的任务到期时,处理该窗口中的所有任务。
我们通过一组图表来展示 DelayingQueue 中的窗口概念:
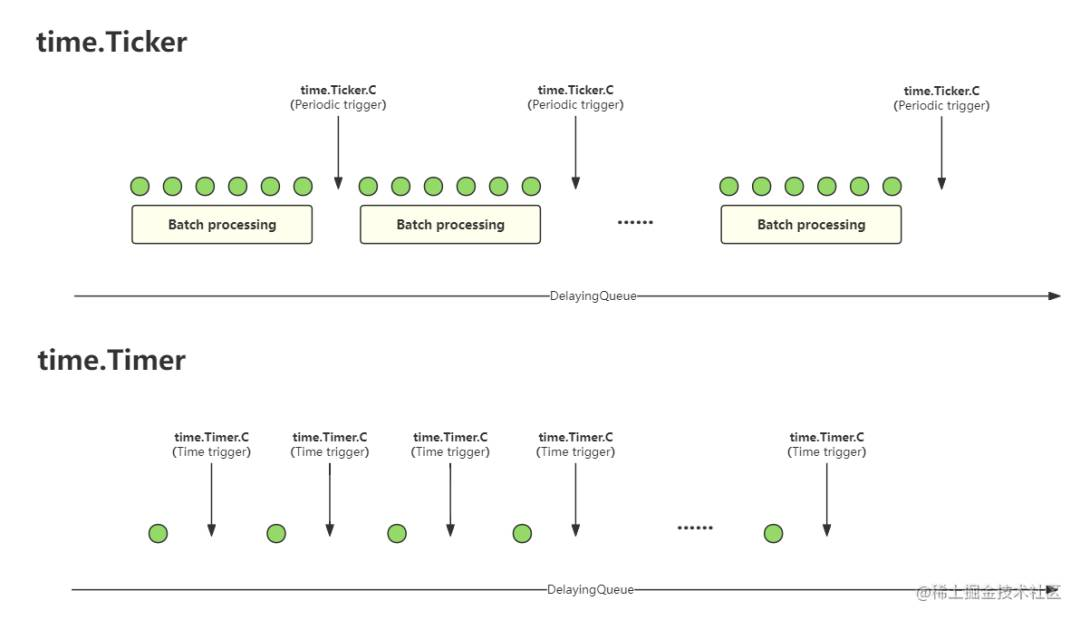
经过广泛和深入的讨论,我们最终确定了窗口间隔的时间为 「300ms」,这个值经过多次测试和调整得出。这个值既能保证延迟任务的及时处理,又能保证性能的高效性.
在 WorkQueue 的 「v2」 版本中,我在 README.md 中这样描述:
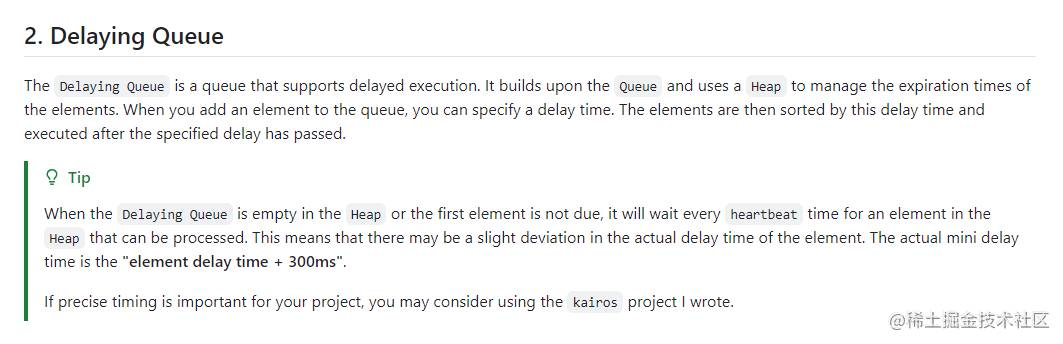
使用批量任务的窗口方法虽然可以满足各种高性能的需求,但是也不是无限可击的,因为窗口的大小是固定的,如果窗口中的任务过分的稀疏,那么可能会导致延迟任务处理没有及时性。我在 README.md 也提到了这一点:「“This means that there may be a slight deviation in the actual delay time of the element. The actual mini delay time is the “element delay time + 300ms”.”」。
5. 性能测试
我对 WorkQueue 的 v2 版本进行了一系列性能测试,主要测试了 Queue、DelayingQueue、PriorityQueue 和 RateLimitingQueue 四个队列的性能。以下是性能测试的结果:
$gotest-benchmem-run=^$-bench^Benchmark*.
goos:darwin
goarch:amd64
pkg:github.com/shengyanli1982/workqueue/v2
cpu:Intel(R)Xeon(R)CPUE5-2643v2@3.50GHz
BenchmarkDelayingQueue_Put-124635976255.6ns/op72B/op1allocs/op
BenchmarkDelayingQueue_PutWithDelay-121635588784.7ns/op71B/op1allocs/op
BenchmarkDelayingQueue_Get-122479513647.53ns/op21B/op0allocs/op
BenchmarkDelayingQueue_PutAndGet-121599589075.25ns/op7B/op0allocs/op
BenchmarkDelayingQueue_PutWithDelayAndGet-121731825664.3ns/op29B/op1allocs/op
BenchmarkPriorityQueue_Put-123030818433.5ns/op71B/op1allocs/op
BenchmarkPriorityQueue_PutWithPriority-122937105452.0ns/op71B/op1allocs/op
BenchmarkPriorityQueue_Get-1211245106134.3ns/op23B/op0allocs/op
BenchmarkPriorityQueue_PutAndGet-121296203192.24ns/op7B/op0allocs/op
BenchmarkPriorityQueue_PutWithPriorityAndGet-121454376983.70ns/op7B/op0allocs/op
BenchmarkQueue_Put-126102608206.1ns/op71B/op1allocs/op
BenchmarkQueue_Get-123030467545.30ns/op17B/op0allocs/op
BenchmarkQueue_PutAndGet-121717117471.83ns/op7B/op0allocs/op
BenchmarkQueue_Idempotent_Put-121573570706.9ns/op136B/op3allocs/op
BenchmarkQueue_Idempotent_Get-122275533534.4ns/op105B/op0allocs/op
BenchmarkQueue_Idempotent_PutAndGet-122551188494.5ns/op75B/op1allocs/op
BenchmarkRateLimitingQueue_Put-125852602214.0ns/op71B/op1allocs/op
BenchmarkRateLimitingQueue_PutWithLimited-121412991852.6ns/op135B/op2allocs/op
BenchmarkRateLimitingQueue_Get-122818606349.60ns/op19B/op0allocs/op
BenchmarkRateLimitingQueue_PutAndGet-121560067975.69ns/op7B/op0allocs/op
BenchmarkRateLimitingQueue_PutWithLimitedAndGet-121395084855.5ns/op135B/op2allocs/op
项目介绍
WorkQueue https://github.com/shengyanli1982/workqueue
WorkQueue 是一个基于 Go 语言实现的高性能、高可靠、高可扩展的工作队列库,它可以帮助你快速构建一个高性能的工作队列系统,用于处理大量的工作任务。WorkQueue 的 v2 版本是在 v1 版本的基础上进行了全面的重构和优化,主要包括以下几个方面的改进:
-
「排序堆」: WorkQueue的 v2 版本使用了红黑树作为排序堆的实现,保证了堆的稳定性和性能。 -
「接口设计」: WorkQueue的 v2 版本重新设计了接口,使得接口更加简单、直观和易用。 -
「功能设计」: WorkQueue的 v2 版本重新设计了功能,使得功能更加完善、稳定和高效。 -
「代码质量」: WorkQueue的 v2 版本重新设计了代码,使得代码更加简洁、清晰和高质量。
WorkQueue 提供了以下几个主要的队列类型:
-
Queue: 一个基本的工作队列,是项目的基础,也是其他队列的基类。它提供了一个队列的完整功能,包括:入队、出队、遍历、清空等等。 -
DelayingQueue: 一个延迟队列,是在Queue的基础上增加了延迟的功能。 -
PriorityQueue: 一个优先级队列,是在Queue的基础上增加了优先级的功能。 -
RateLimitingQueue: 一个限速队列,是在DelayingQueue的基础上增加了限速的功能。
快速上手
以下是使用 WorkQueue 的快速入门指南。只需按照以下四个步骤进行操作即可:
-
「导入包」
首先,我们需要导入
WorkQueue包。这个包提供了创建和管理工作队列的所有必要功能。importwkq"github.com/shengyanli1982/workqueue/v2" -
「创建队列」
接下来,我们需要创建一个新的队列实例。
NewQueue函数可以接受一个可选的配置参数,这里我们传入nil使用默认配置。queue:=wkq.NewQueue(nil) -
「使用队列」
现在,我们可以开始使用队列了。首先,我们将一个元素(例如字符串 “hello”)放入队列中。然后,我们可以从队列中获取这个元素。
Put方法用于将元素放入队列,而Get方法用于从队列中取出元素。//将"hello"放入队列
_=queue.Put("hello")
//从队列中获取元素
element,_:=queue.Get()在实际应用中,您可以将任何类型的元素放入队列,并根据需要从队列中获取和处理这些元素。
-
「关闭队列」
最后,当我们不再需要使用队列时,可以调用
Shutdown方法关闭队列。这将停止队列的所有操作,并释放相关资源。queue.Shutdown()
通过以上步骤,您已经成功创建并使用了一个 WorkQueue 实例。这个简单的示例展示了如何快速上手使用 WorkQueue,在实际项目中,您可以根据需要进一步扩展和定制队列的功能。
完整示例
以下是一个完整的示例,展示了如何使用 WorkQueue 包来创建和管理工作队列:
「演示代码」
packagemain
import(
"errors"
"fmt"
"sync"
"time"
wkq"github.com/shengyanli1982/workqueue/v2"
)
//consumer函数是一个消费者函数,它从队列中获取元素并处理它们
//Theconsumerfunctionisaconsumerfunctionthatgetselementsfromthequeueandprocessesthem
funcconsumer(queuewkq.Queue,wg*sync.WaitGroup){
//当函数返回时,调用wg.Done()来通知WaitGroup一个任务已经完成
//Whenthefunctionreturns,callwg.Done()tonotifytheWaitGroupthatataskhasbeencompleted
deferwg.Done()
//无限循环,直到函数返回
//Infiniteloopuntilthefunctionreturns
for{
//从队列中获取一个元素
//Getanelementfromthequeue
element,err:=queue.Get()
//如果获取元素时发生错误,则处理错误
//Ifanerroroccurswhengettingtheelement,handletheerror
iferr!=nil{
//如果错误不是因为队列为空,则打印错误并返回
//Iftheerrorisnotbecausethequeueisempty,printtheerrorandreturn
if!errors.Is(err,wkq.ErrQueueIsEmpty){
fmt.Println(err)
return
}else{
//如果错误是因为队列为空,则继续循环
//Iftheerrorisbecausethequeueisempty,continuetheloop
continue
}
}
//打印获取到的元素
//Printtheobtainedelement
fmt.Println(">getelement:",element)
//标记元素为已处理,'Done'是在'Get'之后必需的
//Marktheelementasdone,'Done'isrequiredafter'Get'
queue.Done(element)
}
}
funcmain(){
//创建一个WaitGroup,用于等待所有的goroutine完成
//CreateaWaitGrouptowaitforallgoroutinestocomplete
wg:=sync.WaitGroup{}
//创建一个新的队列
//Createanewqueue
queue:=wkq.NewQueue(nil)
//增加WaitGroup的计数器
//IncreasethecounteroftheWaitGroup
wg.Add(1)
//启动一个新的goroutine来运行comsumer函数
//Startanewgoroutinetorunthecomsumerfunction
goconsumer(queue,&wg)
//将"hello"放入队列
//Put"hello"intothequeue
_=queue.Put("hello")
//将"world"放入队列
//Put"world"intothequeue
_=queue.Put("world")
//等待一秒钟,让comsumer有机会处理队列中的元素
//Waitforasecondtogivethecomsumerachancetoprocesstheelementsinthequeue
time.Sleep(time.Second)
//关闭队列
//Shutdownthequeue
queue.Shutdown()
//等待所有的goroutine完成
//Waitforallgoroutinestocomplete
wg.Wait()
}
「运行结果」
$gorundemo.go
>getelement:hello
>getelement:world
queueisshuttingdown
总结
在这次的经历中,我重新审视了许多基本概念,例如:「排序堆」、「链表」、「接口设计」、「功能设计」、「代码质量」 等等。在这个过程中,我积累了大量宝贵的经验,包括:「如何选择合适的排序堆」、「如何设计高效的链表」、「如何进行接口设计」、「如何设计功能模块」、「如何提升代码质量」 等等。这些经验对我未来的工作和学习都将大有裨益。
经过深入的思考和总结,我认为一个优秀的项目应该具备以下几个特点:
-
「稳定」:保证系统的稳定性,能够在各种情况下正常运行。 -
「易用」:提供良好的用户体验,使用户能够轻松上手。 -
「可扩展」:具备良好的扩展性,能够适应未来的需求变化。
经过一段时间的迭代和优化,WorkQueue 的 v2 版本已经基本实现了上述特点。我们进行了广泛的测试,并在内部生产系统和外部用户的实际应用中得到了验证,证明了其稳定性和可靠性。
我写这篇文章的目的是分享我在开发 WorkQueue 过程中的经验和心得,希望能够帮助到其他开发者。同时,我也希望能够与大家一起完善这个项目。如果你对这个项目感兴趣,欢迎访问我们的仓库,并提出你的建议和意见。我会尽快进行跟进,与大家共同努力,使 WorkQueue 变得更加完善和强大。