
包阅导读总结
1. 关键词:Flink、流式处理、数据源、数据处理、部署
2. 总结:
本文介绍了 Flink 的发展历程、作用、基础概念、入门组件及初步尝试。包括其框架特性、架构分层、支持的数据源,还通过 Docker 部署方式从 MySQL 读取数据的示例,展示了 Flink 的应用过程。
3. 主要内容:
– Flink 简介
– 发展历程:2008 年前身在柏林兴起,2015 年快速发展
– 作用:实时数据分析、数据集成、数据清洗等
– 基础概念
– 框架特性:分布式、高性能、高可用、保证数据准确处理
– 架构分层:Deploy 层、Core 层、API 层、Library 层
– 入门组件:DataSource、Transformation、DataSink
– 初步尝试
– Docker 简易部署:安装 MySQL 和 Flink
– 准备执行的应用:Maven 依赖配置及示例代码
思维导图: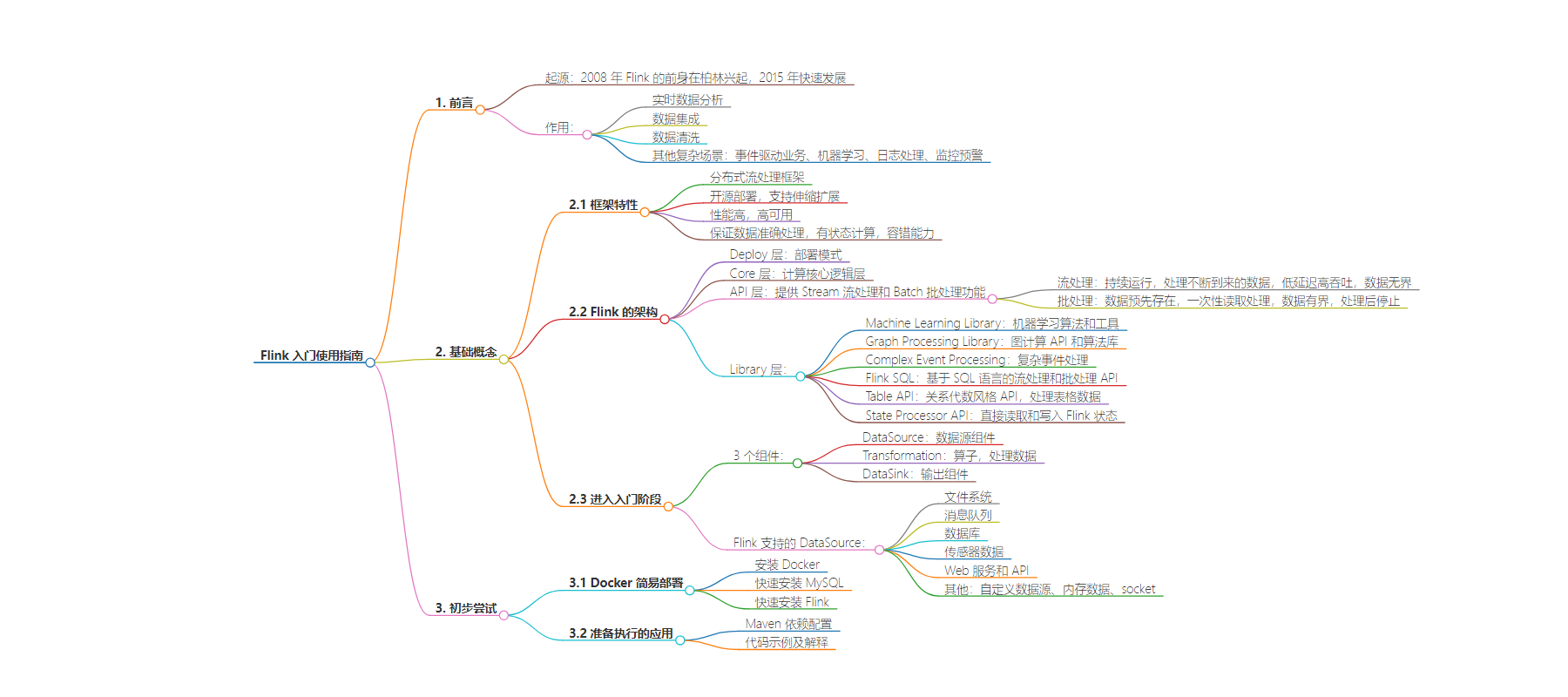
文章地址:https://juejin.cn/post/7396221752600887315
文章来源:juejin.cn
作者:志字辈小蚂蚁
发布时间:2024/7/28 14:54
语言:中文
总字数:2309字
预计阅读时间:10分钟
评分:91分
标签:Flink,流处理,数据分析,Docker,实时数据处理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
一. 前言
早在 2008 年 Flink 的前身就已经再柏林兴起 ,在 2015 年的时候 ,Flink 得到了快速的发展。
Flink 是一个开源的流式处理框架 ,单纯从这个名字上很难看出这个框架的具体作用 ,从案例的角度来说它主要有以下的作用 :
- 实时数据分析 : 对实时数据进行分析和统计 ,提供实时的数据指标
- 数据集成 : 集成多个源的数据 ,进行统一的汇总和处理
- 数据清洗 :对数据进行清洗 ,例如去重,转换等
- 其他更复杂的场景 : 事件驱动业务 / 机器学习 / 日志处理 / 监控预警
二. 基础概念
2.1 框架特性
- Flink 是一个
分布式的流处理框架 ,开源部署运行在多台机器上面 ,支持伸缩扩展 - Flink
性能很高,同时具有高可用的特性 - Flink 可以保证数据被
准确的处理 , 提供有状态的计算 ,具有容错能力
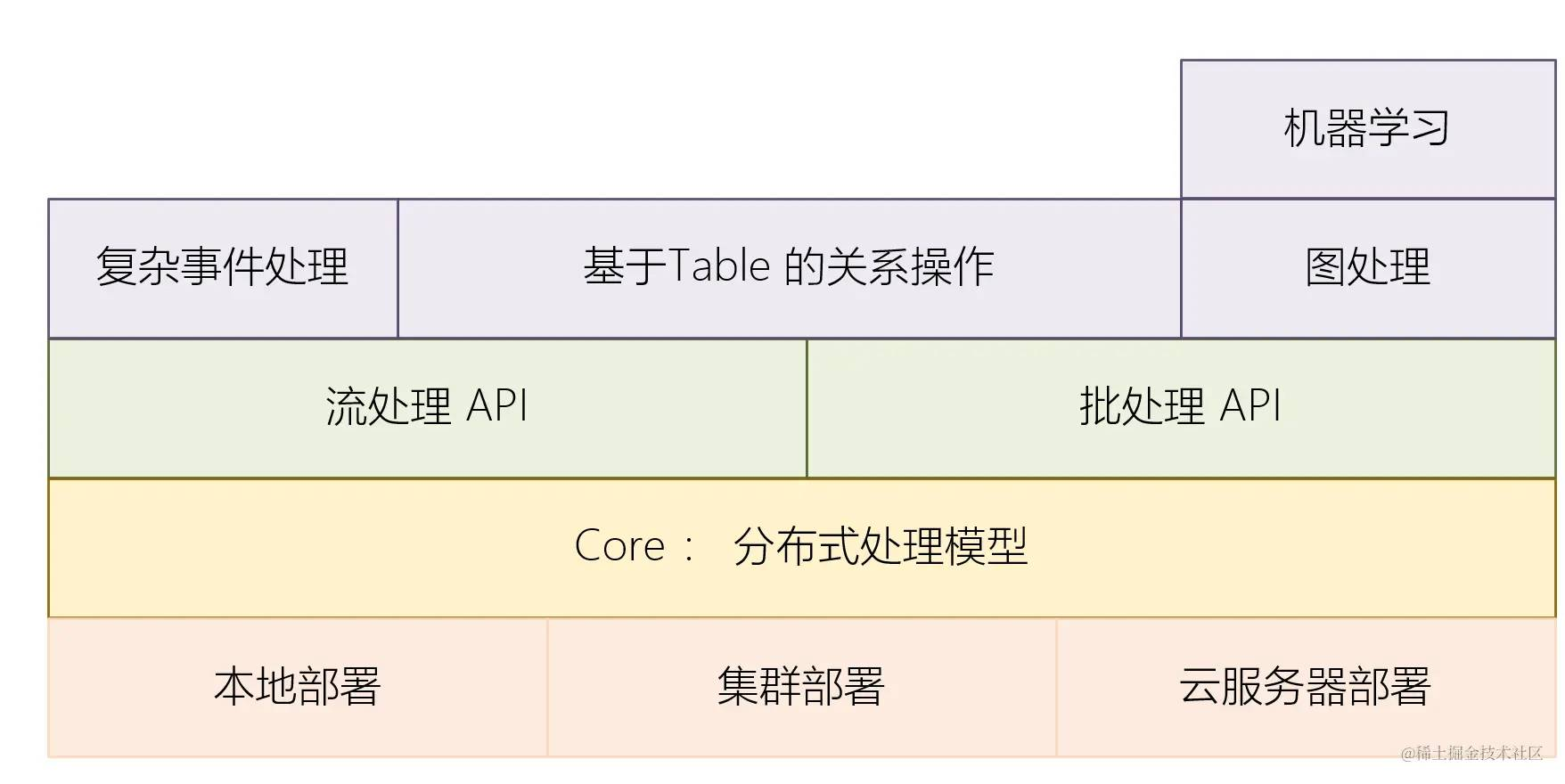
2.2 Flink 的架构
Flink 架构中主要分为四层 :
- Deploy 层 :主要用于 Flink 的部署模式 ,是集群还是本地 ,还是服务器等
- Core 层 : Flink 计算的核心逻辑层 ,提供了 Flink 的基础能力
- API 层 : 提供了
Stream 流处理和Batch 批处理的功能- 流处理 : 持续运行,处理不断到来的数据 。 低延迟高吞吐。
数据无界 ,一直处理。 - 批处理 : 数据是预先存在的,可以一次性全部读取和处理。
数据有界 ,处理后停止。
- 流处理 : 持续运行,处理不断到来的数据 。 低延迟高吞吐。
- Library 层 : 构建在 API 之上 ,用于执行特定的操作
- Machine Learning Library : 提供一系列的机器学习算法和工具
- Graph Processing Library : 提供用于图计算的 API 和算法库
- Complex Event Processing : 提供复杂事件处理的功能,通过定义事件模式,检测事件流中的复杂事件序列
- Flink SQL : 提供基于 SQL 语言的流处理和批处理 API,使用户可以用 SQL 查询来处理数据
- Table API : 提供一个关系代数风格的 API,用于处理表格数据,支持流和批模式
- State Processor API : 允许用户直接读取和写入 Flink 的状态,提供对作业状态的细粒度控制
2.3 进入入门阶段
要使用 Flink ,首先需要了解3个组件 :
- DataSource : 表示数据源组件,主要用来接收数据
- Transformation : 表示算子,主要用来对数据进行处理
- DataSink : 表示输出组件,主要用来把计算的结果输出到其他存储介质中
暂停一下 : 以上组件之间的关系是什么样的?
- 首先 , API 分为 BatchAPI 和 StreamAPI , 他们都是一种模型 ,它的目标是把 DataSource , Transformation 和 DataSink 串联到整个系统中
- DataSource , Transformation 和 DataSink 是具体的业务实现 ,用来实现具体的功能
那么 Flink 支持哪些 DataSource 呢 ?
- 文件系统 : 从本地文件系统或分布式文件系统(如 HDFS)读取数据
- 消息队列 : 从消息队列系统读取数据,例如 Kafka、RabbitMQ 等
- 数据库 : 从关系数据库或 NoSQL 数据库读取数据,例如 MySQL、PostgreSQL、Cassandra 等
- 传感器数据 :从 IoT 设备或传感器读取数据
- Web 服务和 API :调用接口/爬虫, 处理来自 Web 服务的实时数据,例如社交媒体流、天气数据等
- 其他 :自定义数据源 / 内存数据 / socket
用一个简单的 Demo 来说明 :
public class FlinkDatabaseExample { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); JdbcInputFormat jdbcInputFormat = JdbcInputFormat.buildJdbcInputFormat() .finish(); JdbcOutputFormat jdbcOutputFormat = JdbcOutputFormat.buildJdbcOutputFormat() .finish(); DataStream<Tuple2<Integer, String>> sourceStream = env.createInput(jdbcInputFormat); sourceStream.addSink(new RichSinkFunction<Tuple2<Integer, String>>() { @Override public void invoke(Tuple2<Integer, String> value, Context context) throws Exception { jdbcOutputFormat.writeRecord(value); } }); env.execute("Flink Database Example"); }}三. 初步尝试
基于尝试 ,我这里还是选择使用 Docker 部署 ,由于我偷懒不想再部署复杂的环境 ,这里直接尝试从MySQL中进行读取 :
-
- 业务系统不断添加数据到一个固定的表中
-
- Flink 基于 Stream 不断的采集分析文件 , 最终写到另外一个表中
3.1 Docker 简易部署
由于只是测试 ,所以这里采用 Docker 快速部署方式 :
Docker 按照简单贴一下 :
yum list installed | grep dockersudo yum install -y yum-utils device-mapper-persistent-data lvm2sudo yum-config-manager --add-repo https:sudo yum-config-manager --add-repo=http:sudo yum-config-manager --add-repo http: sudo yum install docker-cesudo systemctl start docker快速安装 MySQL
docker pull mysqldocker run -d --name antMySQL -e MYSQL_ROOT_PASSWORD=test9786366 -p 3306:3306 mysqldocker psdocker exec -it antMySQL bashmysql -uroot -ptest9786366快速安装 Flink
pip3 install -U pip setuptoolspip3 install docker-composedocker-compose --versionversion: '3.8'services: jobmanager: image: flink:1.13.2 container_name: jobmanager ports: - "8081:8081" environment: - | FLINK_PROPERTIES= jobmanager.rpc.address: jobmanager command: jobmanager taskmanager1: image: flink:1.13.2 container_name: taskmanager1 environment: - | FLINK_PROPERTIES= jobmanager.rpc.address: jobmanager depends_on: - jobmanager command: taskmanager taskmanager2: image: flink:1.13.2 container_name: taskmanager2 environment: - | FLINK_PROPERTIES= jobmanager.rpc.address: jobmanager depends_on: - jobmanager command: taskmanager
3.2 准备执行的应用
Maven
<dependencies> <!-- Flink dependencies --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.13.2</version> </dependency> <!-- Flink JDBC connector --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-jdbc_2.12</artifactId> <version>1.13.2</version> </dependency> <!-- MySQL connector --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.25</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.12</artifactId> <version>1.13.2</version> </dependency></dependencies><!-- 注意 ,需要把依赖包一起打进去 --><build> <plugins> <!-- Maven compiler plugin --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <!-- Maven shade plugin for creating a fat jar --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2.4</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <createDependencyReducedPom>false</createDependencyReducedPom> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.ant.flink.FlinkMySQLExampleMain</mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins></build>package com.ant.flink;import org.apache.flink.api.common.typeinfo.TypeInformation;import org.apache.flink.api.java.typeutils.RowTypeInfo;import org.apache.flink.connector.jdbc.JdbcExecutionOptions;import org.apache.flink.connector.jdbc.JdbcInputFormat;import org.apache.flink.connector.jdbc.JdbcSink;import org.apache.flink.connector.jdbc.JdbcStatementBuilder;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.types.Row;import java.sql.PreparedStatement;import java.sql.SQLException;public class FlinkMySQLExampleMain { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); JdbcInputFormat jdbcInputFormat = JdbcInputFormat.buildJdbcInputFormat() .setDrivername("com.mysql.cj.jdbc.Driver") .setDBUrl("jdbc:mysql://123.123.123.61:3306/flink-test") .setQuery("SELECT id, name FROM flink_user") .setRowTypeInfo(new RowTypeInfo(TypeInformation.of(FlinkSourceDto.class))) .setUsername("root") .setPassword("123") .finish(); DataStream<Row> sourceStream = env.createInput(jdbcInputFormat); DataStream<FlinkExchangeDto> processedStream = sourceStream.map(value -> { System.out.println("value = " + value); FlinkExchangeDto dto = new FlinkExchangeDto(); dto.setUserId(Long.valueOf((int)value.getField(0)) ); dto.setActivityType("FromUser"); return dto; } ); processedStream.addSink(JdbcSink.sink( "INSERT INTO activity_user (user_id,activity_type) VALUES ( ?,?) ", new JdbcStatementBuilder<FlinkExchangeDto>() { @Override public void accept(PreparedStatement ps, FlinkExchangeDto t) throws SQLException { ps.setLong(1, t.getUserId()); ps.setString(2, t.getActivityType()); } }, JdbcExecutionOptions.builder() .withBatchSize(1000) .withBatchIntervalMs(200) .withMaxRetries(5) .build(), new org.apache.flink.connector.jdbc.JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withUrl("jdbc:mysql://123.123.123.61:3306/flink-test") .withDriverName("com.mysql.cj.jdbc.Driver") .withUsername("root") .withPassword("123") .build() )); env.execute("Flink MySQL Example"); } public static class FlinkSourceDto { private Long id; private Integer age; private String name; private String level; public Long getId() { return id; } public void setId(Long id) { this.id = id; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getLevel() { return level; } public void setLevel(String level) { this.level = level; } } public static class FlinkExchangeDto { private Long userId; private String activityType; public Long getUserId() { return userId; } public void setUserId(Long userId) { this.userId = userId; } public String getActivityType() { return activityType; } public void setActivityType(String activityType) { this.activityType = activityType; } }}3.3 部署应用
- 然后就可以看到执行的项目了 , 可以看到正常和异常的场景
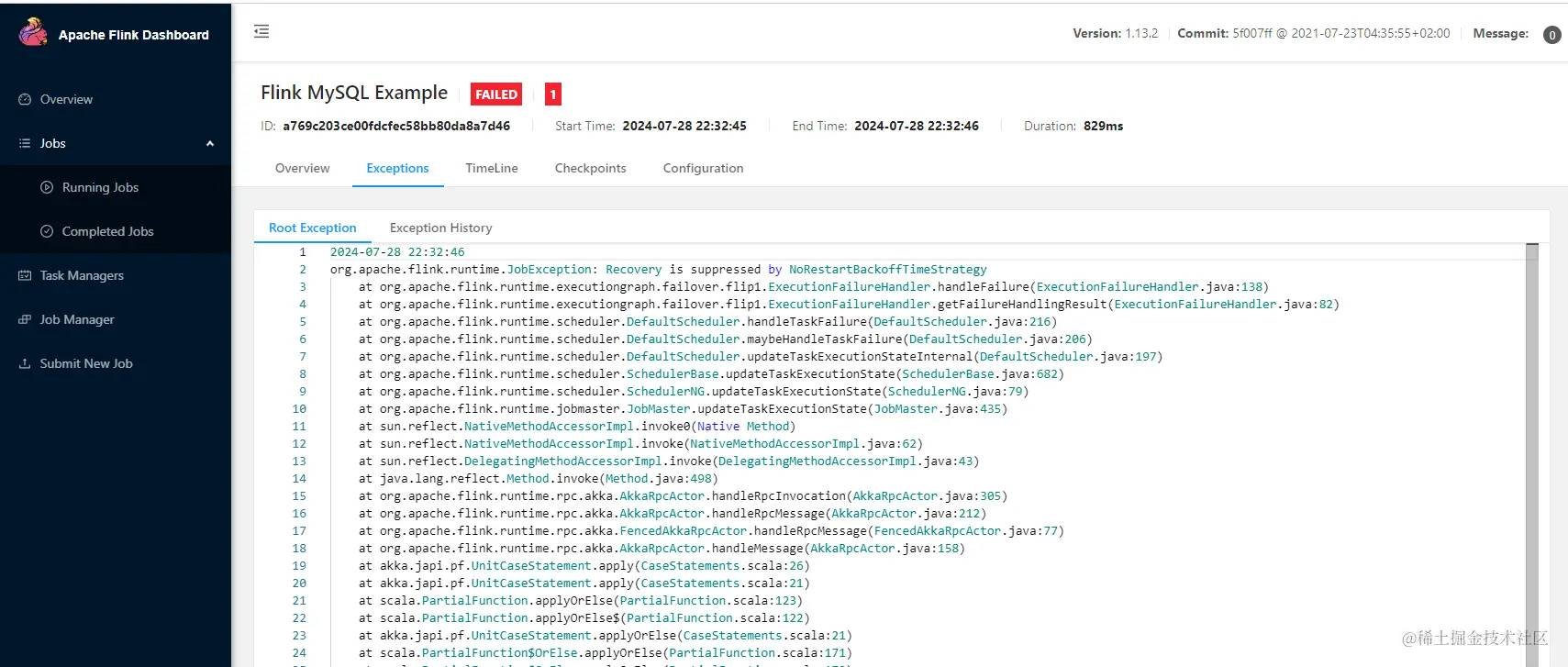
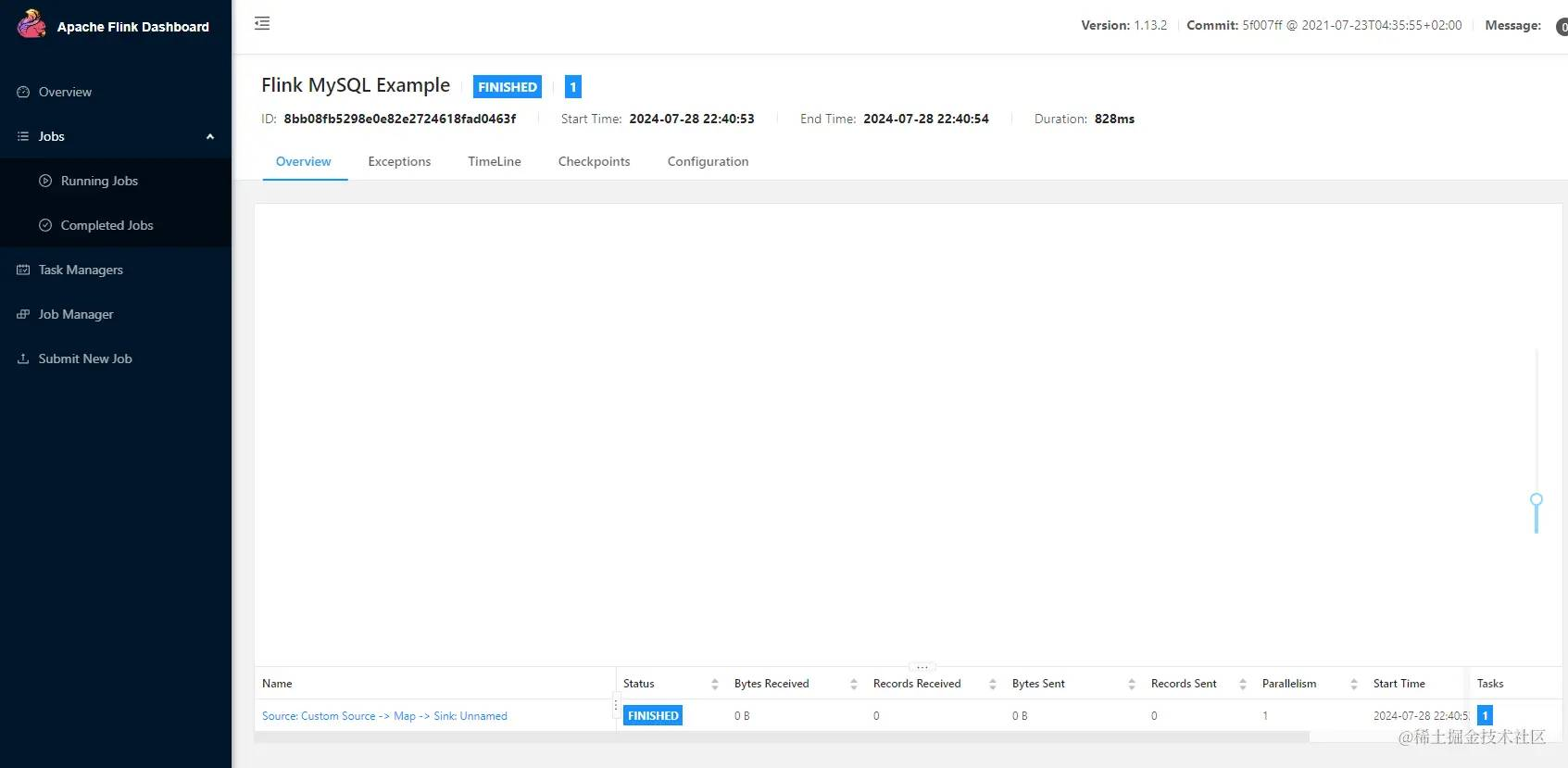
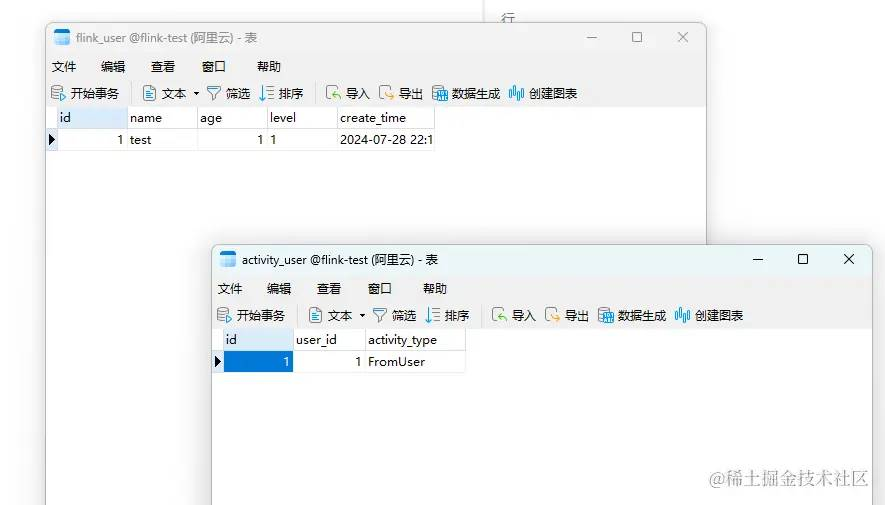
总结
总的来说 ,在数据处理方面 ,Flink 是可以实现的 ,至于性能不在本次讨论的范围内。
而写法也很简单,像写个 Python 脚本一样轻松 ,基于 DataSource 和 Sink 进行 接和收。
👉 这一篇主要的流程就全部走完了 ,后续开始深入的用法 ,其中有以下几个注意点 :
-
- Maven 打包时 ,注意要打入依赖包
-
- 执行时版本号很关键 ,和源不匹配会导致执行失败
-
- 如果 Main 正确 ,不需要手动输入 Main 方法都能扫描出来
-
- Docker 部署需要切对应的加速域 ,否则下的很慢
👉 后续还会深入 :
- Stream 滚动拉取的方式
- Flink 图形界面的用法
- Flink 高阶用法
最后的最后 ❗❗
感谢关注, 其他精品文档索引 : 🔥🔥🔥 系列文章集合