
包阅导读总结
1.
关键词:RDMA、软硬件交互、高性能网络、内存注册、工作原理
2.
总结:本文以 NVIDIA 的 RDMA 网卡为例,介绍其工作原理和软硬件交互机制。对比了 Kernel TCP 与 RDMA 收数据流程,阐述了 RDMA 软件架构,包括用户态驱动、内核态软件栈和驱动等。还讲解了内存注册机制及安全、地址映射等问题,最后分析了 Work Queue 及相关示例。
3.
主要内容:
– RDMA 概述
– 全称远程直接内存访问,为解决网络传输中服务器端数据处理延迟产生
– 消除内存拷贝和上下文切换开销,提升系统性能
– 与 Kernel TCP 对比
– Kernel TCP 收数据流程有三次上下文切换和一次内存拷贝,高性能场景下表现不佳
– RDMA 收数据无上下文切换、数据拷贝、协议栈处理和内核参与,CPU 可专注处理数据和业务逻辑
– RDMA 软件架构
– 用户态驱动:提供 Verbs API 等
– 内核态 IB 软件栈:提供统一接口
– 内核态驱动:厂商实现,与硬件交互
– 内存注册
– PD:类似租户 ID,隔离资源
– MR:包括 PD、lkey、rkey 等属性,注册后内存才能被使用
– 注册阶段:用户态调用通过内核转换到设备驱动,创建 mkey 对象
– Work Queue
– 分为 SQ、RQ、CQ 和 EQ 等
– 示例展示 ibv_post_send 和 ibv_poll_cq 用途
– NVIDIA 网卡上 ibv_post_send 最终调用相关操作,网卡收到通知后执行发送和通知软件
思维导图: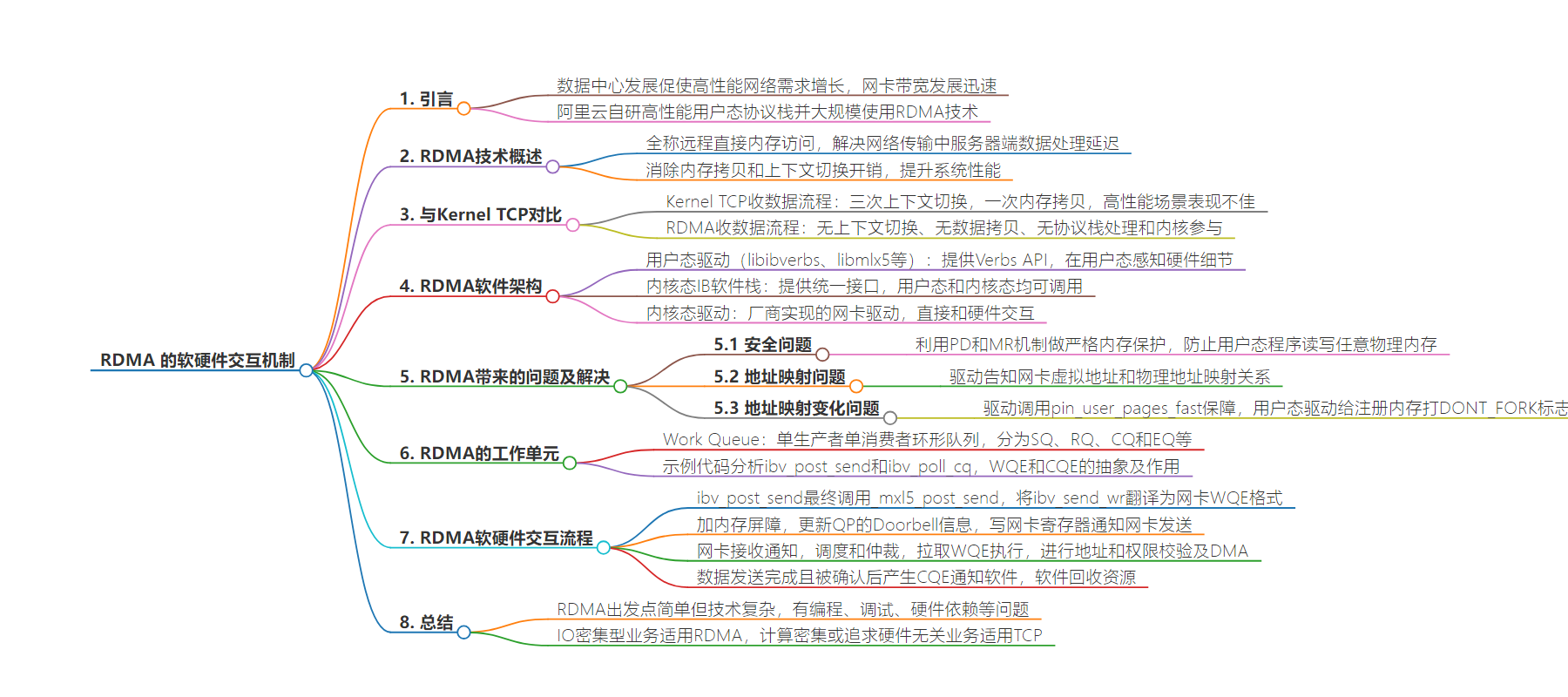
文章地址:https://mp.weixin.qq.com/s/LaMp5ux5TmwKNw0gx_e3QQ
文章来源:mp.weixin.qq.com
作者:羽京
发布时间:2024/8/6 8:59
语言:中文
总字数:4299字
预计阅读时间:18分钟
评分:83分
标签:RDMA,高性能网络,云计算,软硬件交互,内存管理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

这是2024年的第56篇文章
( 本文阅读时间:15分钟 )
随着数据中心的飞速发展,高性能网络不断挑战着带宽与时延的极限,网卡带宽从过去的 10 Gb/s 、25 Gb/s 到如今的 100 Gb/s、200 Gb/s 再到下一代的 400Gb/s 网卡,其发展速度已经远大于 CPU 发展的速度。
为了满足高性能网络下的通信需求,阿里云不仅自研了高性能用户态协议栈 (Luna、Solar) ,也大规模使用了 RDMA 技术,以充分利用高性能网络。尤其是在存储和 AI 领域,RDMA 被广泛使用。相比于 Kernel TCP 提供的 Socket 接口,RDMA 的抽象更为复杂,为了更好的使用 RDMA,了解其工作原理和机制是必不可少的。
本文以 NVIDIA (原 Mellanox)的 RDMA 网卡为例,分析其工作原理和软硬件交互的机制。
-
网卡驱动从内核分配 dma buffer,填入收队列 -
网卡收到数据包,发起 DMA,写入收队列中的 dma buffer -
网卡驱动查看收队列,取出 dma buffer,交给协议栈
int num_devices = 0, i;struct ibv_device ** device_list = ibv_get_device_list(&num_devices);struct ibv_device *device = NULL;for (i = 0; i < num_devices; ++i) {if (strcmp("mlx5_bond_0", ibv_get_device_name(device_list[i])) == 0) {device = device_list[i];break;}}struct ibv_context *ibv_ctx = ibv_open_device(device);struct ibv_pd* pd = ibv_alloc_pd(ibv_ctx);void *alloc_region = NULL;posix_memalign(&alloc_region, sysconf(_SC_PAGESIZE), 8192);structibv_mr*reg_mr=ibv_reg_mr(pd,alloc_region,mr_len,IBV_ACCESS_LOCAL_WRITE);
echo "file mr.c +p" > /sys/kernel/debug/dynamic_debug/controlecho "file mem.c +p" > /sys/kernel/debug/dynamic_debug/control
infiniband mlx5_0: mlx5_ib_reg_user_mr:1300:(pid 100804): start 0xdb1000, virt_addr 0xdb1000, length 0x2000, access_flags 0x100007infiniband mlx5_0: mr_umem_get:834:(pid 100804): npages 2, ncont 2, order 1, page_shift 12infiniband mlx5_0: get_cache_mr:484:(pid 100804): order 2, cache index 0infiniband mlx5_0: mlx5_ib_reg_user_mr:1369:(pid 100804): mkey 0xdd5dinfiniband mlx5_0: __mlx5_ib_populate_pas:158:(pid 100804): pas[0] 0x3e07a92003infinibandmlx5_0:__mlx5_ib_populate_pas:158:(pid100804):pas[1]0x3e106a6003
结合内核模块的代码分析,内存注册大致有这几个阶段:
mkey0xdd5dvirt_addr 0xdb1000, length 0x2000, access_flags 0x100007pas[0] 0x3e07a92003pas[1] 0x3e106a6003
-
不能,RDMA 通过 PD 和 MR 机制做了严格的内存保护。
-
驱动会告诉网卡映射关系,后续数据流中,网卡自己转换。
-
通过驱动调用 pin_user_pages_fast 保障。另外,用户态驱动会给注册的内存打上 DONT_FORK 的标志,避免 Copy-On-Write 发生。
-
软件构造 WQE (Work Queue Element),提交至 Work Queue 中
uint32_t send_demo(struct ibv_qp *qp, struct ibv_mr *mr){struct ibv_send_wr sq_wr = {}, *bad_wr_send = NULL;struct ibv_sge sq_wr_sge[1];sq_wr_sge[0].lkey = mr->lkey;sq_wr_sge[0].addr = (uint64_t)mr->addr;sq_wr_sge[0].length = mr->length;sq_wr.next = NULL;sq_wr.wr_id = 0x31415926;sq_wr.send_flags = IBV_SEND_SIGNALED;sq_wr.opcode = IBV_WR_SEND;sq_wr.sg_list = sq_wr_sge;sq_wr.num_sge = 1;ibv_post_send(qp, &sq_wr, &bad_wr_send);struct ibv_wc wc = {};while (ibv_poll_cq(qp->send_cq, 1, &wc) == 0) {continue;}if (wc.status != IBV_WC_SUCCESS || wc.wr_id != 0x31415926) {exit(__LINE__);}return 0;}
-
ibv_send_wr 这个是 SQ 的 WQE 的抽象(不同厂商的网卡 WQE 格式不同) -
ibv_sge 是数据的抽象,包含 (addr,len,lkey) 三个字段 -
ibv_wc 是 CQE 的抽象,通过 wr_id 和 ibv_send_wr 对应起来
dump wqe at 0x7fc59b3570000000000a 00115003 00000008 0000000000000000 c0000000 00000000 000000000000022a 00008a0b 00007fc5 9a5b2000mlx5_get_next_cqe:565: dump cqe for cqn 0x4c2:00000000 00000000 00000000 0000000000000000 00000000 00000000 0000000000000000 00000000 00000000 0000000000004863 2a39b102 0a001150 00003f00
*(uint64_t)(bf->reg + bf->offset) = *(uint64_t *)ctrl;
[02]NVIDIA 网卡手册:
https://network.nvidia.com/files/doc-2020/ethernet-adapters-programming-manual.pdf