
包阅导读总结
1. `React`、`Vue`、`Diff 算法`、`列表处理`、`节点比较`
2. 本文主要对比 React 与 Vue 的 Diff 算法,指出面试常问其区别但实际开发中用处不大。算法设计基于假说减少问题复杂性,两者在比较策略上相似,包括同层比较和节点比较,最大区别在列表处理上,分别介绍了 React 和 Vue 的处理方式。
3.
– 背景
– 作者因接广告被吐槽,爆肝写面试干货。
– 面试常问 React 与 Vue 的 Diff 算法区别,虽对开发能力提升不大但仍需回答。
– Diff 算法设计
– 基于假说减少问题复杂性,因 DOM 操作复杂,React 和 Vue 放弃识别父子节点移动情况。
– 比较策略
– 同层比较:只比较相同层级节点,不同则默认为该节点以下全部变化需重新创建。
– 节点比较:React 与 Vue 处理策略类似,节点分为默认 DOM 节点和自定义节点,列表结构优先比较 key 值。
– 列表处理
– 都采用唯一 key 值,不能用递增数字序列,否则会导致渲染混乱。
– React 比较方式通过 lastIndex 和 index 判断节点是否移动。
– Vue 双端比较通过 4 个指针和比较规则减少真实 DOM 移动次数,Vue3 采用新处理方式。
– 总结
– 对比了 React 和 Vue 在 Diff 算法上的异同,Vue 算法对渲染性能提升效果微弱。
思维导图: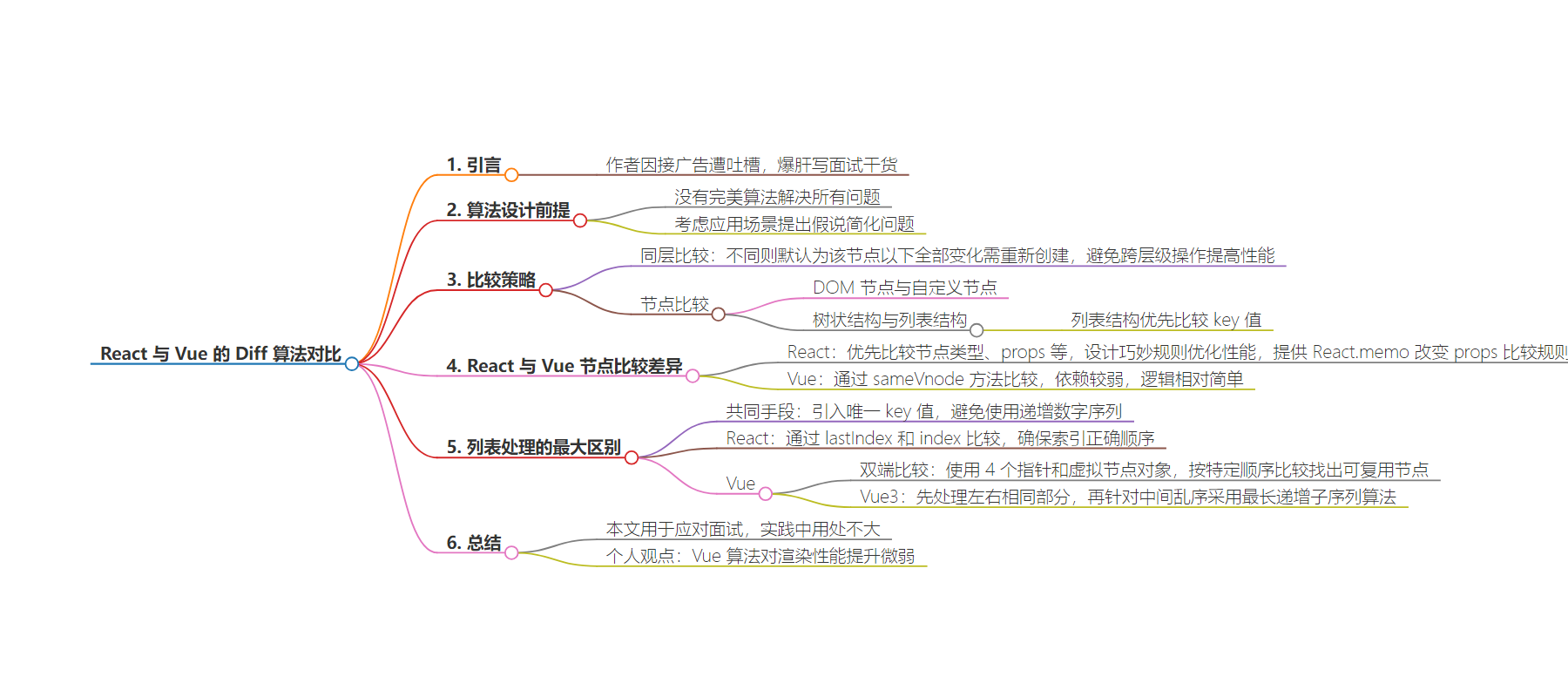
文章地址:https://mp.weixin.qq.com/s/77-bWVnnfTMDzplPr28gVg
文章来源:mp.weixin.qq.com
作者:这波能反杀丶
发布时间:2024/8/5 7:04
语言:中文
总字数:5825字
预计阅读时间:24分钟
评分:86分
标签:React,Vue,Diff 算法,性能优化,前端框架
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
昨天接了个广子,恰了点饭。你们的吐槽我的认了,哎呀,你们都说得对。所以我今晚连夜爆肝写了一篇专门用来面试的干货,总计 7000 字左右,分享给大家,必须要抢救一下想要取关的大佬们!
许多朋友会在简历上同时写自己会 React、Vue,但是倒霉的面试官一看到这种简历,就喜欢问它们有什么区别。其中频率比较高的一个问题就是 React 与 Vue 的 diff 算法有啥相同之处和不同之处…
很显然,这种问题对于面试考验开发者能力而言,没啥营养,就算知道了,对开发能力也不会有什么明显的提高,还不如更具体的问 key 值有什么用呢,但是没办法,有的面试官就是爱问,既然这样,那我们就答给他们看。
假说论
我们在思考算法问题的时候,一定要谨记一个前提,那就是没有完美的算法可以解决所有问题。 因此,在设计一个算法时,我们需要充分考虑应用场景,然后提出一个假说,从而极大地减少问题的复杂性,让解决方案变得更加简单。
在 React/Vue 的 diff 算法中,当我们要对比前后两棵树的差异时,我们的目标是尽可能少的创建节点。但是由于 DOM 操作的可能性太复杂了,因此如果要全部对比出来,复杂度就非常高。达到了 O(n^ 3) 这个级别。
之所以这么复杂的原因,就是因为节点不仅可以增加删除,还可以移动。我们要分辨节点是否从子元素移动到了父元素,或者增加了一个父元素,判断过程非常复杂。因此,在设计 dfiff 算法的时候,React/Vue 都放弃了这种情况的识别。
他们根据实际情况提出的假说是:在实际情况中,整棵 DOM 树里,关于父子节点移动的情况是比较少的,因此,没有必要为了这种少部分情况加剧算法的压力。只要放弃识别这种情况,算法就能够得到极大的简化。
几乎相同的比较策略
在上面我们提到的假说论之下,React/Vue 在 diff 算法上,都使用了非常类似的策略。
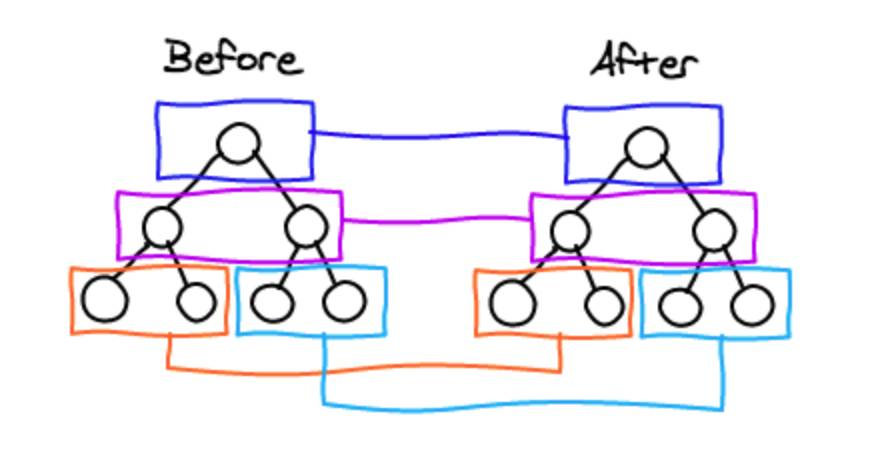
一、同层比较
如下图所示,diff 算法只需要比较相同层级的节点是否相同
比较之后有两种情况
-
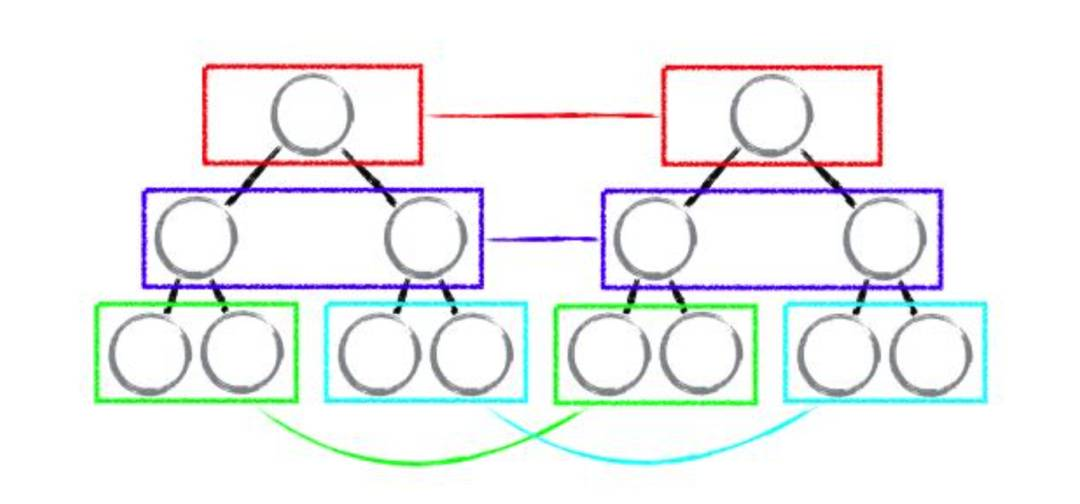
如果不同:则直接默认为从该节点开始,以下的全部节点都发生了变化,需要重新创建。
如下图所示,虽然节点只是发生了移动,但是在 diff 过程中,会被认为 A 节点已经被删除,然后重新创建它。
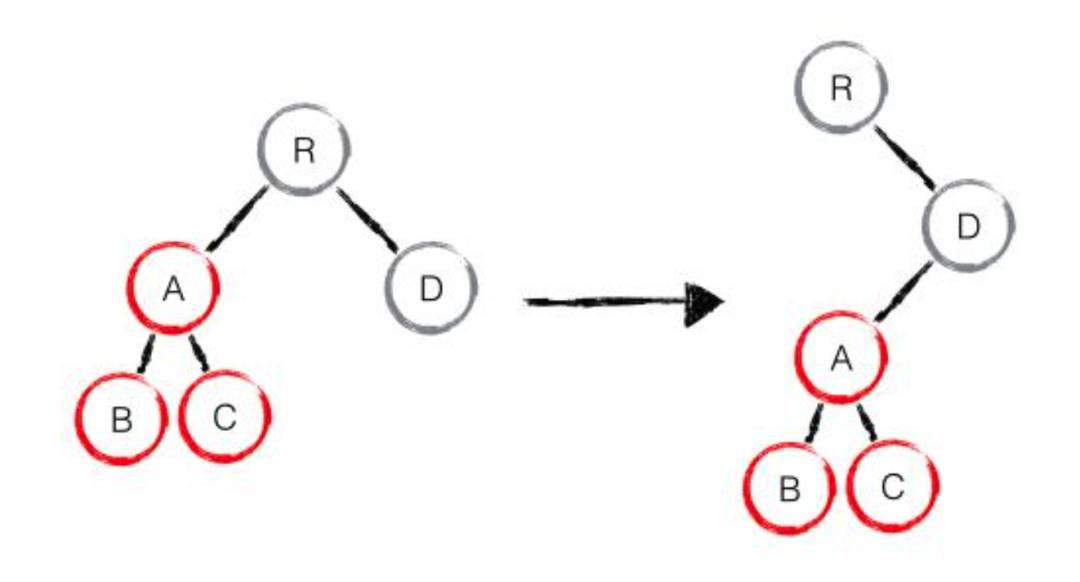
因此,在开发过程中,我们可以通过避免跨层级操作节点的方式,来提高你应用程序的性能。
二、节点比较
在对比节点是否相同时,React 与 Vue 的处理策略也比较类似。了解节点的比较方式,是我们在做性能优化时的重要依据。
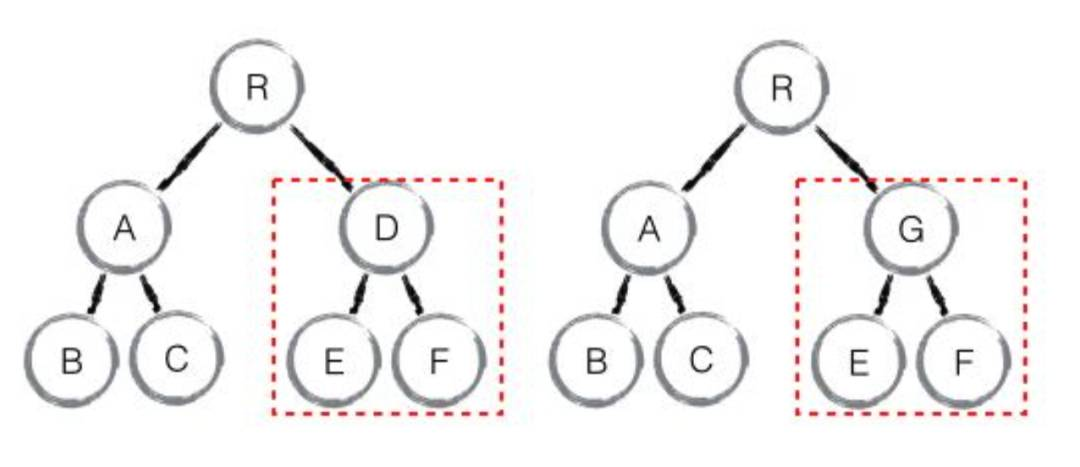
节点比较有两种情况,一种节点是默认支持的 DOM 节点,一种是通过自定义创造出来的自定义节点,在 React 中会区分这两种情况,但是在 Vue 中会统一只识别标签名 tag。
除了这个情况之外,在结构类型上,还分为两种情况,一种是正常的树状结构,另外一种是列表结构。列表结构通常情况下我们就不能直接忽视移动这种情况。因此,针对于这种列表结构,React 和 Vue 都优先提倡使用传入 key 值的方式进行标记,从而极大地减小比较压力。
因此,在列表节点的比较中,React、Vue 都优先比较 key 值。
!
不过针对列表的比较方式处理,是 React 和 Vue 在 diff 算法上最大的差别。我们后面单独介绍
然后,在 React 中,diff 算法会优先比较节点类型是否相同。例如下面的代码,div 与 span 属于不同的节点类型,那么就表示不是同一个节点。
<div>
<Counter/>
</div>
<span>
<Counter/>
</span>
然后会比较 props、state、context 等外部传入的参数是否相同,从而判断是否是同一个节点。当然,这里还有一个重要的细节,对于性能优化至关重要。
由于在 React 中,props 的传入都是通过类似于函数传参的方式传入,例如
functionCounter({a:1}){...}
前后两次执行
Counter({a:1})
Counter({a:1})
这里的细节就是,虽然两次都入参都是 {a: 1},但是他们是不同的内存地址,因此前后两次 props 的比较结果始终为 false
{a:1}==={a:1}//false
如果不解决这个问题,任何比较方式都是没有意义的,结果都是为 false。
所以这里 React 设计了一个巧妙的规则,那就是当我们判定元素节点的父节点未发生变化时,就不比较 props,从而跳过 props 的比较,来提高性能。我们可以利用这样的特性在 React 中写出性能非常高的代码。
除此之外,React 还设计了一个 api,React.memo,该 api 可以改变 props 的比较规则。使用方式如下所示,memo 接收组件声明作为参数
functionCounter({a:1,b:2}){...}
exportdefaultReact.memo(Counter)
使用 memo 包裹之后,props 的比较规则变成了依次比较第一层 key 值所对应的值。例如,上面的案例中,包裹之前的比较方式为
{a:1,b:2}==={a:1,b:2}//始终为false
包裹之后的比较方式为
p1.a===p2.a&&p1.b===p2.b//true
因此,在特定的场景中,使用 memo 可以有效命中可复用节点。
在 Vue 中,由于并不是那么强依赖 diff 算法,因此它的节点比较逻辑相对而言会简单直接一些,通过一个 sameVnode 方法来比较节点是否相同。
//Vue2/src/core/vdom/patch.js
//主要通过对key和标签名做比较
functionsameVnode(a,b){
return(
a.key===b.key&&//标签名是否一样
a.asyncFactory===b.asyncFactory&&(//是否都是异步工厂方法
(
a.tag===b.tag&&//标签名是否一样
a.isComment===b.isComment&&//是否都为注释节点
isDef(a.data)===isDef(b.data)&&//是否都定义了data
sameInputType(a,b)//当标签为input时,type必须是否相同
)||(
isTrue(a.isAsyncPlaceholder)&&//是否都有异步占位符节点
isUndef(b.asyncFactory.error)
)
)
)
}
functionsameInputType(a,b){
if(a.tag!=='input')returntrue
leti
consttypeA=isDef((i=a.data))&&isDef((i=i.attrs))&&i.type
consttypeB=isDef((i=b.data))&&isDef((i=i.attrs))&&i.type
returntypeA===typeB||(isTextInputType(typeA)&&isTextInputType(typeB))
}

这里需要注意的是,如果我们要详细的聊清楚 React 和 Vue 在节点是否相同的比较方式上时,就要明白 React 是强依赖于这个,但是 Vue 依赖较弱,因为 Vue 的实现原理中更多的是通过依赖收集的方式来找到需要更新的节点,这也导致了 React 在这个上面的逻辑要更加复杂,Vue 则更加简单。因此,我们需要对他们各自的原理背景有一定的了解。
最大的区别,在列表上的处理

列表是性能问题频发的重要场景,因此,React 和 Vue 都针对长列表设计了特殊的处理方式。在聊之前,我们要明确处理场景,那就是,在列表中,我们就不能再忽视节点位置的移动了。
因为,一个简单的移动,就很容易会造成整个组件被判定为需要全部重新创建。所以,我们需要判断出来节点是只发生了移动,而不是需要重新创建。
给列表中的每一个节点,引入唯一 key 值,是他们都共同采用的技术手段。通过唯一key 值,我们可以在旧列表中找到新列表的节点是否已经存在,从而决定是移动节点的位置还是创建新的节点。我们通常会在数组中设定一个 id 用于表示唯一 key 值。
consttodoItems=todos.map((todo)=>
<likey={todo.id}>
{todo.text}
</li>
);
需要注意的是,这里的唯一 key 值,尽量不要使用递增的数字序列来表示。
consttodoItems=todos.map((todo,index)=>
//OnlydothisifitemshavenostableIDs
<likey={index}>
{todo.text}
</li>
);
这个问题也是面试中经常会聊到的话题:为什么尽量不要使用 index 序列作为 key。这是因为当我们在列表中新增一个内容时,每一项的 index 每次都会发生变化,从而让渲染结果出现混乱。
例如有一个数组为 [a, b, c],此时我们将 index 作为key值,那么数组项与 key 值的对应关系就是
[a:0,b:1,c:2]
此时,我们往数组头部添加一个数据,这个时候数组变成了 [p, a, b, c],然后再执行,数组项与 key 的对应关系就变成了
[p:0,a:1,b:2,c:3]
新增的项是 p,但是最终导致了数组项与key 之间的对应关系错乱,结果导致缓存的节点挂到了错误的数组项上去了。我们可以通过如下案例演示观察在 UI 上的表现差别
首先,我们的默认情况如下,上面的列表使用 index 作为 key 值,下面的列表使用 唯一 id 作为key 值。
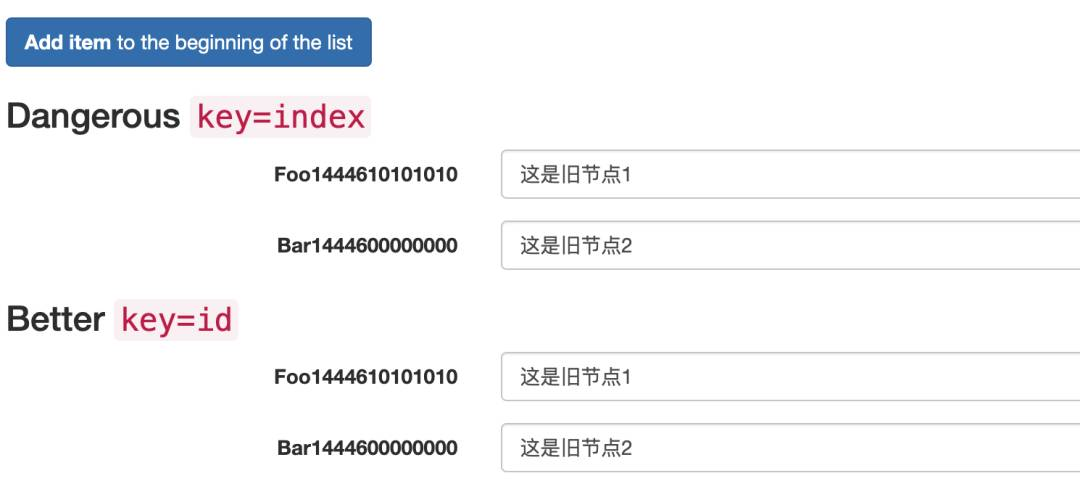
当我新增一个项时,仔细观察两个列表的差异。

在引入了 key 值之后,为了追求在某些情况下更少的移动次数,Vue 中使用了更复杂的算法设计:双端比较以及最长子序列递增,这是他们最大的区别。
React 的比较方式
首先,我们假定有一个已经渲染好的列表节点如下
//使用_表示旧节点列表
[_A][_B][_C][_D]
然后,我们在 A 的前面新增的了一个节点,P,理想的结果如下所示
[P][A][B][C][D]
在比较的过程中,我们会首先创建一个变量 lastIndex,默认值为 0。然后使用一个指针 index 用来记录新数组中的当前项在旧列表中的索引值。
在比较的过程中,lastIndex 的变化规则如下
lastIndex=max(index,lastIndex)
例如,我们开始遍历新数据 [P, A, B, C D]
1、第一个目标项为 P,我们会去旧列表中查询是否存在相同的 key=P 的项。发现没有,此时创建新节点
lastIndex=0
[P]
2、第二个目标项为 A,我们去旧列表中查询是否存在相同的,发现有,此时 index = 0,可复用节点
当满足条件 index < lastIndex 时,移动节点。此时 index = 0,lastIndex = 0,不满足条件,不移动,此时结果为
//结果为0
lastIndex=max(index,lastIndex)
[P][A]
i
注意:这里说的移动节点,指的是对真实 DOM 的操作。
✓
这里需要多花点时间感受一下这个判断条件的合理性,
index < lastIndex,他是为了确保索引的正确顺序而设计的规则
3、第三个目标项为 B,我们去旧列表中查询是否存在相同的key,发现有,此时 index = 1,可复用节点
不满足 index(1) < lastIndex(0),不移动,结果为
//结果为1
lastIndex=max(index,lastIndex)
[P][A][B]
依次类推,最终我们发现,这种情况下,只需要创建一个新节点 P,不需要移动任何节点。
第二个案例
新旧列表节点如下
旧列表:[A][B][C][D]
新列表:[B][A][D][C]
新的数据为 [B, A, D, C]
1、第一个目标节点为 B,发现在旧列表中存在相同 key,那么复用节点,此时,index = 1,当前结果为
index=1
lastIndex=0
index<lastIndex//false,不移动
lastIndex=max(index,lastIndex)//1
[B]
2、第二个目标节点为 A,发现在旧列表中存在相同 key,那么复用节点,此时,index = 0,当前结果为
index=0
lastIndex=1
index<lastIndex//true,移动
lastIndex=max(index,lastIndex)//1
[B][A]
3、第三个目标节点为 D,发现在旧列表中存在相同 key,那么复用节点,此时,index = 3,当前结果为
index=3
lastIndex=1
index<lastIndex//false,不移动
lastIndex=max(index,lastIndex)//3
[B][A][D]
4、第四个目标节点为 C,发现在旧列表中存在相同 key,那么复用节点,此时,index = 2,当前结果为
index=2
lastIndex=3
index<lastIndex//true,移动
lastIndex=max(index,lastIndex)//3
[B][A][D][C]
这个案例在 diff 之后,只需要真实 DOM 移动两次节点。就可以完成更新了。
相信通过这两个案例,大家应该能掌握 React 在列表中的对比规则,接下来,我们来了解一下 Vue 的双端对比。
Vue 双端比较
Vue 的双端对比的设计有一个目标,那就是在特定的场景之下,减少真实 DOM 的移动次数。我们来看一下这样一种场景。
旧:[A][B][C][D]
新:[D][A][B][C]
如果按照 React 的比较规则,此时由于第一个目标 D 的 index 为 3,从一开始就变成了最大,因此,后续的 lastIndex 都为 3,所有的目标项都会满足 index < lastIndex,因此,真实 DOM 的移动就会执行 3 次。
而 Vue 提出的双端比较,目标就是希望可以识别出来这种情况,只需要让移动只发生一次即可。就是 D 从最末尾移动到最前面。
双端比较会使用 4 个指针,分别记录旧列表和新列表的首尾两个节点位置。
letoldStartIdx=0
letoldEndIdx=prevChildren.length-1
letnewStartIdx=0
letnewEndIdx=nextChildren.length-1
以及对应的虚拟节点对象
letoldStartVNode=prevChildren[oldStartIdx]
letoldEndVNode=prevChildren[oldEndIdx]
letnewStartVNode=nextChildren[newStartIdx]
letnewEndVNode=nextChildren[newEndIdx]
比较的规则遵循:首-首比较,尾-尾比较,尾-首比较,首-尾比较的顺序。通过这样方式找出首尾是否有节点可以被复用。
while(oldStartIdx<=oldEndIdx&&newStartIdx<=newEndIdx){
if(oldStartVNode.key===newStartVNode.key){
//...
}elseif(oldEndVNode.key===newEndVNode.key){
//...
}elseif(oldStartVNode.key===newEndVNode.key){
//...
}elseif(oldEndVNode.key===newStartVNode.key){
//...
}
}
例如下面案例
旧:[A][B][C][D]
新:[D][A][B][C]
在首次经过四次比较之后,发现 新首-旧尾 key 值相同,可以复用,此时需要通过移动首尾索引指针构建新的新旧节点数组
//发现复用节点,update
patch(oldEndVNode,newStartVNode,container)
//移动
container.insertBefore(oldEndVNode.el,oldStartVNode.el)
//更新索引指针
oldEndVNode=prevChildren[--oldEndIdx]
newStartVNode=nextChildren[++newStartIdx]
然后新的新旧数组为
旧:[A][B][C]-[D]
新:-[D][A][B][C]
演变为
旧:[A][B][C]
新:[A][B][C]
得到新的新旧数组,继续重复首-首比较,尾-尾比较,尾-首比较,首-尾比较。直到比较结束。
指针的移动方向,总体趋势是从两端往中间移动。
这里需要特别注意的是,这样的比较方式虽然快,但这是不充分比较,因此,在许多情况下,会导致节点存在复用,但是没有找出来。因此,如果没找到可复用的节点,比较还没有结束,还有后续的逻辑。
我们构建一个新的案例,如下所示
旧:[A][B][C][D]
新:[B][D][A][C]
此时我们发现,通过首位的 4 次比较,结果一个可复用的节点都没找到,因此,此时需要回过头来重新完整的遍历,以新首 key 为当前目标,去旧列表中依次查找是否存在可复用节点
在这个案例中,可以找到,那么,我们就把 B 移动到首位
旧:[A]-[B][C][D]
新:-[B][D][A][C]
移动之后,通过改变指针位置,再将新的双端列表演变为
旧:[A][C][D]
新:[D][A][C]
然后再以新尾 key 作为当前目标,去旧列表中依次遍历找寻。可以找到 C,将 C 移动到尾部。然后依次类推。
最后,如果双端对比结束之后,旧列表中还存在节点,则表示这些节点需要被批量删除
如果对比结束之后,新列表中还存在节点,则表示这些节点需要批量新增,简单处理即可。
Vue3 中的处理方式又发生了变化,但是时间来不及太详细的分析了,我这里就简单说一下,可以用于面试的术语:
先处理左侧相同部分,再处理右侧相同部分,锁定可复用的节点之后,再针对中间乱序部分,采用最长递增子序列的算法,计算出乱序部分可以复用的最长连续节点。通过这个递增数组,我们就可以知道哪些节点在变化前后的相对位置没有发生变化,哪些需要移动。
✓
关于最长递增子序列大家可以通过力扣的算法题了解。涉及到的动态规划、二分、回朔等方式在评论都有大量的提到。他的目标依然是为了减少真实 DOM 的移动次数
https://leetcode.cn/problems/longest-increasing-subsequence/description/
总结
本文比较了 React 和 Vue 在 diff 算法上的相同的考虑与差异的处理,主要的作用是为了应对面试中的场景,在实践应用场景中用处不是很大。大家可以收藏起来慢慢看。
我在最后用了非常大量的篇幅介绍 React 与 Vue 在列表中对比的差异,Vue 由于在努力追求真实 DOM 能够以最小的移动来更新 DOM,因此在算法上更加特殊。
不过需要特别注意的是,在同一次事件循环中,由于浏览器在渲染时本身就会对 DOM 树进行统一的处理和绘制,因此,节点移动 1 次,还是移动 100 次,只要在这一帧中的最终结果是一样的,那么在渲染阶段所消耗的计算成本实际上是一样的,没有太大的区别。因此,我个人的观点是 Vue 这种算法对于渲染性能的提升效果应该是非常微弱的。
成为 React 高手,推荐阅读 React 哲学
大量可演示案例,沉浸式学习,推荐阅读 React 19
–END-
如果您关注前端+AI 相关领域可以扫码进群交流


扫码进群2或添加小编微信进群1😊
关于奇舞团
奇舞团是 360 集团最大的大前端团队,非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。
