
包阅导读总结
1. 关键词:AI 栈、基础模型、研究与实践、POLM 栈、代理系统
2. 总结:
本文探讨了 AI 栈的演变,从基础构建到如今助力开发者快速大规模构建 AI 应用,包括其发展历程、关键组件、POLM 栈特点,以及向代理系统的演进趋势。
3. 主要内容:
– AI 栈的出现
– 随着 AI 发展,出现旨在简化 AI 应用开发管理的“AI 栈”。
– 快速发展,基于现有技术,需回顾其出现过程。
– 基础构建
– 传统 AI 开发涉及回归和分类模型。
– 典型工具多样,但无既定通用栈。
– 研究与应用曾有差距,直到新技术出现。
– 缩小研究与实践差距
– GPT 系列等模型推动差距缩小。
– 新工具促进研究和应用,数据和计算设备发展助力。
– LLM 供应生态系统有变化。
– 剖析 AI 栈
– 是工具、解决方案和组件的集成。
– 包括多种关键组件,从编程语言到部署方案。
– 代表从传统机器学习到新生态系统的进化。
– POLM AI 栈
– 由 Python 等构成,用于开发现代 AI 应用。
– 提供开发框架,具有统一数据库架构等特点。
– 有相关教程展示其使用。
– 面向代理系统的 AI 栈
– 从聊天机器人向代理系统演进,受基础模型能力推动。
思维导图: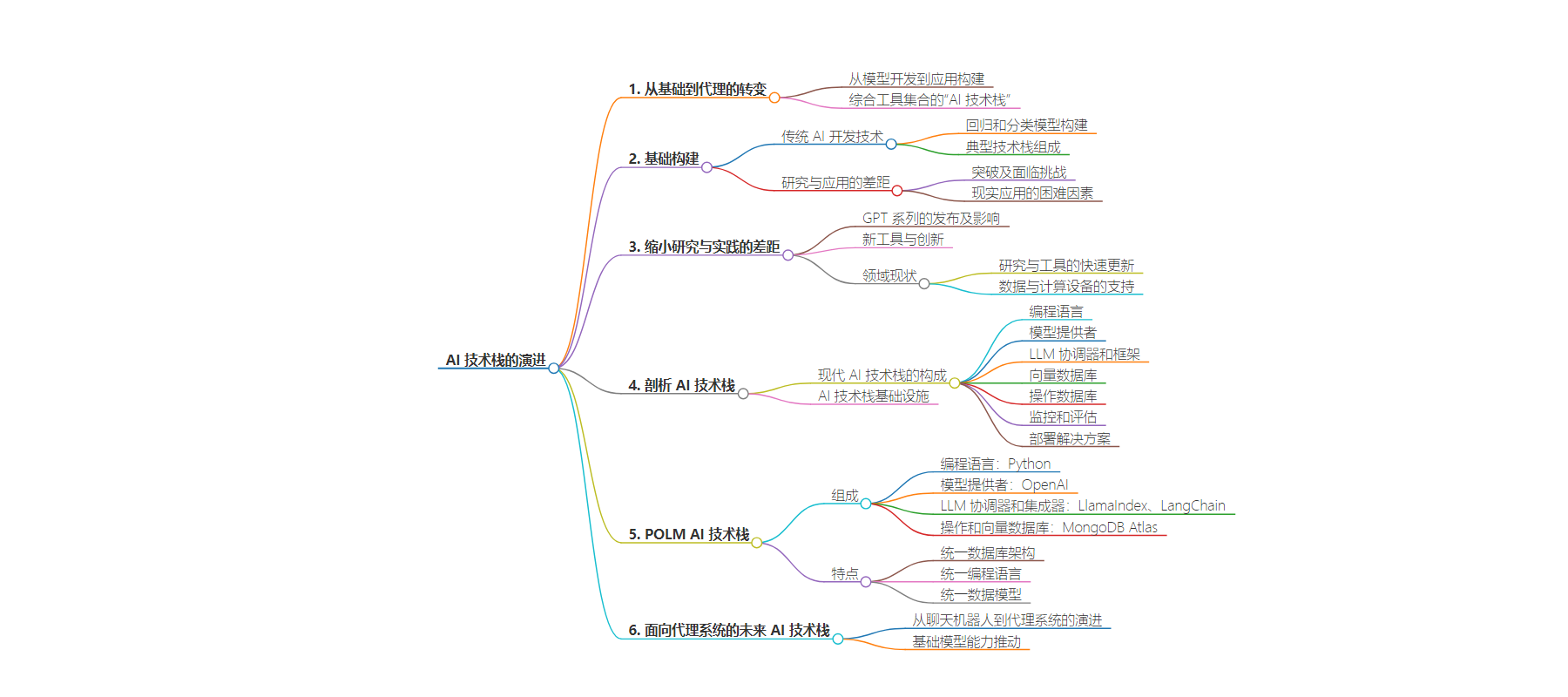
文章地址:https://thenewstack.io/the-evolution-of-the-ai-stack-from-foundations-to-agents/
文章来源:thenewstack.io
作者:Richmond Alake
发布时间:2024/7/26 14:27
语言:英文
总字数:1584字
预计阅读时间:7分钟
评分:87分
标签:AI 工具栈,生成式 AI,POLM 工具栈,LangChain,LlamaIndex
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
A new paradigm in AI tooling has emerged as AI’s focus shifts from ground-up model development to enabling software engineers and developers to build AI applications quickly and at scale. This is embodied in the “AI stack,” a comprehensive collection of integrated tools, solutions and components designed to streamline the development and management of AI applications.
This has happened very quickly, along with AI’s recent evolution. As the AI stack is largely built upon existing technologies, it’s worth looking at how it emerged before breaking down its components and outlook.
Building the Foundation
At the risk of sounding reductive, traditional AI development involves building regression and classification models using techniques like random forests, decision trees and neural networks. The typical stack includes data manipulation tools like Pandas, machine learning libraries like Scikit-Learn, and deep learning frameworks like TensorFlow (Keras), PyTorch and Caffe. There are also experimentation tracking tools such as TensorBoard, MLflow and Neptune.ai. Finally, deployment tools promote the trained models into production, and consumer access to these models is granted via an inference API endpoint.
Arguably, there hasn’t been an established go-to stack. Sure, research and development teams had preferred tools to complete specific tasks, but there hasn’t been a default stack. Researchers and practitioners commonly fell into one of two buckets, either TensorFlow or PyTorch.
Until recently, there was a wide gap between research outcomes and industry applications.
This began to change with AlexNet’s breakthrough in the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC), which led to increased optimism in the field of computer vision. While significant progress was made in image classification, researchers recognized that complex tasks like object detection still faced considerable challenges. Moreover, the path from research breakthroughs to widespread real-world applications proved more difficult than initially anticipated.
In other words, introducing a research breakthrough didn’t translate to rapid adoption due to the complexities of translating cutting-edge research into practical, scalable and efficient applications suitable for consumer devices. Factors like computational requirements, lack of standardized tools and frameworks and the need for significant adaptation and optimization for different hardware platforms all contributed to this delay.
The transformer architecture, introduced in 2017 in the paper “Attention Is All You Need,” was pivotal. It enabled development of large-scale, general-purpose language models that could process vast amounts of data across diverse domains. It overcame the limitations of previous recurrent neural network and long short-term memory architectures.
Closing the Gap Between Research and Practice
The first generation of GPT (generative pretrained transformer) was released in 2018, GPT-2 in 2019 and GPT-3 in 2020. In between the GPT releases, other foundation models — along with their code — were introduced through research papers. These models found their way into creative web apps in a span of months or even weeks.
As the gap between research and industry closed, new tools enabled researchers to build and experiment with novel neural networks. And in turn, innovations in the application and system infrastructure allowed engineers and developers to harness these powerful new models in real-life applications.
The shift in the AI domain is now focused on finding ways to empower developers to build AI applications quickly and at scale. This is an important consideration because today’s AI stack is not focused on the significant but relatively solved task of developing and deploying AI models, but on implementing, optimizing, evaluating and monitoring AI applications and systems.
Nowadays, new research in foundation model development is published frequently, and tooling for large language model (LLM) applications emerges monthly. More importantly, modern AI applications can take advantage of research findings almost immediately. What’s more, data is abundant and computing devices are increasingly powerful, enabling the full application of scaling laws in the generative AI (GenAI) domain.
The landscape of LLM provisioning has evolved towards a bifurcated ecosystem. Open source initiatives increasingly focus on releasing model weights and hyperparameters, facilitating fine-tuning rather than architectural modifications. Proprietary models abstract implementation details behind REST APIs. This paradigm shift optimizes for domain-specific adaptability in open models and seamless integration in closed systems, reflecting a nuanced approach to balancing model accessibility with deployment efficiency.
Breaking Down the AI Stack
As noted, the modern AI stack is an integrated collection of tools, solutions and components that enables engineers and developers to build AI apps with generative capabilities like audio, image and text generation at scale. It comprises programming languages, model providers, LLM frameworks, vector databases, operational databases, monitoring and evaluation tools, and deployment solutions.
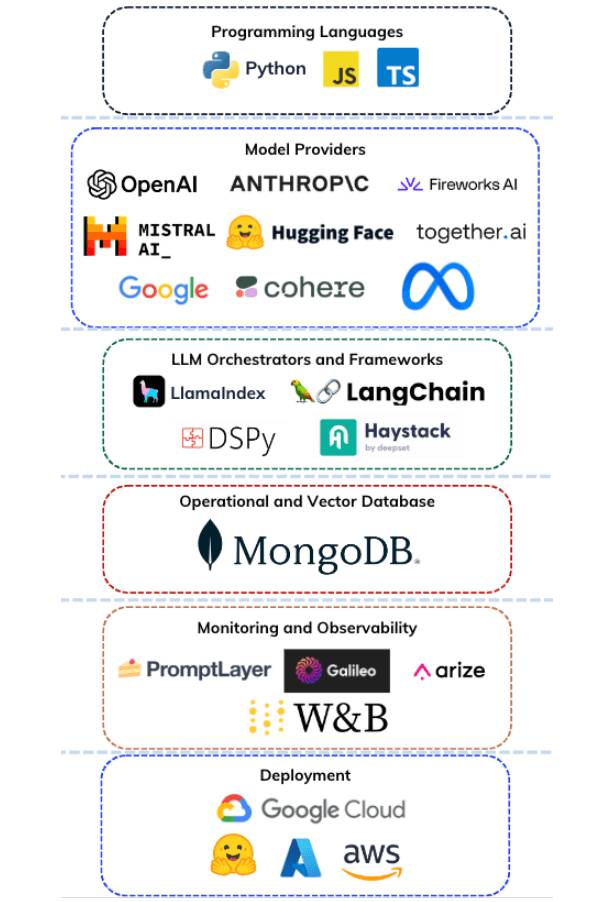
The AI stack infrastructure uses parametric knowledge from the foundation models and non-parametric knowledge from information sources like PDFs, databases and search engines to conduct GenAI functionalities.
Key components of the AI stack include:
- Programming language: The language used to develop the components of the stack, including the integration code and the source code of the AI application.
- Model provider: The organizations that provide access to foundation models either via inference endpoints or other means. Embedding and foundation models are typical models used in GenAI applications.
- LLM orchestrator and framework: The library that abstracts the complexities of integrating components of modern AI applications by providing implementation methods and integration packages. Operators within these components also provide tooling to create, modify and manipulate prompts and condition LLMs for different purposes.
- Vector database: A data storage solution for vector embeddings. Operators within this component provide features that help manage, store and efficiently search through vector embeddings.
- Operational database: A data storage solution for transactional and operational data.
- Monitoring and evaluation: Tools for tracking AI model performance and reliability, offering analytics and alerts to improve AI applications.
- Deployment solution: Services that enable easy AI model deployment, managing scaling and integration with existing infrastructure.
The modern AI stack represents an evolution from the fragmented tooling landscape of traditional machine learning to a more cohesive and specialized ecosystem optimized for the era of LLMs and GenAI. This stack is engineered to tackle modern AI applications’ unique and intriguing challenges like handling massive language models, managing vector embeddings and orchestrating complex AI workflows in retrieval-augmented generation (RAG) pipelines or agentic systems, which leverage LLMs and their function-calling capabilities to perform tasks autonomously.
Introducing the POLM AI Stack
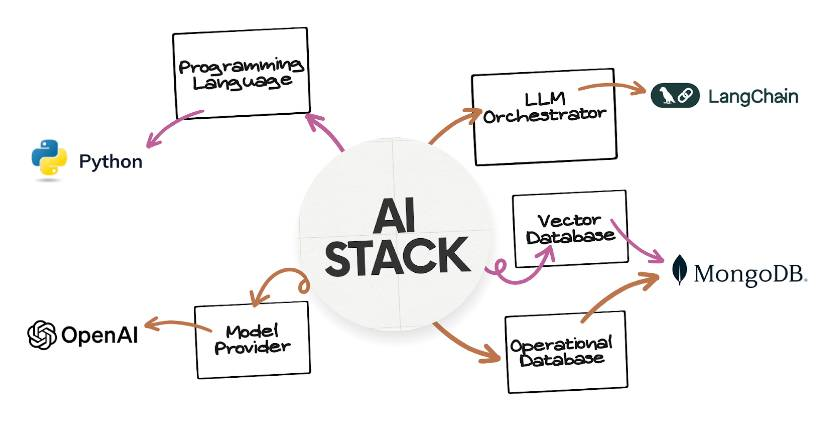
The POLM (Python, OpenAI, LlamaIndex/LangChain and MongoDB) AI stack is a collection of tools, solutions and frameworks implemented with the Python programming language. It is composed to enable the efficient development of modern AI applications, handle the unstructured nature of AI-related data and meet the real-time demands of modern applications. Its components include:
- Programming language: Python
- Model provider: OpenAI (e.g., GPT-3.5, GPT-4)
- LLM orchestrator and integrators: LlamaIndex, LangChain
- Operational and vector database: MongoDB Atlas
The POLM AI stack provides a framework for developing GenAI applications, facilitating the transition from proof-of-concept to production-ready systems. Its architecture, designed for RAG applications and agent-based systems, uses unified data models and language consistency to enhance development efficiency.
A key component of the POLM stack is its document-based data model, which aligns with the often unstructured nature of AI-generated data. This model allows efficient storage and retrieval of complex, nested data structures common in AI applications, such as conversation histories, embedding vectors and agent tool definitions.
The POLM stack offers several features that can enhance the development process of GenAI applications:
- Unified database architecture: A single database solution for operational data and vector embeddings can simplify AI infrastructure by reducing the need for multiple storage solutions.
- Unified programming language: The POLM stack prioritizes Python implementation, which prevents code switching between tools and libraries, potentially reducing fragmentation in development workflows.
- Unified data model: The document model provides consistent data representation across different AI components, from data ingestion to tool definitions for LLMs’ function-calling capabilities. This approach simplifies data management and enhances query performance by allowing optimized indexing strategies that support various query types within a single database instance.
This tutorial provides step-by-step instructions using LangChain as the LLM orchestrator and framework. It demonstrates how to implement a RAG system with memory and semantic cache, which are mature components of RAG systems. Meanwhile, this second tutorial presents the POLM stack using LlamaIndex as the LLM framework.
The Incoming AI Stack for Agentic Systems
The AI landscape is evolving from RAG-enabled chatbots to agentic systems with human-in-the-loop interfaces. This progression is driven by the growing capabilities of foundation models, including tool use and improved reasoning.
LLM abstraction frameworks like LangChain and LlamaIndex are expanding to support agent-based architectures. Meanwhile, specialized libraries like CreAI and AutoGen are emerging to facilitate multiagent system development. This stack also incorporates new components, like Tavily for real-time search, which enhance AI agents’ ability to gather data and make decisions.
While specialized libraries for agentic system development have emerged, the core components of the AI stack remain largely unchanged for these systems. However, the database infrastructure for agentic systems requires more versatility, handling conversational history, operational data and vector embeddings, as well as features like semantic caching and data streaming.
As AI applications continue to mature, agentic systems will necessitate further advancements in AI tools, particularly in databases that can perform a wide array of functions to support these complex, dynamic systems. Here is where we can expect the next wave of innovation.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.