
包阅导读总结
1.
– `LLM`、`Vertex GenAI Evaluation`、`输出质量`、`可解释性`、`多样响应`
2.
本文介绍了利用 Vertex GenAI Evaluation 解决 LLM 输出随机和不准确的问题,通过生成多样响应、选出最佳响应并评估其质量,提升 LLM 表现,适用于多行业和模态。
3.
– 开发者使用 LLM 面临输出随机和不准确两大难题
– 随机输出有时影响一致性和准确性
– 偶尔的“幻觉”提供错误信息
– 新工作流解决挑战
– 生成多样的 LLM 响应
– 调整参数以增加多样性
– 找出最佳响应
– 运用成对评估方法比较
– 评估最佳响应是否足够好
– 分配质量分数和生成解释
– 工作流优势及应用
– 全面评估 LLM 响应,提供最优解释
– 适用于多行业和模态,可调整评估顺序和并行化 API 调用
思维导图: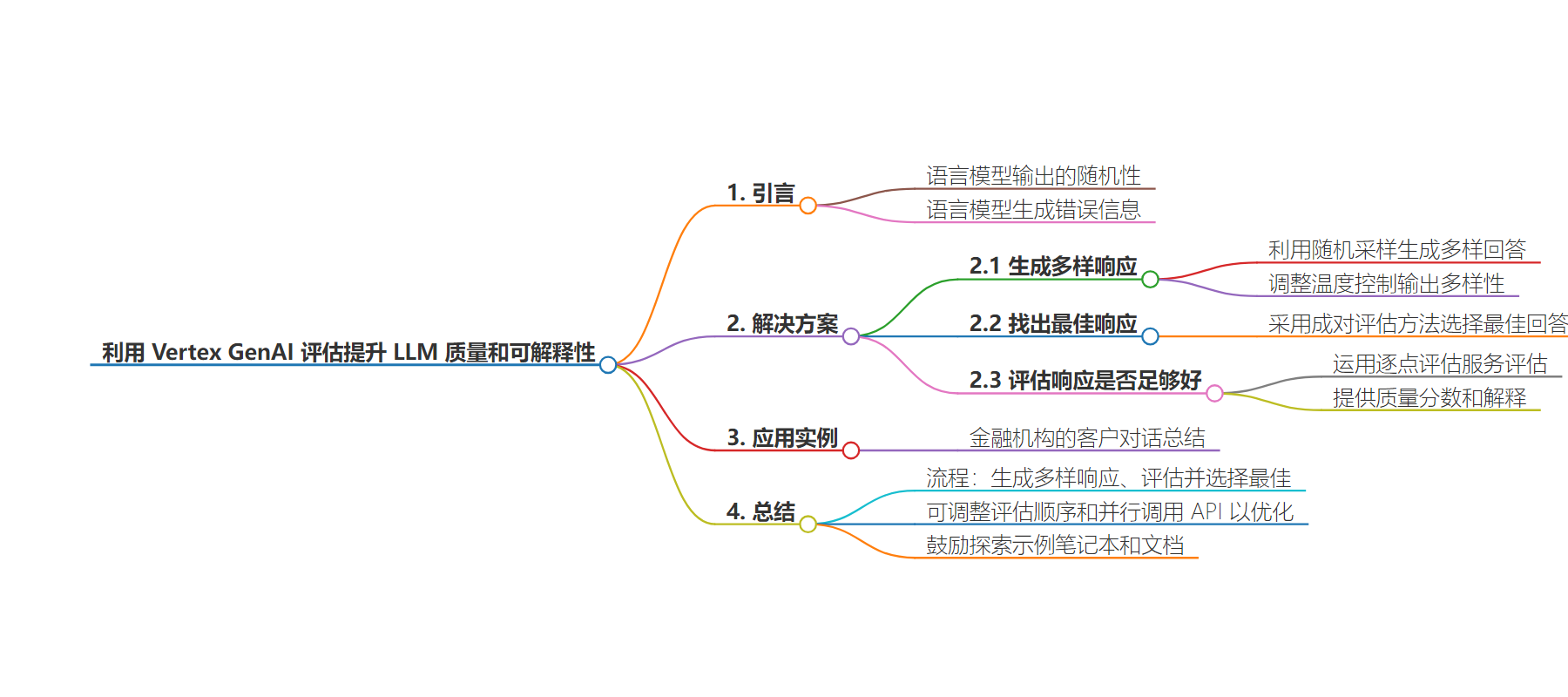
文章来源:cloud.google.com
作者:Anant Nawalgaria,Irina Sigler
发布时间:2024/7/30 0:00
语言:英文
总字数:1009字
预计阅读时间:5分钟
评分:86分
标签:大型语言模型 (LLM),AI 评估,AI 优化,Google 云平台,质量保证
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Developers harnessing the power of large language models (LLMs) often encounter two key hurdles: managing the inherent randomness of their output and addressing their occasional tendency to generate factually incorrect information. Somewhat like rolling dice, LLMs offer a touch of unpredictability, generating different responses even when given the same prompt. While this randomness can fuel creativity, it can also be a stumbling block when consistency or factual accuracy is crucial. Moreover, the occasional “hallucinations” – where the LLM confidently presents misinformation – can undermine trust in its capabilities. The challenge intensifies when we consider that many real-world tasks lack a single, definitive answer. Whether it’s summarizing complex information, crafting compelling marketing copy, brainstorming innovative product ideas, or drafting persuasive emails, there’s often room for multiple valid solutions.
In this blog post and accompanying notebook, we’ll explore how to tackle these challenges by introducing a new workflow which works by generating a diverse set of LLM-generated responses and employing the Vertex Gen AI Evaluation Service to automate the selection process of the best response and provide associated quality metrics and explanation. This process is also extensible to multimodal input and output and stands to benefit almost all use cases across industries and LLMs.
Picture this: a financial institution striving to summarize customer conversations with banking advisors. The hurdle? Ensuring these summaries are grounded in reality, helpful, concise, and well-written. With numerous ways to craft a summary, the quality varied greatly. Here is how they leveraged the probabilistic nature of LLMs and the Vertex Gen AI Evaluation Service to elevate the performance of the LLM-generated summaries.
Step 1: Generate Diverse Responses
The core idea here was to think beyond the first response. Causal decoder-based LLMs have a touch of randomness built in, meaning they sample each word probabilistically. So, by generating multiple, slightly different responses, we boost the odds of finding a perfect fit. It’s like exploring multiple paths, knowing that even if one leads to a dead end, another might reveal a hidden gem.
For example, imagine asking an LLM, “What is the capital of Japan?” You might get a mix of responses like “Kyoto was the capital city of Japan,” “Tokyo is the current capital of Japan,” or even “Tokyo was the capital of Japan.” By generating multiple options, we increase our chances of getting the most accurate and relevant answer.
To put this into action, the financial institution used an LLM to generate five different summaries for each transcript. They adjusted the LLM’s “temperature,” which controls the randomness of output, to a range of 0.2 to 0.4, to encourage just the right amount of diversity without straying too far from the topic. This ensured a range of options, increasing the likelihood of finding an ideal, high-quality summary.
Step 2: Find the Best Response
Next came the need to search through the set of diverse responses and pinpoint the best one. To do this automatically, the financial institution applied the pairwise evaluation approach available in the Vertex Gen AI Evaluation Service. Think of it as a head-to-head showdown between responses. We pit response pairs against each other, judging them based on the original instructions and context to identify the response that aligns most closely with the user’s intent.
Continuing the example above to illustrate, let’s say we have those three responses about Japan’s capital. We want to find the best one using pairwise comparisons:
- Response 1 vs Response 2: The API favors Response 2, potentially explaining, “While Response 1 is technically correct, it doesn’t directly answer the question about the current capital of Japan.”
- Response 2 (best response so far) vs Response 3: Response 2 wins again! Response 3 stumbles by using the past tense.
- After these two rounds of comparison, we conclude that Response 2 is the best answer.
In the financial institution’s case, they compared their five generated summaries in pairs to select the best one.
Step 3: Assess if the Response is Good Enough
The workflow then takes the top-performing response (Response 2) from the previous step and uses the pointwise evaluation service to assess it. This evaluation assigns quality scores and generates human-readable explanations for those scores across various dimensions, such as accuracy, groundedness, and helpfulness. This process not only highlights the best response but also provides insights into why the model generated this response, and also why it’s considered superior to the other responses, fostering trust and transparency in the system’s decision-making. In the case of the financial institution, they now used the summarization-related metrics in pointwise evaluation on the winning response to obtaining an explanation of how this answer is grounded, helpful, and high-quality. We can choose to return just the best response or include its associated quality metrics and explanation for greater transparency.
In essence, the workflow (as illustrated in this blog’s banner) encompasses generating a variety of LLM responses, systematically evaluating them, and selecting the most suitable one—all while providing insights into why that particular response is deemed optimal. Get started by exploring our sample notebook and adapting it to fit with your use case. You can reverse the order of pairwise and pointwise evaluations, by ranking individual responses based on their pointwise scores and then conducting pairwise comparisons only on the top candidates. Further, while this example focuses on text, this approach can be applied to any modality or any use case including but not limited to question answering and summarization like illustrated in this blog. Finally, if you need to minimize latency, both workflows can benefit greatly from parallelizing the various API calls.
Take the next step
By embracing the inherent variability of LLMs and utilizing the Vertex Gen AI Evaluation Service, we can transform challenges into opportunities. Generating diverse responses, systematically evaluating them, and selecting the best option with clear explanations empowers us to unlock the full potential of LLMs. This approach not only enhances the quality and reliability of LLM outputs but also fosters trust and transparency. Start exploring this approach in our sample notebook and check out the documentation for the Vertex Gen AI Evaluation Service.