
包阅导读总结
1.
关键词:面壁小钢炮、端侧多模态、GPT-4V、视频理解、多图联合
2.
总结:面壁小钢炮 MiniCPM-V 2.6 重磅推出,仅 8B 参数,在单图、多图、视频理解方面取得 SOTA 成绩,全面对标 GPT-4V,具有多项创新功能,且运行高效,端侧表现出色。
3.
主要内容:
– 面壁小钢炮 MiniCPM-V 2.6 重磅出击
– 取得单图、多图、视频理解三项 SOTA ,性能对标 GPT-4V
– 多项功能首次上“端”
– 实时视频理解
– 多图联合理解
– 多图 ICL 视觉类比学习
– 多图 OCR
– 特点与优势
– 极致高效,最高多模态像素密度
– 端侧友好,内存占用少,推理速度快
– 统一高清框架,高效能力一拖三
– 幻觉水平低
– 成为端侧多模态标杆,下载量破百万,是面壁“大模型科学化”路线的结晶
思维导图: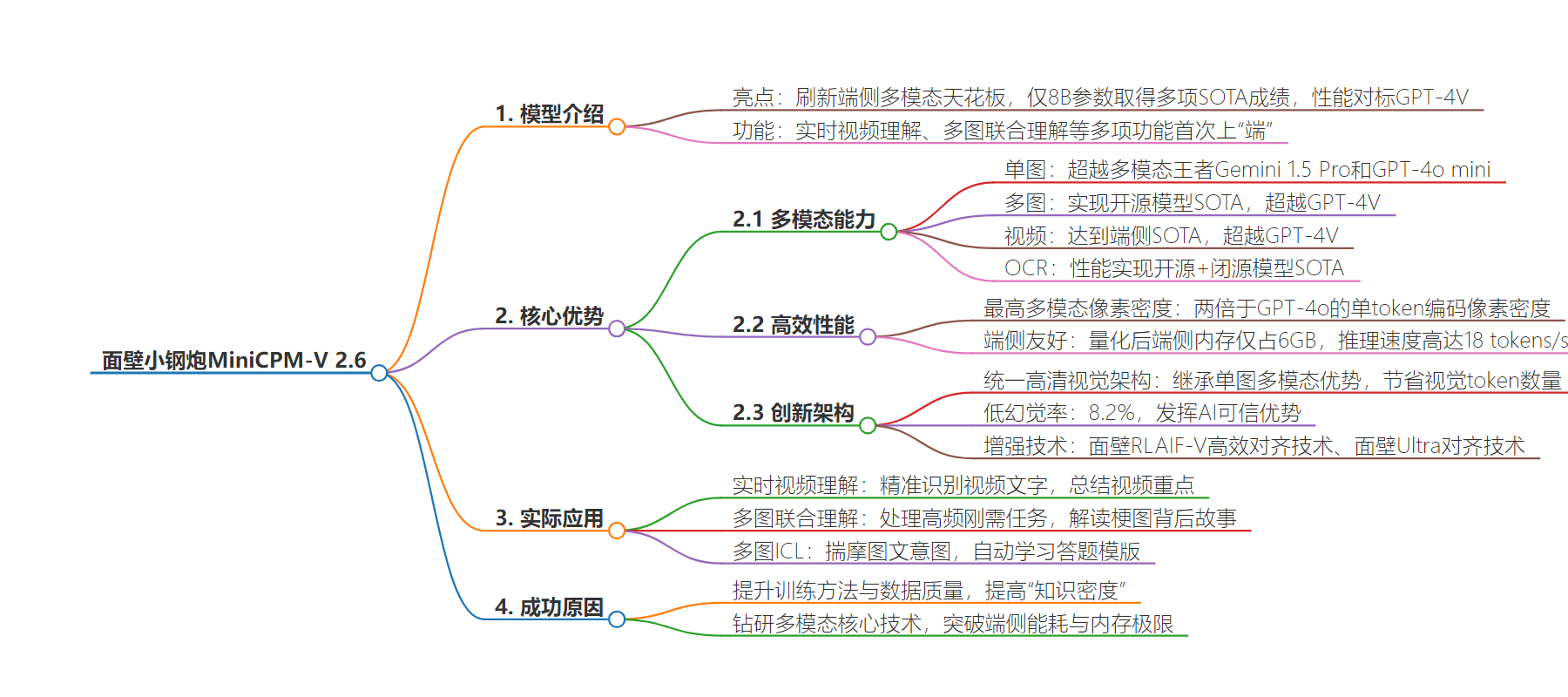
文章地址:https://mp.weixin.qq.com/s/xt7goy0ISAUhVuLSUdg7jA
文章来源:mp.weixin.qq.com
作者:新智元
发布时间:2024/8/6 10:38
语言:中文
总字数:4233字
预计阅读时间:17分钟
评分:93分
标签:多模态AI,端侧模型,GPT-4V,MiniCPM-V 2.6,开源
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
【新智元导读】面壁小钢炮MiniCPM-V 2.6重磅出击,再次刷新端侧多模态天花板!凭借8B参数,已经取得单图、多图、视频理解三项SOTA ,性能全面对标GPT-4V。
-
「三合一」最强端侧多模态:首次在端侧实现单图、多图、视频理解等多模态核心能力全面超越 GPT-4V,单图理解越级比肩多模态王者 Gemini 1.5 Pro 和新晋顶流 GPT-4o mini 。
-
多项功能首次上端:实时视频理解、多图联合理解、多图 ICL 视觉类比学习、多图 OCR 等功能,第一次让端侧模型睁开观察、理解真实流动世界的「眼睛」,不仅看得清晰,还能有样学样、模仿学习。
-
极致高效,最高多模态像素密度:类比知识密度,小钢炮2.6取得了两倍于GPT-4o的单 token 编码像素密度(token density),在端侧方寸之地,一路将大模型「能效比」挖到极限。这一进展,得益于视觉 token 相比上一代下降 30% ,比同类模型低 75%。
-
端侧友好:量化后端侧内存仅占 6 GB;端侧推理速度高达 18 tokens/s,相比上代模型快 33%。并且发布即支持 llama.cpp、ollama、vllm 推理;且支持多种语言。
-
统一高清框架,高效能力一拖三:小钢炮的传统优势 OCR 能力延续了其 SOTA 性能水平,并进一步覆盖单图、多图、视频理解。
HuggingFace:https://huggingface.co/openbmb/MiniCPM-V-2_6
-
llama.cpp、ollama、vllm 部署教程地址:
https://modelbest.feishu.cn/docx/Duptdntfro2Clfx2DzuczHxAnhc
单图、多图、视频理解 3 SOTA!
GPT-4V级、三合一最强端侧多模态
注:指20B以下、端侧模型SOTA
以小博大,是端侧模型的核心竞争力。
仅 8B 参数,新一代 MiniCPM-V 2.6 不仅再一次取得了媲美 GPT-4V 的综合性能, 还首次作为端侧 AI 模型,掀开单图、多图、视频理解三项多模态核心能力全面超越 GPT-4V 之新格局,且均实现 20B 参数以下模型性能 SOTA。
在 MiniCPM-V 2.6 的知识压缩率方面,我们发现,MiniCPM-V 2.6 体现出极致的高效,取得了两倍于 GPT-4o 的最高多模态大模型像素密度(Token Density) 。
Token Density = 编码像素数量/ 视觉 token 数量,是指单个 token 承载的像素密度即图像信息密度,直接决定了多模态模型实际的运行效率,数值越大,模型运行效率越高。
实时视频理解,首次上端!
睁开端侧「眼睛」,打开具身广阔潜力
真实世界的视觉信息是流动的!
端侧视频理解具有天然优势,手机、PC、AR、机器人、智能座驾等端侧设备自带的摄像头,具有天然的多模态输入能力。相比云端,离用户更近,链路更短,效率更高,同时具有更强的信息安全优势。
有了实时视频理解功能,大模型犹如拥有一双「眼睛」,能够实时看到真实世界,这是多模态大模型走向具身智能等更多实际领域,实现 AGI 的必要条件之一。此外实时视频理解功能也让人机交互也更加自然友好。
MiniCPM-V 2.6 让实时视频理解功能第一次运行在端侧。

多图联合理解,首次上端!
流畅、聪明,一直识图一直爽
钻研多模态模型能力的不竭动力,源自于它更接近真实世界的形态,充斥着画面、视频、语言等多种模态、同时并发的信息。
难以想象,当我们睁开眼睛看世界,只能一个画面、一个画面,顺次机械而卡顿地识别理解;也不会事事都能得到精准的文字指示,像小孩子模仿大人行为举止般「有样学样」地揣摩学习与动作跟随,是绝大多数我们学习与尝试新事物时所发生的样子。
将端侧AI的多模态能力进行极致探寻,最新发布的 MiniCPM-V 2.6 首次将多图联合理解、多图ICL(上下文少样本学习 )功能集成在端侧模型,这也是此前业界多模态王者 GPT-4V 引以为傲的能力。
1. 流畅的多图多轮理解,爽!
就像人们习惯把多个文件拖拽给大模型处理,在日常生活和工作中,联合处理多张图像是高频刚需。
比如常令人头疼的记账或报销难题,小票上密密麻麻的数字难以辨别,更别提进行繁琐的总账计算。拍照下来,一口气甩给 MiniCPM-V 2.6,除了一一找出每张小票的金额,最后还把总账计算出来,十分方便。
2. 强悍的多图复杂推理能力,竟能读懂你的梗!
多图 ICL,首次上「端」!
大模型学会揣测模仿,有样学样
很多时候,很多场景,难以用语言完全说清,通过明确定义的语言 prompt 来控制模型的输出行为难以奏效。
这个时候,图文信息一起「看」来理解,就像我们婴童时期那样观察、模仿、学习,往往更加直接与准确。
这其实就是多图 ICL(In context learning)上下文少样本学习,它能激发出模型的潜力,让模型无需fine-tune,即可快速适配到特定领域和任务,显著提高模型的输出稳定性。
在下面的例子中,我们直接通过视觉 prompt 给大模型下指示:
给出两组神转折画面,以及对画面中的「梗」给出示意文字描述,例如一个戴着手套、重视卫生的厨师,下一秒却用戴手套的手直接去拿实际有些肮脏的纸币;一个看似热衷环保的人,却把塑料瓶装水打开装进环保水壶……
这时 MiniCPM-V 2.6 能够自动从前面两组图文关系,揣摩出题人的意图,并自动学会「答题模版」,给出神转折答案—— 一个人手握大量加密数字货币,可你猜怎么着,他出门购物,可是商店却只收现金!
新一代小钢炮的最大亮点:单图、多图、视频理解等核心能力对 GPT-4V 的全面对标。
从单一优势,到全面对标,大幅跃进从何而来?在 Qwen2-7B 基座模型的性能加持之外,要归功于采用了统一高清视觉架构。
统一高清视觉架构,让传统单图的多模态优势功能得以继承,并实现了一通百通。
例如,多管齐下的 OCR SOTA 能力:
它将 MiniCPM-V 单图场景的「180万高清图像解析」进行能力迁移和知识共享,无缝拓展至多图场景和视频场景,并将这三种视觉理解场景统一形式化为图文交替的语义建模问题,共享底层视觉表示机制,实现相比同类型模型,视觉 token 数量节省超过 75% 。
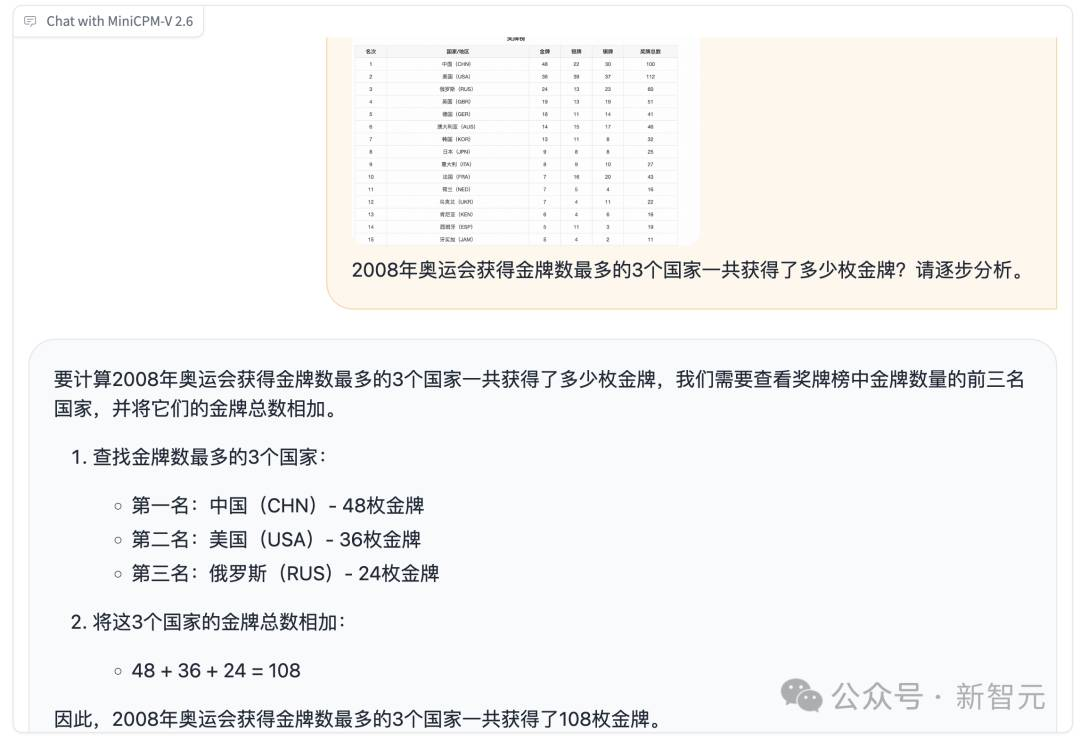
OCR 信息提取的基础上,MiniCPM-V 2.6 还能进一步对表格信息进行类似 CoT(思维链)的复杂推理。
比如让模型计算 2008 年奥运会获得金牌数最多的 3 个国家一共获得了多少枚金牌,CoT 的过程是:
-
首先利用 OCR 能力识别并提取出奖牌榜中金牌数量的前三名国家;
在多模态复杂推理能力对齐方面,MiniCPM-V 2.6 通过复杂题目的 CoT 解答数据,构造高效对齐种子数据,并通过模型自迭代完成数据净化和知识学习。
在多图联合理解方面,MiniCPM-V 2.6 从通用域自然网页中结合文本线索挖掘多图关联语义,实现多图联合理解数据的高效构造。

在端侧最强多模态的道路上,小钢炮 MiniCPM-V 系列已成为标杆性的存在。
自24年2月1日首次开创端侧部署多模态先河,短短半年,即接连完成了端侧模型从单一、到全面对标 GPT-4V 的重大突破,小钢炮系列下载量已破百万!
为何面壁「小钢炮」系列,频出以小博大的多模态端侧佳作?
可以说,MiniCPM 端侧模型系列,正是面壁长期以来「大模型科学化」路线的结晶。
一方面,通过科学提升训练方法与数据质量,不断提升大模型「知识密度」,得到同等参数,性能更强、成本更低的高效模型。两倍于 GPT-4o 的巅峰级单 token 图像信息密度(Token Density),小钢炮 2.6 交出一份漂亮的多模态高效运行效率成绩单。

