
包阅导读总结
1. 强化学习、马尔可夫决策过程、动态规划、智能体、应用
2. 强化学习是试错方法,目标是让软件智能体在特定环境中行为回报最大化。马尔可夫决策过程中主要用动态规划技术,流行方法众多,应用于下棋、机器人控制等领域。
3.
– 强化学习
– 是一种试错方法
– 目标是让软件智能体在特定环境中采取回报最大化的行为
– 技术
– 在马尔可夫决策过程环境中主要使用动态规划
– 流行方法包括自适应动态规划、时间差分学习、SARSA 算法、Q 学习、深度强化学习
– 应用
– 下棋类游戏
– 机器人控制
– 工作调度等
思维导图: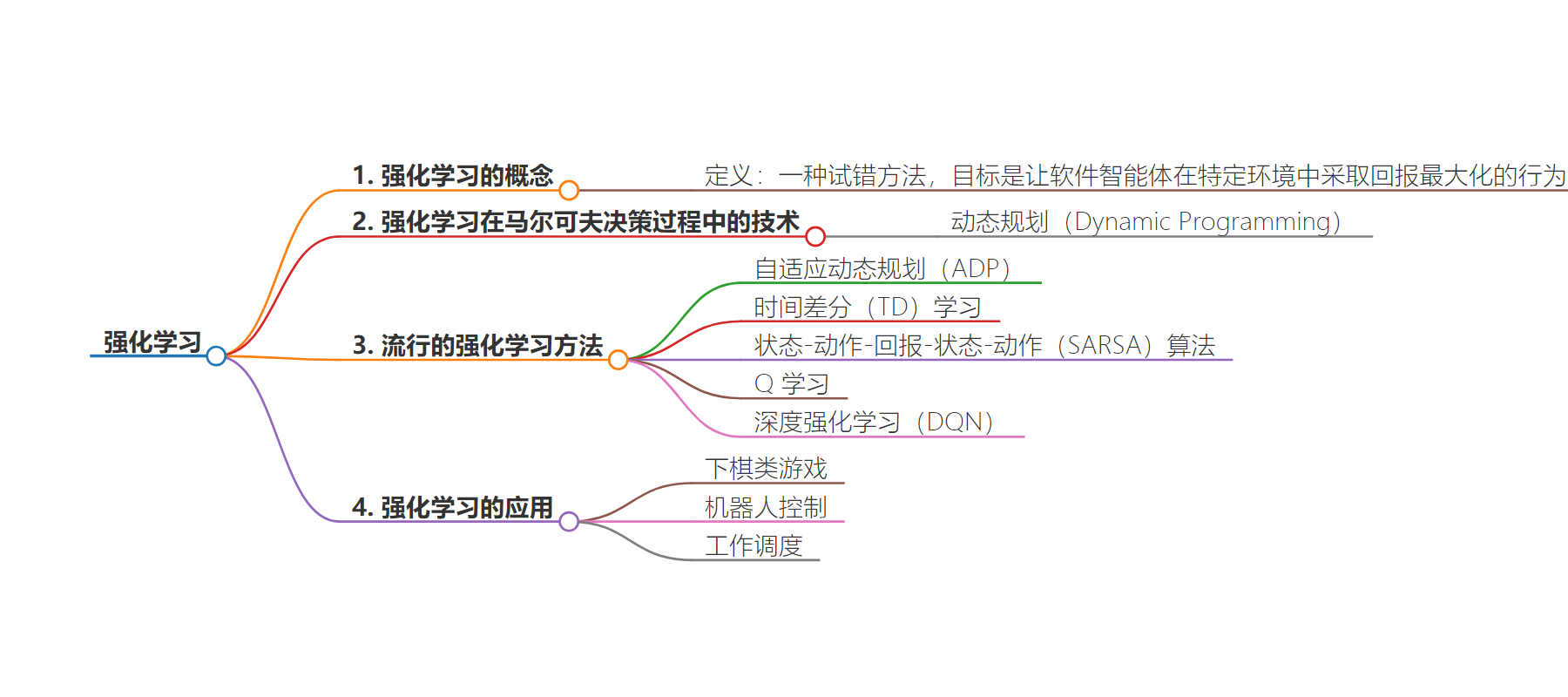
文章地址:https://www.jiqizhixin.com/articles/2024-07-15-5
文章来源:jiqizhixin.com
作者:机器之心
发布时间:2024/7/15 3:34
语言:中文
总字数:12404字
预计阅读时间:50分钟
评分:93分
标签:大型语言模型,幻觉,事实性评估,微调技术,强化学习
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
强化学习是一种试错方法,其目标是让软件智能体在特定环境中能够采取回报最大化的行为。强化学习在马尔可夫决策过程环境中主要使用的技术是动态规划(Dynamic Programming)。流行的强化学习方法包括自适应动态规划(ADP)、时间差分(TD)学习、状态-动作-回报-状态-动作(SARSA)算法、Q 学习、深度强化学习(DQN);其应用包括下棋类游戏、机器人控制和工作调度等。