
包阅导读总结
1. 快手、Gundam 脚手架、前端工程化、统一与隔离、稳定性
2. 本文主要探讨了快手主站前端工程化中 Gundam 脚手架在新春除夕项目中的实践,包括统一与隔离的选择权衡、能力封装方式、解决黑盒问题的方案以及未来发展方向,强调在保障效率的同时要兼顾稳定性和问题排查的便利性。
3.
– 统一与隔离的选择
– 隔离能减少信息差和稳定性风险,但成本高、效率低。
– 统一能提高资源利用率和效率,但可能存在稳定性风险。
– 应根据实际情况权衡,在该统一的地方统一,该隔离的地方隔离。
– Gundam 在新春除夕项目中的实践
– 对框架/构建工具、网络库等进行统一,提升工程复用和效率。
– 为活动场景单独部署私有化集群进行隔离,提升稳定性。
– Gundam 的能力封装
– 采用构建时动态注入,不侵入业务逻辑代码,方便迭代和排查问题。
– 从方案和工程层面解决能力封装的黑盒问题。
– 未来发展方向
暂未明确,留待后续讨论。
思维导图: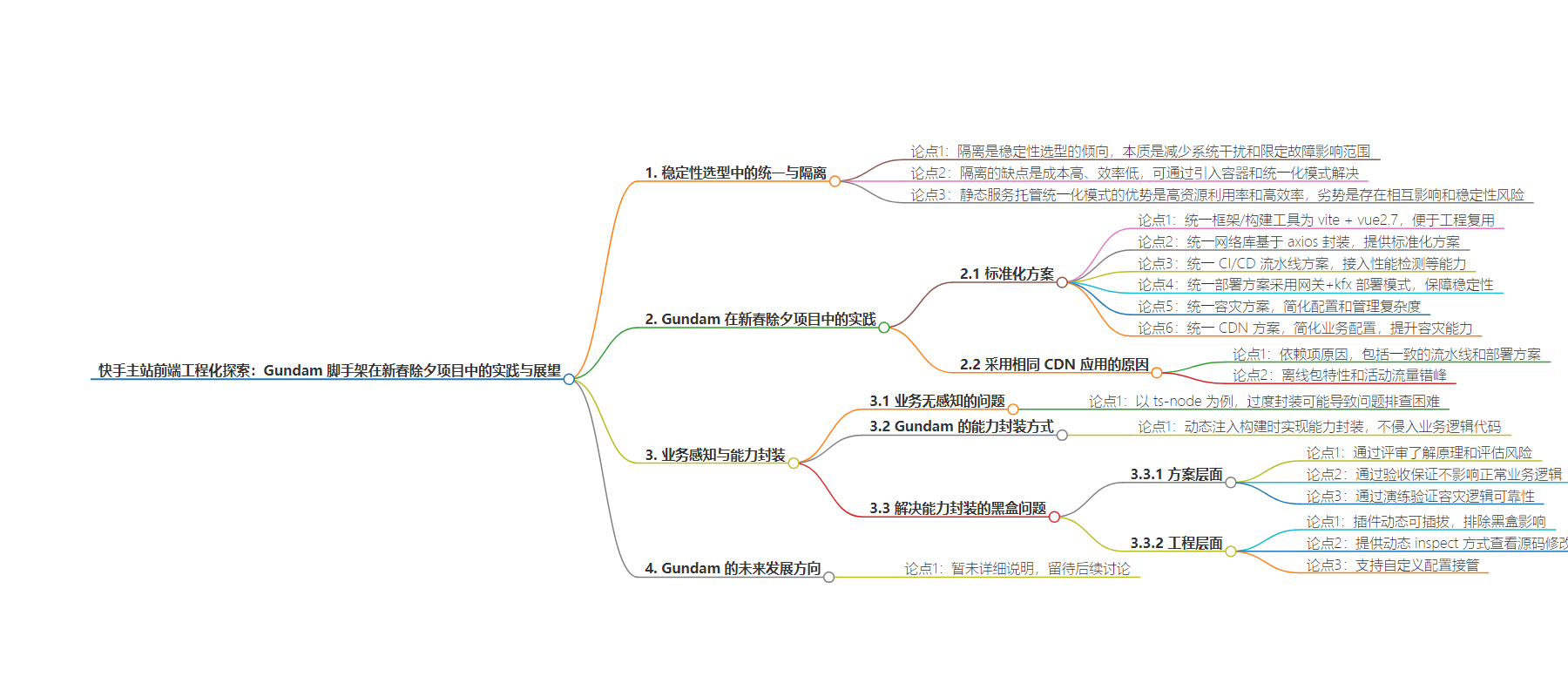
文章地址:https://mp.weixin.qq.com/s/ngBQOC-WQ8mWHkMYzbnzBQ
文章来源:mp.weixin.qq.com
作者:钟艺
发布时间:2024/7/25 7:16
语言:中文
总字数:8247字
预计阅读时间:33分钟
评分:91分
标签:前端工程化,Gundam脚手架,工程化漏斗,标准化,透明化
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
统一与隔离,从稳定性角度来选择,哪一个方向应该是做稳定性选型时更倾向的?
有经验的朋友一下就能回答上,当然是隔离。在高可用的架构设计中,服务隔离是一个重要的保障措施。
隔离的本质在于让不同系统间不会相互发生干扰,减少资源竞争,在系统发生故障时,也能限定故障的影响范围,避免雪崩。
众所周知,信息差跟范围是正相关的,涉及范围越大,可能存在的信息盲区就越多,跨组织之间甚至存在了信息壁垒, 信息盲区会导致方案不全面,会引入更多的稳定性风险。因此合理的隔离是能减少信息差,将变更的控制范围尽量缩小,从而减小稳定性风险的一种有效手段。
那么,能不能遇事不决就隔离?
所有事情都按隔离原则来就好了吗,当然是不行的,隔离有什么样的缺点呢?
最典型的问题就在于:更高的成本,更低的效率。
拿前端静态部署来说,隔离的极端情况是,一个物理机上部署一个前端应用。这种情况下,10个应用就需要10台机器,这个对成本是极大的占用,利用率也很低, 要怎么解决这个问题呢:引入容器的概念,在一台物理机上通过对进程和资源的隔离做了容器化,然后一台机器上就能部署多个应用了。这也是当前用容器云直接部署前端应用的情况,他带来了什么问题呢,虽然已经比上面的物理机情况好不少了, 在大部分场景下,一个前端应用几乎消耗不了 1c2g的硬件资源,资源利用率仍然很低。同时,容器的发布效率也不够快,是分钟级的,前端的静态部署本质上是在做文件替换,根本不需要像服务端应用那样做服务重启,这也就是隔离带来的低效和高成本。
进一步的统一能够有效减少这一问题,也就是当前前端KFX静态部署的托管模式。KFX将多个静态服务托管在了一个容器上,由内部的服务来接管应用变更这一逻辑,容器长期存在不会随应用发布而重启。 这样的好处是,能让发布的时间达到秒级,同时资源的利用率也上去了。
整个演进过程如下所示:
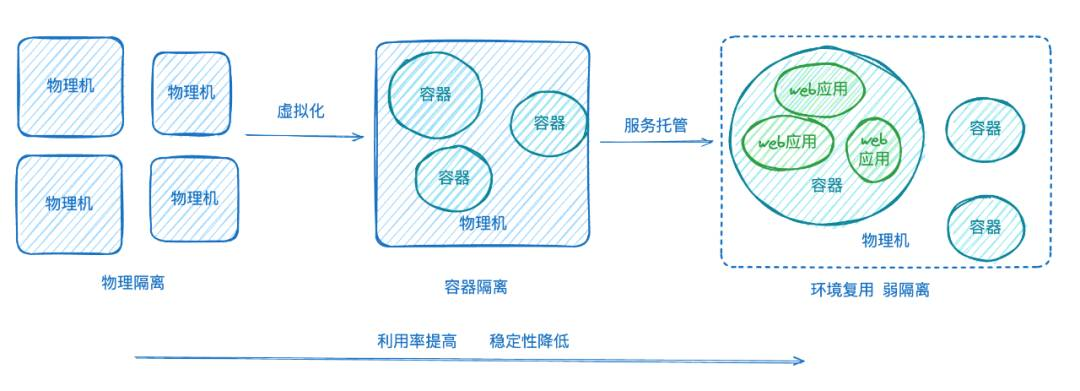
可以看到,静态服务托管这种统一化的模式,优势是高资源利用率,高效率,劣势是不隔离,服务间是有可能存在相互影响的,可能存在更多的稳定性风险。
在方案设计中,我们会认为静态部署本身产生的耦合和影响是可接受的,并不会出现server服务混布高频出现的硬件资源、网络的竞争,因此用这一稳定性来换取效率是合适的。同时,在新春除夕项目场景下,为了进一步提升稳定性,我们为新春除夕项目活动场景单独部署的私有化集群,从而跟其他非活动应用隔离开来,提升该场景下的稳定性。
什么时候应该统一
统一和隔离,虽然是两个对立的概念,但是在实际的应用过程中,是可以相互应用的,简单的来讲就是:在该统一的地方统一,该隔离的地方隔离。那么Gundam在新春除夕项目里是怎么做的呢,对于预热、除夕、留存三大会场,都采用了以下的标准化:
|
标准化方案 |
描述 |
收益 |
|
统一框架/构建工具 |
vite + vue2.7 方案 |
无需兼容不同构建工具生态,构建工具可以说是工程标准化的基石。 会场横向间工程化能力、物料可快速复用 |
|
统一网络库 |
基于axios封装 |
基于网络库,封装提供了预请求、fmp、az调度、sig3 等标准化方案,可以在会场横向间统一使用。 |
|
统一CI /CD 流水线方案 |
CI 采用 kdev CI CD采用星环流水线: |
活动期间在流水线中统一接入了性能自动化检测、敏感词检测等能力,统一了CDN、静态部署的生产链路 |
|
统一部署方案 |
采用网关+kfx 部署的模式 |
统一使用单独KFX集群,活动更高级别的稳定性保障。 统一容灾方案的基础。 |
|
统一 CDN 方案 |
统一的静态部署集群,统一的容灾方案 |
下面展开说 |
用CDN方案展开来讲,在新春除夕项目中具体带来了那些优势呢:
-
在生产侧业务无需关心CDN应用和流水线上传配置,Gundam 提供了标准统一的CD流水线。
-
在消费侧无需关心工程中 CDN 打包配置,只需要引入 Gundam CDN插件
-
容灾能力无需业务关心,统一CDN应用大大简化各会场容灾方案的配置和管理复杂度,能将容灾场景能力做完全插件化,在容灾演练时也不需要每个会场能力单独验证。
-
CDN侧无需分配多个会场的预估资源。
那么,为什么这次所有会场前端可以采用相同的CDN应用:
|
依赖项 |
原因 |
可行性 |
|
统一的流水线方案 |
需要通过流水线保证各会场在前端CDN静态资源的生产链路一致,消费链路一致 |
这是Gundam在初始化时保证的 |
|
一致的部署方案 |
一致的部署方案决定了容灾方案可保持一致,演练方案一致 |
这是Gundam在初始化时保证的 |
|
离线包 |
离线包覆盖,且单个静态资源体积不大,不需要做资源预热 服务端下发的资源往往强依赖预热,所以需要分应用管理 |
这是前端在大型活动的特性 |
|
预热/除夕/留存流量错峰 |
项目资源复用,同一个项目但是峰值不会同时出现 |
这是活动本身属性 |
什么时候应该隔离
总结
统一与隔离,看似对立的概念其实在实际应用中并不是对立的,我们需要根据实际情况做权衡。新春除夕项目活动中,我们根据活动特性对框架/构建工具、网络库、CI/CD流水线方案、部署方案、CDN方案进行了统一,能让工程能力、物料在各会场间快速复用,相同的CI/CD方案还保障了devops流程的稳定性, 能有效的提升活动整体研发效率,保障活动稳定性底线。整体来说 Gundam 旨在让业务同学不需要投入时间解决繁琐的工程化问题,专注于业务逻辑实现。
上面一直在强调说,对业务无感知。业务完全无感知,这真的是好事吗?
业务对这个方案无感知,那个方案无感知,一旦出了问题,业务不就两眼一黑了。
🌰:用大家熟悉的 ts-node举例(首先我认为 ts-node 是一个很不错的框架), ts-node是用来作为ts文件不能直接执行的解决方案, 被很多人认为“too much magic”。众所周知,ts文件是不能直接执行的,但是ts-node造成了这种错觉,相比node, ts-node 的“执行” 是将正常ts的编译和执行两个流程封装为了一次流程,在内存中编译并执行。
这种方式好不好呢,大部分情况下是好的:能够丝滑的不产生js文件直接执行,方便开发调试效率,但是 “如果封装得很好,业务无感知,什么问题都不会有。但是一旦出问题,就会非常让人头疼。” 我们可能遇到过,使用ts-node执行同样的模块,声明成cjs能正常执行,但是 esm 就不行,模块引入必须要改成严格.js 后缀(后续提供了experimentalSpecifierResolution 来抹平这个问题), ts-node为了给你丝滑的直接执行ts的体验,内部自行实现了对于ts文件的模块加载方式, 跟typescript原生方案不是完全一致的,所以在跟进兼容typescript方案的过程中,总会有各种各样的坑,这种时候去ts-node 的issue 看看,能发现一堆对于模块加载的问题。
一句话总结就是: ts-node 为了达到直接执行ts的效果,对模块解析和执行能力进行了黑盒封装,往往会导致出问题难以排查和解决。

Gundam 是如何做能力封装的
跟ts-node类似,Gundam作为一个脚手架框架,主打的一个目标就是业务无感知来做效率提升,很多功能我们都希望业务开箱即用,在某些特定的场景下,开箱我们就帮你做完了,都不需要你来用。比如:创建weblogger,CDN容灾能力, 注入雷达种子包, fmp自动上报的目等。
这些能力的实现方式, 并不是在初始化的时候在模板里集成这些代码片段,而是在构建时去做的动态注入。
前者像是一锤子买卖,把东西准备好了之后就甩给开发者,这部分代码在后续迭代过程中逐渐会跟业务逻辑耦合在一起。然而项目总是处于一个不断迭代和更新的过程,底层的工程化能力也一样,会在维护过程中也需要不停迭代工程化的能力,按照前者的方案,功能能力代码和业务代码耦合后,很难在业务改动一段时间后再去进行能力的升级。而后者Gundam采用的方案希望做到的是不侵入业务逻辑代码(src目录),每次都在构建时做动态生成和注入,只改变产物,不改变源码。在后续迭代过程中,也能做到不修改任何业务代码文件的情况下升级工程化能力, 在排查问题时,也能做到能力可插拔。
这一方案的整体实现思路如下:
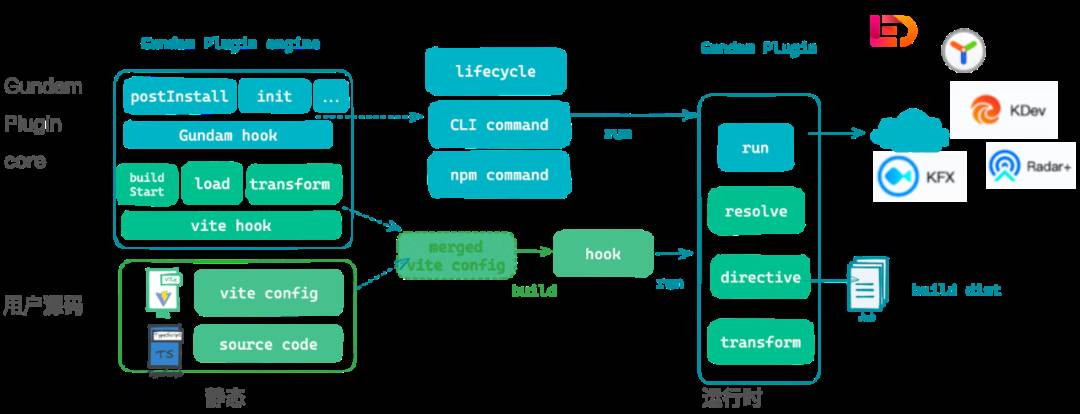
左边的上方是 Gundam 插件的基座,下方是用户的工程源码。
根据插件的两种类型, 分为基于 vite hook 的构建能力和基于 Gundam hook 的通用能力。Vite hook 依赖 vite插件系统本身提供的hook ,包括 build start、load、tranform 等,在这些 hook 中可以实现我们对源码的分析和修改,然后与用户的vite config 合并为实际运行的config。所有关于源码的操作都是在这些hook中进行的,因此可以达到不侵入用户源码。
另一部分通用能力,则依赖于Gundam cli 自己定义的生命周期,例如 开始初始化、初始化完成,postinstall 等等时机,能够按需执行一系列的操作。然后通过在运行时对hook的实际调用, 执行与相关基建工具的通信 或者是对 构建产物的修改, 从而达到能力注入的目的。
能力封装了就会黑盒吗
有同学看到这就会觉得,你这不就黑盒了吗,等于你帮我写了一堆代码,我在源码里都看不到,产物又是打包后了,看起来也费劲, 我要查问题怎么办啊?我要要做业务场景定制化怎么办?
同学你好,你先别急,听我解释:
这个问题主要是解决 Gundam 封装的能力,如何在业务需要时能够快速的理解其原理,方便排障、定位问题或者是准备应急预案,也就是把封装的能力不再黑盒。比如在这次新春除夕项目活动场景中,业务同学不会去编写容灾相关的逻辑,那如果上线后容灾功能出了问题,就只能找相关能力提供同学支持&着急了吗,这肯定不是我们所预期的。
对于黑盒透明化,我们从方案层面和工程层面两个方向来进行:
方案层面
方案层面主要分为三个步骤:评审、验收、演练。还是用上面提到的CDN容灾为例
-
评审:首先我们会提供详细的容灾方案,并且在各会场进行技术评审。即使不要业务同学参与开发,但是业务同学可以从方案中了解具体的原理,和一起评估案的可靠性和存在的风险。
-
验收:然后是接入相关能力插件提测,在测试环境跟随功能验收。这个过程能保证我们的方案不会影响到正常使用的业务逻辑。
-
演练:最后新春除夕项目的场景下,会有横向稳定性小组进行容灾演练,模拟一些故障注入来验证容灾逻辑的可靠性。
工程层面
动态可插拔:Gundam的能力都是由插件来提供,插件是对业务逻辑无侵入的,因此可以在排查问题的时候可以按需进行插拔,能够很容易得到一个较为“纯净”的项目,排除由插件“黑盒”产生的影响。
动态inspect:如果想进一步了解插件具体对运行时的改造和影响, Gundam对于运行时代码的注入,提供了inspect 的方式,可以看到Gundam 插件在构建时对源码具体做了哪些修改,当前是通过vite inspect 的方案来实现的。
以 Gundam 埋点插件 为例,埋点插件主要功能有三部分:
-
自动进行weblog实例创建
-
自动设置Radar+插件并设置RadarId
-
自动注册用于Weblogger埋点的Vue指令
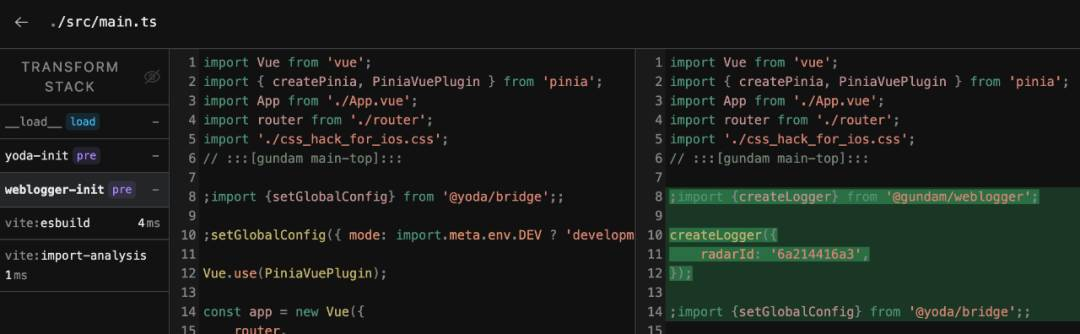
下图通过 inspect 展示了 Gundam weblogger 插件构建时在 src/main.ts 中注入一段 weblogger 引入并执行初始化的代码(没错radar应用也是自动申请好了):
自定义配置接管:如果需要进一步的业务定制,可以在Gundam提供的配置文件,比如配置雷达的采样率、weblogger上报公参列表等。
如果上面的方式还不满足,插件还提供 autoCreateWeblog 参数设置为 false 来关闭自动实例化行为, 然后采用业务代码手动实例化的方式。
可以看出,在尽可能提供开箱即用的情况下,我们仍然保留了降级方案。封装和扩展本来也不一定是一个对立的概念,这里的中庸之道就在于,在特定场景下提供尽可能的封装来提升效率,但是需要保留对扩展和场景定制的开放能力。同时在需要问题排查的场景下能够足够便利的将“黑盒”变得足够透明。
但我们要注意,选择降级方案虽然增加了灵活性,但是不可避免的降低了效率和需要花费更多的成本,理想情况下,我们希望通过封装方案结合特定场景就能解决问题。这个问题我们留到下一个章节讨论。
总结
封装的好处是,无需使用者感知具体实现细节,是对效率有帮助的,代价是出了问题难以排查和解决。Gundam在能力的实践中采用构建时注入的方式进行能力提供,可以不侵入用户的业务代码,一方面方便功能迭代升级, 另一方面在排查问题时能方便支持热插拔。在更进一步的场景中,还能支持用户按需运行时 inspect、 通过自定义的方式来接管配置,达到能力透明化的目的。
接下来讲一讲, 未来 Gundam 的发展方向。