
包阅导读总结
1. 关键词:Local LLM Messenger、AI/ML Hackathon、iMessage、GenAI、Docker
2. 总结:本文介绍了去年 Docker AI/ML Hackathon 的获奖项目 Local LLM Messenger,它能让用户通过 iMessage 与本地运行的 GenAI 模型交流,具有本地执行、可扩展性等特点,利用 Docker 等技术简化流程,文中还介绍了其工作原理、技术栈和使用方法。
3. 主要内容:
– Local LLM Messenger 项目
– 是 Docker AI/ML Hackathon 的获奖项目
– 由 Justin Garrison 创建
– 项目背景与意义
– 开发者致力于将 AI 与熟悉的消息平台集成
– 方便用户在熟悉界面与 AI 交流
– 项目特点
– 可在本地计算机运行,无需复杂设置和云服务
– 具有本地执行、可扩展性等多种优势
– 工作原理
– 展示了架构图,说明了各组件和交互
– 利用 Docker Compose 管理所需服务
– 技术栈
– 包括 lollmm 服务、ngrok、Ollama、Sendblue
– 开始使用
– 安装和设置相关组件
– 克隆仓库等操作
思维导图: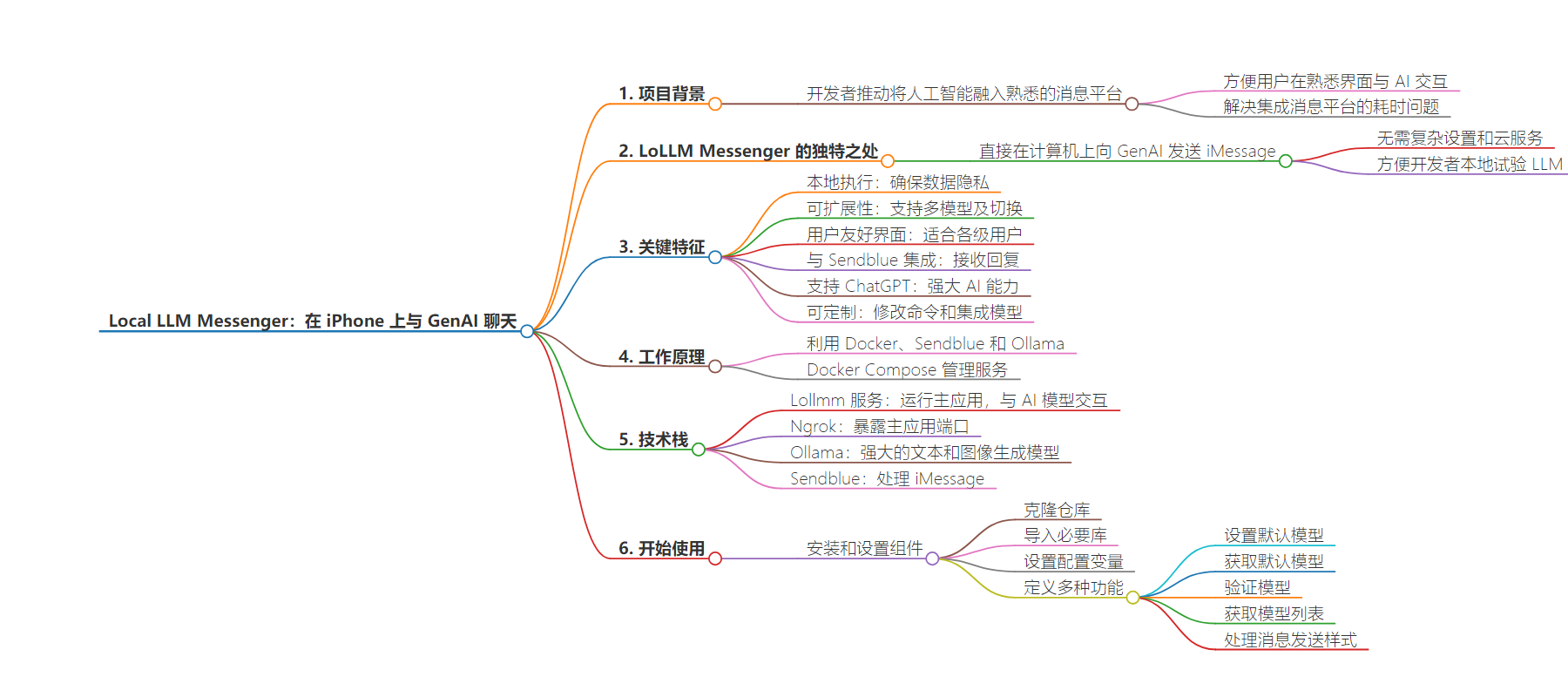
文章地址:https://www.docker.com/blog/local-llm-messenger-chat-with-genai-on-your-iphone/
文章来源:docker.com
作者:Ajeet Singh Raina
发布时间:2024/7/24 8:01
语言:英文
总字数:3298字
预计阅读时间:14分钟
评分:84分
标签:AI 集成,本地执行,Docker,生成式 AI,iMessage
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
In this AI/ML Hackathon post, we want to share another winning project from last year’s Docker AI/ML Hackathon. This time we will dive into Local LLM Messenger, an honorable mention winner created by Justin Garrison.
Developers are pushing the boundaries to bring the power of artificial intelligence (AI) to everyone. One exciting approach involves integrating Large Language Models (LLMs) with familiar messaging platforms like Slack and iMessage. This isn’t just about convenience; it’s about transforming these platforms into launchpads for interacting with powerful AI tools.

Imagine this: You need a quick code snippet or some help brainstorming solutions to coding problems. With LLMs integrated into your messaging app, you can chat with your AI assistant directly within the familiar interface to generate creative ideas or get help brainstorming solutions. No more complex commands or clunky interfaces — just a natural conversation to unlock the power of AI.
Integrating with messaging platforms can be a time-consuming task, especially for macOS users. That’s where Local LLM Messenger (LoLLMM) steps in, offering a streamlined solution for connecting with your AI via iMessage.
What makes LoLLM Messenger unique?
The following demo, which was submitted to the AI/ML Hackathon, provides an overview of LoLLM Messenger (Figure 1).
The LoLLM Messenger bot allows you to send iMessages to Generative AI (GenAI) models running directly on your computer. This approach eliminates the need for complex setups and cloud services, making it easier for developers to experiment with LLMs locally.
Key features of LoLLM Messenger
LoLLM Messenger includes impressive features that make it a standout among similar projects, such as:
- Local execution: Runs on your computer, eliminating the need for cloud-based services and ensuring data privacy.
- Scalability: Handles multiple AI models simultaneously, allowing users to experiment with different models and switch between them easily.
- User-friendly interface: Offers a simple and intuitive interface, making it accessible to users of all skill levels.
- Integration with Sendblue: Integrates seamlessly with Sendblue, enabling users to send iMessages to the bot and receive responses directly in their inbox.
- Support for ChatGPT: Supports the GPT-3.5 Turbo and DALL-E 2 models, providing users with access to powerful AI capabilities.
- Customization: Allows users to customize the bot’s behavior by modifying the available commands and integrating their own AI models.
How does it work?
The architecture diagram shown in Figure 2 provides a high-level overview of the components and interactions within the LoLLM Messenger project. It illustrates how the main application, AI models, messaging platform, and external APIs work together to enable users to send iMessages to AI models running on their computers.

By leveraging Docker, Sendblue, and Ollama, LoLLM Messenger offers a seamless and efficient solution for those seeking to explore AI models without the need for cloud-based services. LoLLM Messenger utilizes Docker Compose to manage the required services.
Docker Compose simplifies the process by handling the setup and configuration of multiple containers, including the main application, ngrok (for creating a secure tunnel), and Ollama (a server that bridges the gap between messaging apps and AI models).
Technical stack
The LoLLM Messenger tech stack includes:
- Lollmm service: This service is responsible for running the main application. It handles incoming iMessages, processing user requests, and interacting with the AI models. The lollmm service communicates with the Ollama model, which is a powerful AI model for text and image generation.
- Ngrok: This service is used to expose the main application’s port 8000 to the internet using
ngrok. It runs in the Alpine image and forwards traffic from port 8000 to the ngrok tunnel. The service is set to run in the host network mode. - Ollama: This service runs the Ollama model, which is a powerful AI model for text and image generation. It listens on port 11434 and mounts a volume from
./run/ollamato/home/ollama. The service is set to deploy with GPU resources, ensuring that it can utilize an NVIDIA GPU if available. - Sendblue: The project integrates with Sendblue to handle iMessages. You can set up Sendblue by adding your API Key and API Secret in the
app/.envfile and adding your phone number as a Sendblue contact.
Getting started
To get started, ensure that you have installed and set up the following components:
Clone the repository
Open a terminal window and run the following command to clone this sample application:
git clone https://github.com/dockersamples/local-llm-messenger
You should now have the following files in your local-llm-messenger directory:
.├── LICENSE├── README.md├── app│ ├── Dockerfile│ ├── Pipfile│ ├── Pipfile.lock│ ├── default.ai│ ├── log_conf.yaml│ └── main.py├── docker-compose.yaml├── img│ ├── banner.png│ ├── lasers.gif│ └── lollm-demo-1.gif├── justfile└── test ├── msg.json └── ollama.json4 directories, 15 files
The script main.py file under the /app directory is a Python script that uses the FastAPI framework to create a web server for an AI-powered messaging application. The script interacts with OpenAI’s GPT-3 model and an Ollama endpoint for generating responses. It uses Sendblue’s API for sending messages.
The script first imports necessary libraries, including FastAPI, requests, logging, and other required modules.
from dotenv import load_dotenvimport os, requests, time, openai, json, loggingfrom pprint import pprintfrom typing import Union, Listfrom fastapi import FastAPIfrom pydantic import BaseModelfrom sendblue import Sendblue
This section sets up configuration variables, such as API keys, callback URL, Ollama API endpoint, and maximum context and word limits.
SENDBLUE_API_KEY = os.environ.get("SENDBLUE_API_KEY")SENDBLUE_API_SECRET = os.environ.get("SENDBLUE_API_SECRET")openai.api_key = os.environ.get("OPENAI_API_KEY")OLLAMA_API = os.environ.get("OLLAMA_API_ENDPOINT", "http://ollama:11434/api")# could also use request.headers.get('referer') to do dynamicallyCALLBACK_URL = os.environ.get("CALLBACK_URL")MAX_WORDS = os.environ.get("MAX_WORDS")
Next, the script performs the logging configuration, setting the log level to INFO. Creates a file handler for logging messages to a file named app.log.
It then defines various functions for interacting with the AI models, managing context, sending messages, handling callbacks, and executing slash commands.
def set_default_model(model: str): try: with open("default.ai", "w") as f: f.write(model) f.close() return except IOError: logger.error("Could not open file") exit(1)def get_default_model() -> str: try: with open("default.ai") as f: default = f.readline().strip("\n") f.close() if default != "": return default else: set_default_model("llama2:latest") return "" except IOError: logger.error("Could not open file") exit(1)def validate_model(model: str) -> bool: available_models = get_model_list() if model in available_models: return True else: return Falsedef get_ollama_model_list() -> List[str]: available_models = [] tags = requests.get(OLLAMA_API + "/tags") all_models = json.loads(tags.text) for model in all_models["models"]: available_models.append(model["name"]) return available_modelsdef get_openai_model_list() -> List[str]: return ["gpt-3.5-turbo", "dall-e-2"]def get_model_list() -> List[str]: ollama_models = [] openai_models = [] all_models = [] if "OPENAI_API_KEY" in os.environ: # print(openai.Model.list()) openai_models = get_openai_model_list() ollama_models = get_ollama_model_list() all_models = ollama_models + openai_models return all_modelsDEFAULT_MODEL = get_default_model()if DEFAULT_MODEL == "": # This is probably the first run so we need to install a model if "OPENAI_API_KEY" in os.environ: print("No default model set. openai is enabled. using gpt-3.5-turbo") DEFAULT_MODEL = "gpt-3.5-turbo" else: print("No model found and openai not enabled. Installing llama2:latest") pull_data = '{"name": "llama2:latest","stream": false}' try: pull_resp = requests.post(OLLAMA_API + "/pull", data=pull_data) pull_resp.raise_for_status() except requests.exceptions.HTTPError as err: raise SystemExit(err) set_default_model("llama2:latest") DEFAULT_MODEL = "llama2:latest"if validate_model(DEFAULT_MODEL): logger.info("Using model: " + DEFAULT_MODEL)else: logger.error("Model " + DEFAULT_MODEL + " not available.") logger.info(get_model_list()) pull_data = '{"name": "' + DEFAULT_MODEL + '","stream": false}' try: pull_resp = requests.post(OLLAMA_API + "/pull", data=pull_data) pull_resp.raise_for_status() except requests.exceptions.HTTPError as err: raise SystemExit(err)def set_msg_send_style(received_msg: str): """Will return a style for the message to send based on matched words in received message""" celebration_match = ["happy"] shooting_star_match = ["star", "stars"] fireworks_match = ["celebrate", "firework"] lasers_match = ["cool", "lasers", "laser"] love_match = ["love"] confetti_match = ["yay"] balloons_match = ["party"] echo_match = ["what did you say"] invisible_match = ["quietly"] gentle_match = [] loud_match = ["hear"] slam_match = [] received_msg_lower = received_msg.lower() if any(x in received_msg_lower for x in celebration_match): return "celebration" elif any(x in received_msg_lower for x in shooting_star_match): return "shooting_star" elif any(x in received_msg_lower for x in fireworks_match): return "fireworks" elif any(x in received_msg_lower for x in lasers_match): return "lasers" elif any(x in received_msg_lower for x in love_match): return "love" elif any(x in received_msg_lower for x in confetti_match): return "confetti" elif any(x in received_msg_lower for x in balloons_match): return "balloons" elif any(x in received_msg_lower for x in echo_match): return "echo" elif any(x in received_msg_lower for x in invisible_match): return "invisible" elif any(x in received_msg_lower for x in gentle_match): return "gentle" elif any(x in received_msg_lower for x in loud_match): return "loud" elif any(x in received_msg_lower for x in slam_match): return "slam" else: return
Two classes, Msg and Callback, are defined to represent the structure of incoming messages and callback data. The code also includes various functions and classes to handle different aspects of the messaging platform, such as setting default models, validating models, interacting with the Sendblue API, and processing messages. It also includes functions to handle slash commands, create messages from context, and append context to a file.
class Msg(BaseModel): accountEmail: str content: str media_url: str is_outbound: bool status: str error_code: int | None = None error_message: str | None = None message_handle: str date_sent: str date_updated: str from_number: str number: str to_number: str was_downgraded: bool | None = None plan: strclass Callback(BaseModel): accountEmail: str content: str is_outbound: bool status: str error_code: int | None = None error_message: str | None = None message_handle: str date_sent: str date_updated: str from_number: str number: str to_number: str was_downgraded: bool | None = None plan: strdef msg_openai(msg: Msg, model="gpt-3.5-turbo"): """Sends a message to openai""" message_with_context = create_messages_from_context("openai") # Add the user's message and system context to the messages list messages = [ {"role": "user", "content": msg.content}, {"role": "system", "content": "You are an AI assistant. You will answer in haiku."}, ] # Convert JSON strings to Python dictionaries and add them to messages messages.extend( [ json.loads(line) # Convert each JSON string back into a dictionary for line in message_with_context ] ) # Send the messages to the OpenAI model gpt_resp = client.chat.completions.create( model=model, messages=messages, ) # Append the system context to the context file append_context("system", gpt_resp.choices[0].message.content) # Send a message to the sender msg_response = sendblue.send_message( msg.from_number, { "content": gpt_resp.choices[0].message.content, "status_callback": CALLBACK_URL, }, ) returndef msg_ollama(msg: Msg, model=None): """Sends a message to the ollama endpoint""" if model is None: logger.error("Model is None when calling msg_ollama") return # Optionally handle the case more gracefully ollama_headers = {"Content-Type": "application/json"} ollama_data = ( '{"model":"' + model + '", "stream": false, "prompt":"' + msg.content + " in under " + str(MAX_WORDS) + # Make sure MAX_WORDS is a string ' words"}' ) ollama_resp = requests.post( OLLAMA_API + "/generate", headers=ollama_headers, data=ollama_data ) response_dict = json.loads(ollama_resp.text) if ollama_resp.ok: send_style = set_msg_send_style(msg.content) append_context("system", response_dict["response"]) msg_response = sendblue.send_message( msg.from_number, { "content": response_dict["response"], "status_callback": CALLBACK_URL, "send_style": send_style, }, ) else: msg_response = sendblue.send_message( msg.from_number, { "content": "I'm sorry, I had a problem processing that question. Please try again.", "status_callback": CALLBACK_URL, }, ) return
Navigate to the app/ directory and create a new file for adding environment variables.
touch .envSENDBLUE_API_KEY=your_sendblue_api_keySENDBLUE_API_SECRET=your_sendblue_api_secretOLLAMA_API_ENDPOINT=http://host.docker.internal:11434/apiOPENAI_API_KEY=your_openai_api_key
Next, add the ngrok authtoken to the Docker Compose file. You can get the authtoken from this link.
services: lollm: build: ./app # command: # - sleep # - 1d ports: - 8000:8000 env_file: ./app/.env volumes: - ./run/lollm:/run/lollm depends_on: - ollama restart: unless-stopped network_mode: "host" ngrok: image: ngrok/ngrok:alpine command: - "http" - "8000" - "--log" - "stdout" environment: - NGROK_AUTHTOKEN=2i6iXXXXXXXXhpqk1aY1 network_mode: "host" ollama: image: ollama/ollama ports: - 11434:11434 volumes: - ./run/ollama:/home/ollama network_mode: "host"
Running the application stack
Next, you can run the application stack, as follows:
You will see output similar to the following:
[+] Running 4/4 ✔ Container local-llm-messenger-ollama-1 Create... 0.0s ✔ Container local-llm-messenger-ngrok-1 Created 0.0s ✔ Container local-llm-messenger-lollm-1 Recreat... 0.1s ! lollm Published ports are discarded when using host network mode 0.0sAttaching to lollm-1, ngrok-1, ollama-1ollama-1 | 2024/06/20 03:14:46 routes.go:1011: INFO server config env="map[OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_TMPDIR:]"ollama-1 | time=2024-06-20T03:14:46.308Z level=INFO source=images.go:725 msg="total blobs: 0"ollama-1 | time=2024-06-20T03:14:46.309Z level=INFO source=images.go:732 msg="total unused blobs removed: 0"ollama-1 | time=2024-06-20T03:14:46.309Z level=INFO source=routes.go:1057 msg="Listening on [::]:11434 (version 0.1.44)"ollama-1 | time=2024-06-20T03:14:46.309Z level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2210839504/runnersngrok-1 | t=2024-06-20T03:14:46+0000 lvl=info msg="open config file" path=/var/lib/ngrok/ngrok.yml err=nilngrok-1 | t=2024-06-20T03:14:46+0000 lvl=info msg="open config file" path=/var/lib/ngrok/auth-config.yml err=nilngrok-1 | t=2024-06-20T03:14:46+0000 lvl=info msg="starting web service" obj=web addr=0.0.0.0:4040 allow_hosts=[]ngrok-1 | t=2024-06-20T03:14:46+0000 lvl=info msg="client session established" obj=tunnels.sessionngrok-1 | t=2024-06-20T03:14:46+0000 lvl=info msg="tunnel session started" obj=tunnels.sessionngrok-1 | t=2024-06-20T03:14:46+0000 lvl=info msg="started tunnel" obj=tunnels name=command_line addr=http://localhost:8000 url=https://94e1-223-185-128-160.ngrok-free.appollama-1 | time=2024-06-20T03:14:48.602Z level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cuda_v11]"ollama-1 | time=2024-06-20T03:14:48.603Z level=INFO source=types.go:71 msg="inference compute" id=0 library=cpu compute="" driver=0.0 name="" total="7.7 GiB" available="3.9 GiB"lollm-1 | INFO: Started server process [1]lollm-1 | INFO: Waiting for application startup.lollm-1 | INFO: Application startup complete.lollm-1 | INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)ngrok-1 | t=2024-06-20T03:16:58+0000 lvl=info msg="join connections" obj=join id=ce119162e042 l=127.0.0.1:8000 r=[2401:4900:8838:8063:f0b0:1866:e957:b3ba]:54384lollm-1 | OLLAMA API IS http://host.docker.internal:11434/apilollm-1 | INFO: 2401:4900:8838:8063:f0b0:1866:e957:b3ba:0 - "GET / HTTP/1.1" 200 OK
If you’re testing it on a system without an NVIDIA GPU, then you can skip the deploy attribute of the Compose file.
Watch the output for your ngrok endpoint. In our case, it shows: https://94e1-223-185-128-160.ngrok-free.app/
Next, append /msg to the following ngrok webhooks URL:https://94e1-223-185-128-160.ngrok-free.app/
Then, add it under the webhooks URL section on Sendblue and save it (Figure 3). The ngrok service is configured to expose the lollmm service on port 8000 and provide a secure tunnel to the public internet using the ngrok.io domain.
The ngrok service logs indicate that it has started the web service and established a client session with the tunnels. They also show that the tunnel session has started and has been successfully established with the lollmm service.
The ngrok service is configured to use the specified ngrok authentication token, which is required to access the ngrok service. Overall, the ngrok service is running correctly and is able to establish a secure tunnel to the lollmm service.

Ensure that there are no error logs when you run the ngrok container (Figure 4).

Ensure that the LoLLM Messenger container is actively up and running (Figure 5).

The logs show that the Ollama service has opened the specified port (11434) and is listening for incoming connections. The logs also indicate that the Ollama service has mounted the /home/ollama directory from the host machine to the /home/ollama directory within the container.
Overall, the Ollama service is running correctly and is ready to provide AI models for inference.
Testing the functionality
To test the functionality of the lollm service, you first need to add your contact number to the Sendblue dashboard. Then you should be able to send messages to the Sendblue number and observe the responses from the lollmm service (Figure 6).

The Sendblue platform will send HTTP requests to the /msg endpoint of your lollmm service, and your lollmm service will process these requests and return the appropriate responses.
- The lollmm service is set up to listen on port 8000.
- The ngrok tunnel is started and provides a public URL, such as https://94e1-223-185-128-160.ngrok-free.app.
- The lollmm service receives HTTP requests from the ngrok tunnel, including GET requests to the root path (
/) and other paths, such as/favicon.ico,/predict,/mdg, and/msg. - The lollmm service responds to these requests with appropriate HTTP status codes, such as 200 OK for successful requests and 404 Not Found for requests to paths that do not exist.
- The ngrok tunnel logs the join connections, indicating that clients are connecting to the lollmm service through the ngrok tunnel.
 And Responses In Chat. - F7 Sending Messages E1721152150910")
The first time you chat with LLM by typing /list (Figure 7), you can check the logs as shown:
ngrok-1 | t=2024-07-09T02:34:30+0000 lvl=info msg="join connections" obj=join id=12bd50a8030b l=127.0.0.1:8000 r=18.223.220.3:44370lollm-1 | OLLAMA API IS http://host.docker.internal:11434/apilollm-1 | INFO: 18.223.220.3:0 - "POST /msg HTTP/1.1" 200 OKngrok-1 | t=2024-07-09T02:34:53+0000 lvl=info msg="join connections" obj=join id=259fda936691 l=127.0.0.1:8000 r=18.223.220.3:36712lollm-1 | INFO: 18.223.220.3:0 - "POST /msg HTTP/1.1" 200 OK
Next, let’s install the codellama model by typing /install codellama:latest (Figure 8).

You can see the following container logs once you set the default model to codellama:latest as shown:
ngrok-1 | t=2024-07-09T03:39:23+0000 lvl=info msg="join connections" obj=join id=026d8fad5c87 l=127.0.0.1:8000 r=18.223.220.3:36282lollm-1 | setting default model lollm-1 | INFO: 18.223.220.3:0 - "POST /msg HTTP/1.1" 200 OK
The lollmm service is running correctly and can handle HTTP requests from the ngrok tunnel. You can use the ngrok tunnel URL to test the functionality of the lollmm service by sending HTTP requests to the appropriate paths (Figure 9).

Conclusion
LoLLM Messenger is a valuable tool for developers and enthusiasts looking to push the boundaries of LLM integration within messaging apps. It allows developers to craft custom chatbots for specific needs, add real-time sentiment analysis to messages, or explore entirely new AI features in your messaging experience.
To get started, you can explore the LoLLM Messenger project on GitHub and discover the potential of local LLM.