
包阅导读总结
1. 关键词:GenAI、RAG、复杂性、挑战、解决方案
2. 总结:本文介绍了 RAG 在 GenAI 应用中的重要性,虽带来诸多优势如增强专业化、提高效率等,但也带来新的复杂性和挑战,包括交通管理、安全合规、数据质量等,成功部署需精心规划。
3. 主要内容:
– 介绍 RAG 成为 GenAI 应用的必要元素,能赋予模型专业化能力
– 解释 RAG 工作原理,通过外部数据增强 AI 推理,带来更丰富准确的响应
– 列举 RAG 的好处,如降低训练成本、提高可扩展性、更易更新、保证实时相关性
– 指出 RAG 带来的挑战
– 交通管理方面,增加数据流量可能导致瓶颈,影响应用性能和信息质量
– 安全和合规方面,访问数据源存在风险,需严格保障数据安全和符合规定
– 数据质量和相关性方面,取决于所检索数据质量,低质或无关数据会导致输出不准确
– 强调成功部署 RAG 需规划和思考,做好交通管理等工作,以充分发挥其优势
思维导图: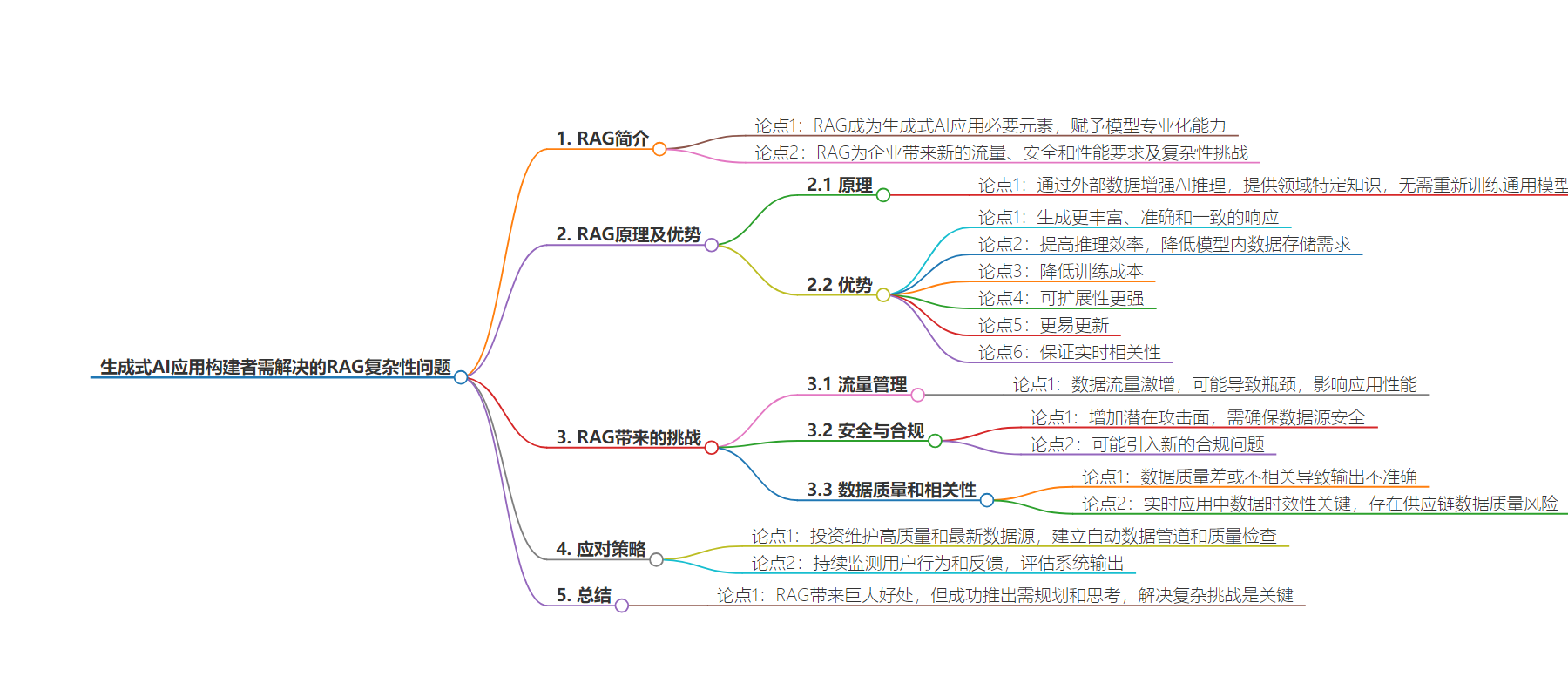
文章地址:https://thenewstack.io/genai-app-builders-must-solve-new-rag-complexity/
文章来源:thenewstack.io
作者:Brett Wolmerans
发布时间:2024/8/7 16:32
语言:英文
总字数:966字
预计阅读时间:4分钟
评分:90分
标签:RAG,生成式 AI,AI 基础设施,流量管理,安全
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Retrieval-augmented generation (RAG) is quickly becoming a necessary element of generative AI applications. RAG endows pretrained AI models with superpowers of specialization, making them precise and accurate for vertical or task-specific applications. However, RAG also introduces new requirements around traffic, security and performance into your GenAI stack. With RAG comes new complexity and challenges that enterprises need to tackle with more sophisticated AI infrastructure.
A Quick RAG Primer
RAG works by enhancing AI inferencing with relevant information from external data stores not included in the training corpus of the foundational model. This method provides the AI model with domain-specific knowledge without having to retrain the general model. In general, RAG models produce responses that are richer in context, more accurate and factually consistent. RAG can even be used to improve the performance of open-domain AI applications. RAG also makes AI inferencing more efficient by reducing the need for in-model data storage. This has several beneficial spillover effects.
RAG models can be smaller and more efficient because they do not need to encode all possible knowledge within their parameters. Instead, they can dynamically fetch information as needed. This can lead to reduced memory requirements and lower computational costs, as the model doesn’t need to store and process a vast amount of information internally.
- Lower training costs: While the retrieval mechanism is primarily used during inference, the ability to train smaller models that rely on external data sources can reduce the overall training costs. Smaller models typically require less computational power and time to train, leading to cost savings.
- Scalability: RAG architectures can scale more effectively by distributing the load between the generative model and the retrieval system. This separation allows for better resource allocation and optimization, reducing the overall computational burden on any single component.
- Easier updates: Since RAG uses an external knowledge base that can be easily updated, there’s no need to frequently retrain the entire model to incorporate new information. This reduces the need for continuous, expensive retraining processes, allowing for cost-efficient updates to the model’s knowledge.
- Real-time relevance: Because of the time it takes to train models, many types of data become stale relatively quickly. By fetching data in real time, RAG ensures that the information used for generation is always current. This also makes GenAI apps better for real-time tasks, like turn-by-turn guidance in a car or weather reports, to name two examples.
While the benefits of RAG are manifest, adding what is effectively a new layer of queries, routing and traffic management adds additional complexity and security challenges.
Traffic Management
One of the primary challenges with RAG is the increased complexity in managing traffic. RAG architectures rely on retrieving relevant documents or pieces of information in real time. This can lead to a significant surge in data traffic, which can cause bottlenecks if not managed properly. It also means that application performance depends not only on what the end user experiences from a latency and responsiveness standpoint, but also on information quality. If RAG is slow, the GenAI may still respond but with lower-quality outputs.
Security and Compliance Concerns
Security is another major concern when integrating RAG into GenAI applications. Retrieval often requires accessing proprietary databases or knowledge bases, increasing the potential attack surface. Ensuring the integrity and security of these data sources is critical to prevent data breaches or unauthorized access. RAG can also introduce new compliance issues if the data being accessed falls under regulations such as those required for finance or health care industries. Often the RAG layer is the logical place for this data, but that also means the RAG database must comply with all required regulations (HIPAA, Gramm-Leach Bliley, SOC2, etc.).
Teams should adopt robust authentication and authorization mechanisms to secure their RAG infrastructure and data retrieval process. This also means adopting robust API security for any service — internal or external — accessing a RAG stack. Employing encryption for RAG data in transit and at rest can safeguard sensitive information. Because RAG is where much of the sensitive data lies, it is also a good place for stricter authentication policies and zero trust deployments.
Data Quality and Relevance
The effectiveness of a RAG system heavily depends on the quality of the data it retrieves. Poor quality or irrelevant data can lead to inaccurate or nonsensical outputs from the generative model. With real-time applications, data recency is also critical. If the RAG system is pulling from third-party data sources, then the GenAI application is subject to supply chain data quality risks. For enterprise apps or apps in sensitive areas like medicine or law, tolerance for bad responses due to poor data quality is close to zero.
To overcome this, teams should invest in maintaining high-quality and up-to-date data sources, and build automated data pipelines with redundant quality checks. They also should continuously monitor user behaviors and feedback for signs of data quality problems. Continuous monitoring and evaluation of the system’s output can also provide insights into areas that need improvement.
Don’t Get Run RAGged
If you are delivering GenAI applications, you likely have RAG in your present or in your future. The benefits are tremendous. However, successful RAG rollouts require planning and thought. While RAG introduces significant benefits by enhancing the specialization and accuracy of generative AI applications, it also brings a set of complex challenges. Effective traffic management, stringent security measures, performance optimization, ensuring data quality and handling integration complexity are essential to successfully implementing RAG in GenAI stacks. For application delivery teams wrestling with GenAI challenges, RAG is a powerful way to make almost everything in their AI apps run better — with the right preparation and mindset.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.