
包阅导读总结
1.
关键词:Hugging Face、Ollama、Testcontainers、AI 模型、程序运行
2.
总结:本文介绍了如何使用 Ollama 和 Testcontainers 以编程方式运行 Hugging Face 模型,包括基本设置、模型运行、处理容器情况、使用 Hugging Face 模型、自定义容器及此方法的优势,强调其简化开发环境设置,便于开发者使用。
3.
主要内容:
– 引言
– Hugging Face 模型众多,集成需求增加但入门障碍高
– 介绍 Ollama 和 Testcontainers
– Ollama 支持运行 Hugging Face 模型
– Testcontainers 提供 Ollama 模块,可轻松启动容器
– 运行 Ollama 中的模型
– 需下载所需模型
– 可通过代码创建包含模型的镜像
– 使用 Hugging Face 模型
– 需要 GGUF 文件,步骤简单,可通过自定义容器运行
– 自定义容器
– 以 TinyLlama 为例,展示定制化容器的实现
– 此方法的优势
– 编程访问、可重复配置、熟悉工作流、自动设置
– 结论
– 结合 Ollama 和 Testcontainers 可简化模型集成,助力开发
思维导图: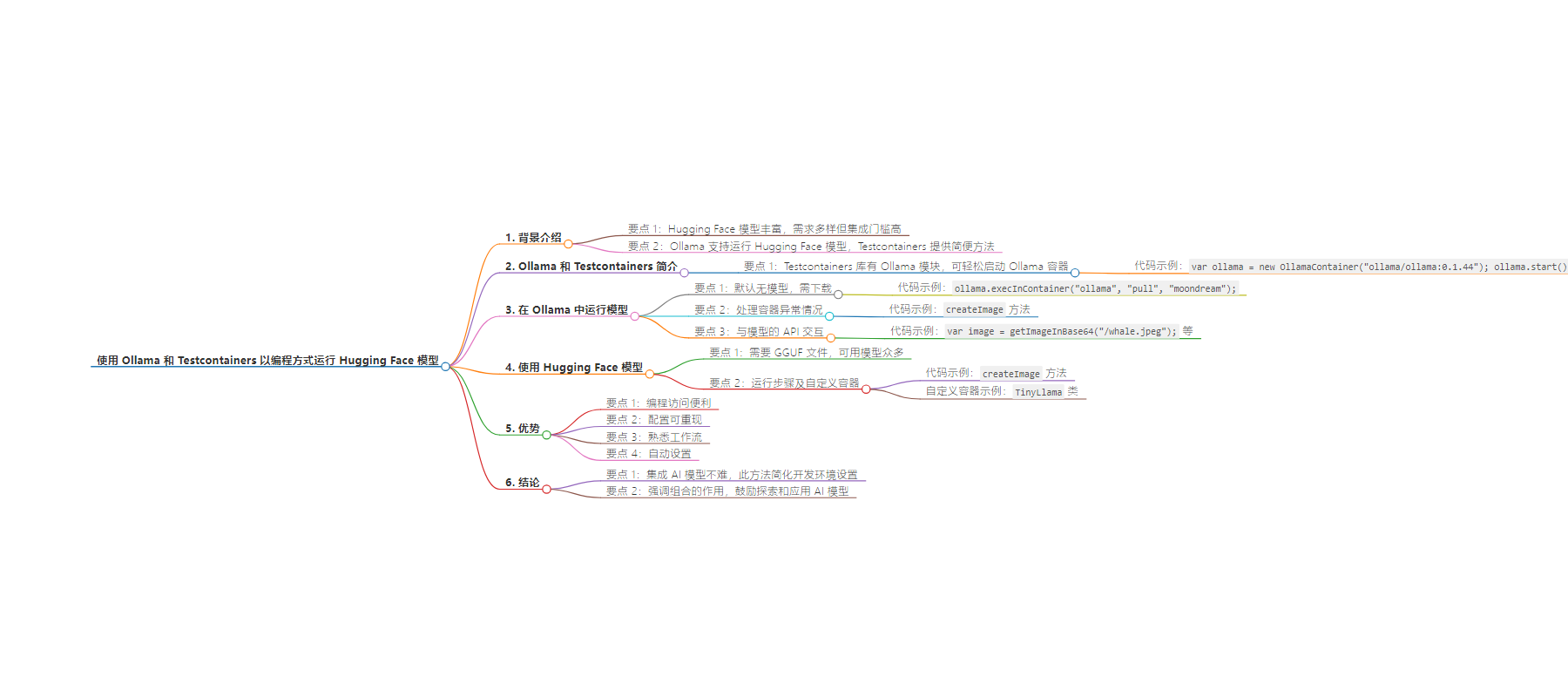
文章来源:docker.com
作者:Ignasi Lopez Luna
发布时间:2024/7/16 10:35
语言:英文
总字数:1293字
预计阅读时间:6分钟
评分:85分
标签:Hugging Face,Ollama,Testcontainers,AI/ML 集成,容器化
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Hugging Face now hosts more than 700,000 models, with the number continuously rising. It has become the premier repository for AI/ML models, catering to both general and highly specialized needs.
As the adoption of AI/ML models accelerates, more application developers are eager to integrate them into their projects. However, the entry barrier remains high due to the complexity of setup and lack of developer-friendly tools. Imagine if deploying an AI/ML model could be as straightforward as spinning up a database. Intrigued? Keep reading to find out how.

Introduction to Ollama and Testcontainers
Recently, Ollama announced support for running models from Hugging Face. This development is exciting because it brings the rich ecosystem of AI/ML components from Hugging Face to Ollama end users, who are often developers.
Testcontainers libraries already provide an Ollama module, making it straightforward to spin up a container with Ollama without needing to know the details of how to run Ollama using Docker:
import org.testcontainers.ollama.OllamaContainer; var ollama = new OllamaContainer("ollama/ollama:0.1.44"); ollama.start();
These lines of code are all that is needed to have Ollama running inside a Docker container effortlessly.
Running models in Ollama
By default, Ollama does not include any models, so you need to download the one you want to use. With Testcontainers, this step is straightforward by leveraging the execInContainer API provided by Testcontainers:
ollama.execInContainer("ollama", "pull", "moondream");
At this point, you have the moondream model ready to be used via the Ollama API.
Excited to try it out? Hold on for a bit. This model is running in a container, so what happens if the container dies? Will you need to spin up a new container and pull the model again? Ideally not, as these models can be quite large.
Thankfully, Testcontainers makes it easy to handle this scenario, by providing an easy-to-use API to commit a container image programmatically:
public void createImage(String imageName) {var ollama = new OllamaContainer("ollama/ollama:0.1.44");ollama.start();ollama.execInContainer("ollama", "pull", "moondream");ollama.commitToImage(imageName);}
This code creates an image from the container with the model included. In subsequent runs, you can create a container from that image, and the model will already be present. Here’s the pattern:
var imageName = "tc-ollama-moondream";var ollama = new OllamaContainer(DockerImageName.parse(imageName).asCompatibleSubstituteFor("ollama/ollama:0.1.44"));try {ollama.start();} catch (ContainerFetchException ex) {// If image doesn't exist, create it. Subsequent runs will reuse the image.createImage(imageName);ollama.start();}
Now, you have a model ready to be used, and because it is running in Ollama, you can interact with its API:
var image = getImageInBase64("/whale.jpeg");String response = given().baseUri(ollama.getEndpoint()).header(new Header("Content-Type", "application/json")).body(new CompletionRequest("moondream:latest", "Describe the image.", Collections.singletonList(image), false)).post("/api/generate").getBody().as(CompletionResponse.class).response();System.out.println("Response from LLM " + response);
Using Hugging Face models
The previous example demonstrated using a model already provided by Ollama. However, with the ability to use Hugging Face models in Ollama, your available model options have now expanded by thousands.
To use a model from Hugging Face in Ollama, you need a GGUF file for the model.Currently, there are 20,647 models available in GGUF format. How cool is that?
The steps to run a Hugging Face model in Ollama are straightforward, but we’ve simplified the process further by scripting it into a custom OllamaHuggingFaceContainer. Note that this custom container is not part of the default library, so you can copy and paste the implementation of OllamaHuggingFaceContainer and customize it to suit your needs.
To run a Hugging Face model, do the following:
public void createImage(String imageName, String repository, String model) {var model = new OllamaHuggingFaceContainer.HuggingFaceModel(repository, model);var huggingFaceContainer = new OllamaHuggingFaceContainer(hfModel);huggingFaceContainer.start();huggingFaceContainer.commitToImage(imageName);}
By providing the repository name and the model file as shown, you can run Hugging Face models in Ollama via Testcontainers.
You can find an example using an embedding model and an example using a chat model on GitHub.
Customize your container
One key strength of using Testcontainers is its flexibility in customizing container setups to fit specific project needs by encapsulating complex setups into manageable containers.
For example, you can create a custom container tailored to your requirements. Here’s an example of TinyLlama, a specialized container for spinning up theDavidAU/DistiLabelOrca-TinyLLama-1.1B-Q8_0-GGUF model from Hugging Face:
public class TinyLlama extends OllamaContainer { private final String imageName; public TinyLlama(String imageName) { super(DockerImageName.parse(imageName).asCompatibleSubstituteFor("ollama/ollama:0.1.44")); this.imageName = imageName; } public void createImage(String imageName) { var ollama = new OllamaContainer("ollama/ollama:0.1.44"); ollama.start(); try { ollama.execInContainer("apt-get", "update"); ollama.execInContainer("apt-get", "upgrade", "-y"); ollama.execInContainer("apt-get", "install", "-y", "python3-pip"); ollama.execInContainer("pip", "install", "huggingface-hub"); ollama.execInContainer( "huggingface-cli", "download", "DavidAU/DistiLabelOrca-TinyLLama-1.1B-Q8_0-GGUF", "distilabelorca-tinyllama-1.1b.Q8_0.gguf", "--local-dir", "." ); ollama.execInContainer( "sh", "-c", String.format("echo '%s' > Modelfile", "FROM distilabelorca-tinyllama-1.1b.Q8_0.gguf") ); ollama.execInContainer("ollama", "create", "distilabelorca-tinyllama-1.1b.Q8_0.gguf", "-f", "Modelfile"); ollama.execInContainer("rm", "distilabelorca-tinyllama-1.1b.Q8_0.gguf"); ollama.commitToImage(imageName); } catch (IOException | InterruptedException e) { throw new ContainerFetchException(e.getMessage()); } } public String getModelName() { return "distilabelorca-tinyllama-1.1b.Q8_0.gguf"; } @Override public void start() { try { super.start(); } catch (ContainerFetchException ex) { // If image doesn't exist, create it. Subsequent runs will reuse the image. createImage(imageName); super.start(); } }}
Once defined, you can easily instantiate and utilize your custom container in your application:
var tinyLlama = new TinyLlama("example");tinyLlama.start();String response = given().baseUri(tinyLlama.getEndpoint()).header(new Header("Content-Type", "application/json")).body(new CompletionRequest(tinyLlama.getModelName() + ":latest", List.of(new Message("user", "What is the capital of France?")), false)).post("/api/chat").getBody().as(ChatResponse.class).message.content;System.out.println("Response from LLM " + response);
Note how all the implementation details are under the cover of the TinyLlama class, and the end user doesn’t need to know how to actually install the model into Ollama, what GGUF is, or that to get huggingface-cli you need to pip install huggingface-hub.
Advantages of this approach
- Programmatic access: Developers gain seamless programmatic access to the Hugging Face ecosystem.
- Reproducible configuration: All configuration, from setup to lifecycle management is codified, ensuring reproducibility across team members and CI environments.
- Familiar workflows: By using containers, developers familiar with containerization can easily integrate AI/ML models, making the process more accessible.
- Automated setups: Provides a straightforward clone-and-run experience for developers.
This approach leverages the strengths of both Hugging Face and Ollama, supported by the automation and encapsulation provided by the Testcontainers module, making powerful AI tools more accessible and manageable for developers across different ecosystems.
Conclusion
Integrating AI models into applications need not be a daunting task. By leveraging Ollama and Testcontainers, developers can seamlessly incorporate Hugging Face models into their projects with minimal effort. This approach not only simplifies the setup of the development environment process but also ensures reproducibility and ease of use. With the ability to programmatically manage models and containerize them for consistent environments, developers can focus on building innovative solutions without getting bogged down by complex setup procedures.
The combination of Ollama’s support for Hugging Face models and Testcontainers’ robust container management capabilities provides a powerful toolkit for modern AI development. As AI continues to evolve and expand, these tools will play a crucial role in making advanced models accessible and manageable for developers across various fields. So, dive in, experiment with different models, and unlock the potential of AI in your applications today.
Stay current on the latest Docker news. Subscribe to the Docker Newsletter.