
包阅导读总结
1. 关键词:Artificial Intelligence、History、Progress、Lessons、Innovation
2. 总结:本文探讨了人工智能的发展历程,从古代梦想至现代突破,包括起源、早期成果等,还提到为解答父亲关于AI发展的疑问而创作,指出理解过去才能预见未来,并总结了AI发展的三个关键教训。
3. 主要内容:
– AI的发展与现状:
– 从科幻走向现实,发展迅速,作者为解答父亲疑问创作本文。
– AI的起源:
– 古代人类就有创造人工生命和智能的梦想,如希腊、中国神话。
– 思考机器的曙光:
– 20世纪50年代,阿兰·图灵提出“机器能否思考”及“图灵测试”。
– 克劳德·香农展示机器学习,发明Theseus鼠标。
– 1956年达特茅斯研讨会正式创立AI领域,多位先驱参会,出现多个重要成果。
– 1958年构建第一个人工神经网络模型。
– AI发展的关键教训:
– 强调协作和开放分享理念的力量。
– 虽有发展低谷,但不必在意。
– 发展速度不断加快。
思维导图: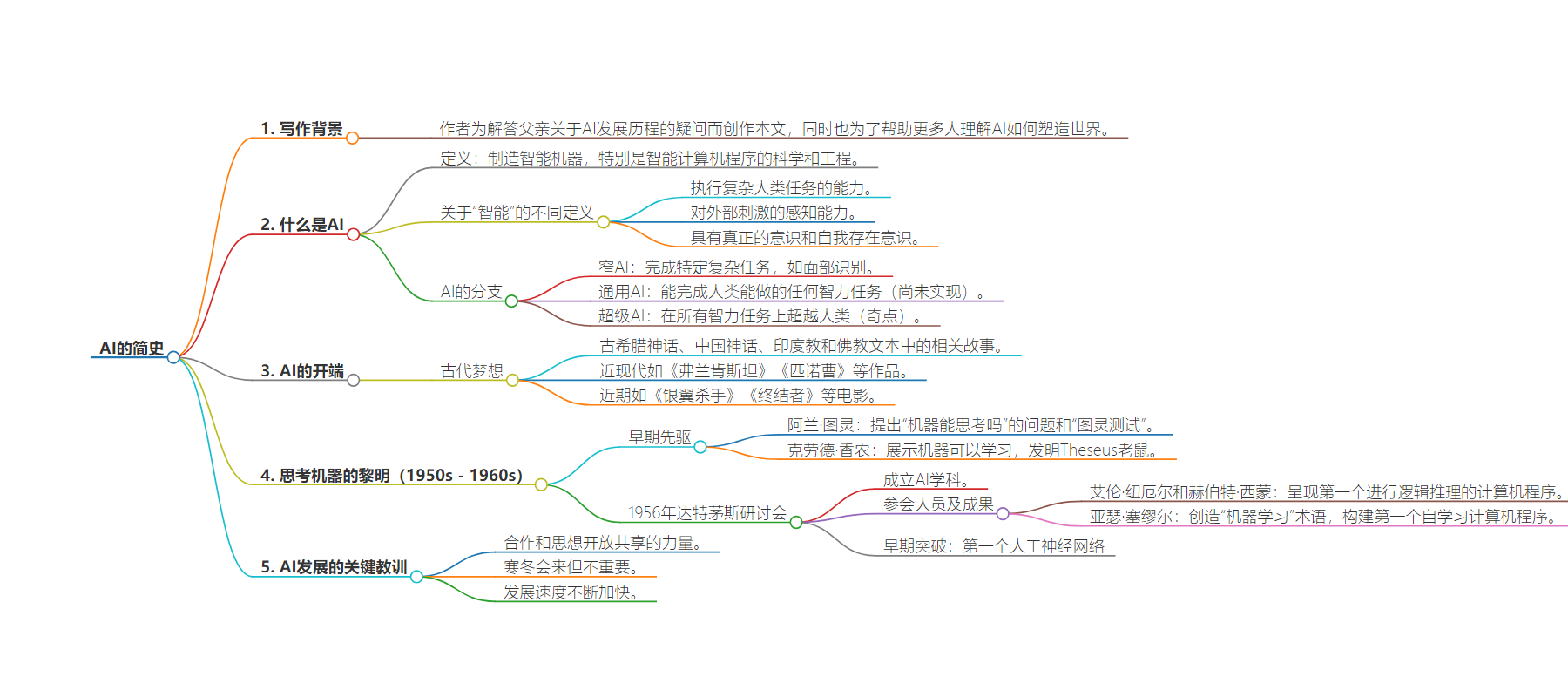
文章地址:https://www.timescale.com/blog/a-brief-history-of-ai/
文章来源:timescale.com
作者:Ajay Kulkarni
发布时间:2024/7/16 16:11
语言:英文
总字数:6868字
预计阅读时间:28分钟
评分:91分
标签:人工智能的历史,人工智能寒冬,机器学习起源,神经网络,专家系统
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Artificial intelligence (AI) has gone from science fiction to breathtaking reality in just a few years. How did we get here, and where do we go from here? What lessons can we learn from the history of AI, and how can they help us predict the evolution of artificial intelligence? This article is for anyone trying to understand AI and how it may shape our world. It’s also the first of a two-part series on AI’s history (this article) and future (the next article).
I initially wrote this article for my father.
My father is a tech entrepreneur. Born and raised in India, he attended IIT (Indian Institute of Technology) and then made his way to New York City. In the mid-1980s, he quit his lucrative job as a programmer at a large bank to go “all in” on his side hustle, a Queens retail store selling personal computers. He was hooked. That started his multi-decade (and counting) journey in tech entrepreneurship. He then shared his love, enthusiasm, and curiosity for technology with me. He’s the number one reason I work in technology and am an entrepreneur myself.

These days, the roles are reversed: I’m the one sharing with him all the exciting new things I am seeing in tech. Of course, the latest topic is AI, the topic that is on the minds of developers worldwide.
He, like me, is wowed by the incredible progress made in the last few years in the world of generative AI. But then he asked me a seemingly simple question that I couldn’t answer: “How did we get here?”.
Considering that I was a Graduate Student at the MIT AI Lab in the early 2000s, when I received my Masters degree in Computer Science, it’s a natural question for my father to ask me. But I realized that, despite all my training and experience, I just didn’t know.
In fact, it’s a really good question: How did we get from the birth of AI in the 1950s to today? How did AI developments accelerate so quickly in the past several years? And what can that tell us about what the future may hold?
This article series is for him, but also for anyone trying to understand artificial intelligence and how it might shape our world. Because it is only by understanding how we got here that we can begin to understand what our future holds.
The history of AI is a story that starts thousands of years ago but that accelerates in the last one hundred years. It is a story of incremental progress by academics punctuated by breakthrough innovations that lead to periods of rapid progress. It is a story of financial investment that closely mirrors macroeconomic conditions, for better or worse. It is a story of high peaks of enthusiasm (“AI Summers”) and low troughs of discouragement (“AI Winters”). It is a story of hype frequently outpacing reality—but then reality catching up and surpassing the hype. It is also a story that has only just begun, with more questions than answers.
The history of AI looks like this:

And as we will see, that history teaches us three key lessons, which offer a glimpse into the future of AI:
- Lesson 1: The power of collaboration and open sharing of ideas
- Lesson 2:
Winter is comingWinter doesn’t matter - Lesson 3: The pace is only increasing
Let’s start.
Introduction: What Is AI?
Artificial intelligence is commonly defined as “the science and engineering of making intelligent machines, especially intelligent computer programs” (source). But what exactly is “intelligence”? It depends on who you ask.
Some define intelligence as the ability to perform complex tasks that we would typically only expect a human to do. Others define it with a higher standard: the ability to be aware of external stimuli, or “sentience.” There is also an even higher standard: the ability to have true consciousness and be aware of one’s existence.
Similarly, there are different branches of AI philosophy today. There is narrow AI, or systems designed to perform a narrow complex task well (e.g., facial recognition). There is also general AI, or systems (that do not yet exist), which can perform any intellectual task that a human can do. And there is super AI: even more hypothetical systems that are able to outperform humans on every intellectual task. The moment that super AI arrives is also known as the singularity.
While impressive, today’s AI systems, like ChatGPT, are considered narrow AI. Some believe that this narrow AI state represents the extent of what is possible—this belief is considered “weak AI.” The counter-belief of “strong AI” proposes that general AI or even super AI is possible, even though we have yet to achieve it.
AI Beginnings: The Ancient Dream
While all these terms are relatively new—the term “Artificial Intelligence” was only coined in the 1950s—humans have been dreaming of creating artificial life and intelligence for millennia.

In Greek mythology, Pygmalion, tells the story of a sculptor who falls in love with one of his statues, which later comes to life. Chinese mythology tells the story of Yan Shi, who almost loses his life after a king feels threatened by a human-like mechanical creation of his. Old Hindu and Buddhist texts mention the bhuta vahana yantra, or spirit movement machines that guarded Buddha’s relics. (For those hungry for even more examples, you might enjoy this book: Gods and Robots.)
We have more such stories in modern times, like Mary Shelley’s Frankenstein (1818) and the original Italian Pinnochio (1883). Even more recently, we have many movies and stories that wrestle with the notion of artificially intelligent beings, including Blade Runner (1982), Terminator (1984), her (2013), and Ex Machina (2014).

This ancient, multi-millennia fascination makes sense: the act of creating life was often seen as the clear domain of divine beings. In that way, we have often seen the ability to create artificial life as the ultimate power.
Yet these are all just stories. It wasn’t until the 20th century that we started to acquire that power.
Dawn of Thinking Machines (1950s to 1960s)
The dawn of what we call “artificial intelligence” today started in the 1950s, with early breakthroughs leading to early excitement. Collaboration and the open sharing of ideas drove the success of this era, which is a theme we will continue to see in the development of AI.
AI pioneers: Turing and Shannon

In 1950, a brilliant English mathematician posed a provocative question: “Can machines think?”. The mathematician in question was Alan Turing, and he posed it in his foundational paper, Computing Machinery and Intelligence. In that paper, Turing also proposed what we now call the “Turing test”: a test for machine intelligence, where a machine is considered intelligent if it can imitate human responses well enough to be indistinguishable from a human. (Turing was also the subject of the 2014 movie, The Imitation Game.)

Around that same time, an American mathematician named Claude Shannon showed the world how a machine could learn. His invention, the Theseus mouse, could learn how to navigate a maze through trial and error and then remember the correct path. Demonstrating one of the first forms of “machine learning,” Shannon built this device using just telephone circuits.
Shannon, who is known as “the father of the Information Age,” also did much more, including writing what some consider the most important master’s thesis of all time while at MIT, where he established the theory behind digital computing by showing how boolean algebra could represent any logical numerical relationship.
The founding of AI: The 1956 Dartmouth Workshop

The field of AI was officially founded in 1956, when Shannon, along with other computer science pioneers John McCarthy, Marvin Minsky, and Nathaniel Rochester, organized an academic conference that established AI as a discipline.
This eight-week workshop, titled The Dartmouth Summer Research Project on Artificial Intelligence, was a milestone event that included about 20 academics who met to explore the possibility of creating intelligent machines. That group included many whom we now consider to be the founders of the modern discipline of AI.
That includes Allen Newell and Herbert Simon, who presented the first computer program to perform logical reasoning (or, in other words, the first AI computer program) at the conference. Called the Logic Theorist, it proved 38 mathematical theorems, in some cases finding newer and shorter proofs. (Despite this achievement, the workshop attendees were not impressed—innovation can truly be hard to spot, even by the people on the leading edge.)
Another workshop attendee was Arthur Samuel, who coined the term “machine learning” in 1959 and built the first self-learning computer program, a program that could play the game of Checkers. This program chose moves that would maximize its chances of winning based on a scoring function. It could also remember every position it had ever seen, allowing it to learn from experience. He also played the program against itself thousands of times as another way to build experience. Eventually, his program could challenge a human amateur player.
Another early breakthrough: The first artificial neural network
The Dartmouth Workshop helped create an intellectual atmosphere that encouraged more academic research, leading to more breakthroughs.

In 1958, American cognitive systems and research psychologist Frank Rosenblatt built the first artificial neural network model, a machine called the Mark I Perceptron, based on the “perceptron” concept first proposed in 1943. This machine could classify inputs (e.g., image pixels) into one of two categories (binary classification), allowing it to recognize simple shapes or characters. While simple, it was the first implementation of a neural network and laid the groundwork for the more complex neural networks and deep learning models of today.
However, by the end of the 1960s, it became clear that the state-of-the-art was falling behind expectations. Academics themselves questioned what was possible, including a criticism of Perceptrons published by Marvin Minsky and Seymour Papert in 1969. AI enthusiasm started to wane.
The Long AI Winter (1970s to 2000s)
Hype has always surrounded AI. In fact, the term “artificial intelligence” itself was coined mainly as a way to generate fund-raising hype. But when hype creates expectations that reality cannot match, it leads to disappointment.
This “hype/disappointment” dynamic is a central theme of AI. It has created a type of AI seasonality: a pattern of fluctuating enthusiasm over time, often described in terms of the four weather seasons of the year. As we will see, AI seasonality is also highly affected by macroeconomic conditions: economic booms increase enthusiasm; economic recessions decrease enthusiasm.
So, if we consider the 1950s-1960s as an “AI Summer,” by the beginning of the 1970s, we entered the “Long AI Winter”: a four-decade span with generally low AI enthusiasm.
We can break down the Long AI Winter into four periods:
- First Winter (1974-1980)
- False Spring (1980-1987)
- Second Winter (1987-1993)
- Great Thawing (1993-2010)
First Winter (1974-1980)
The first AI winter lasted from 1974 to 1980 when research funding for AI from governments and private investors started to decrease, and researchers moved away from AI to other fields. This period also coincides with a general global economic recession, created partly by the 1973 oil crisis, which lasted until the early 1980s.

Yet, this period still saw innovation that would fuel future AI research. First, the microprocessor, initially introduced by Intel in 1971, started to make computing more affordable and accessible. Second, the personal computer, introduced by Altair and then Apple, began to bring computing to the individual consumer, whether at work or home.
False Spring: Expert systems boom (1980-1987)
By 1980, Winter turned into Spring—but unfortunately, it would be short-lived.
First, the success of early computing companies (e.g., the 1980 Apple IPO, which valued Apple at over one billion dollars) led to an increase in commercial investment in technology and the founding of many technology startups, including AI.

Second, the early 1980s also saw the creation of powerful workstations from companies like Sun Microsystems, which provided the computer science community and researchers with significantly more computing power than before. (Sun Microsystems was built on the SUN workstation architecture, co-developed by Timescale investor and long-time board member Forest Baskett.)
Third, the 1980s also saw the beginning of another macroeconomic boom, which fueled even more enthusiasm.
This led to a boom of a type of AI architecture called expert systems: computer systems designed to emulate the knowledge and decision-making of a human expert. Expert systems were created for both research and commercial purposes: to configure VAX computers (XCON), to diagnose diseases (CADUCEUS), and to help the efficiency and reliability of manufacturing processes (CATS-1).
These were rule-based systems: systems that applied a set of numerous hardcoded “if-then” rules to make decisions (e.g., XCON had thousands of rules). While this allowed for a high level of transparency in how a decision was made, it was difficult to scale and maintain.
Second Winter (1987-1993)
The practical challenges of scaling and maintaining expert systems, combined with the Black Monday financial crisis (1987) and the economic recession of the early 1990s, led to a second AI Winter. Yet, like the first winter, this period also saw the development of key innovations for future AI research.
In particular, there was a revival of neural network research. This revival started in 1986, when David Rumelhart, Geoffrey Hinton, and Ronald Williams introduced their backpropagation algorithm to train multilevel neural networks efficiently. It represented a significant development: starting with Minksy and Papert’s criticism of perceptrons in 1969, neural networks had become less popular due to the limitations of single-layer networks. But now, backpropagation has enabled the practical use of multi-layer neural networks.
Next came a new type of machine learning model called convolutional neural networks (CNNs), by Yann LeCun and others (1989), which plays a crucial role in today’s AI advancements.
Unlike traditional neural networks, CNNs apply a mathematical operation called convolution (combining two functions to produce a third function). Applying convolution led to more powerful neural networks, with parameter efficiency (fewer parameters that then require less training) and a better ability to capture spatial hierarchies and local patterns. These improvements made CNNs especially useful for complex tasks involving spatial data, such as image and video recognition.
Note: We will see the names Geoffrey Hinton, Yann LeCun, and Yoshua Bengio again. These three are now collectively known as “The Godfathers of Modern AI.”

Great Thawing: Internet, Big Data, the Cloud, and the GPU (1993-2010)
The Great Thawing was a period of substantial technological progress. Yet again, macroeconomics played a key role: the 1990s saw significant economic growth globally, particularly in the United States. It also saw the “dot-com boom” from the mid-1990s to the early 2000s.
While most of the progress occurred outside of AI, this period marked the end of the Long AI Winter, setting the foundation for the AI Renaissance we see today.
(This is also the period that includes my time at the MIT AI Lab in the early 2000s. My thesis, on Intelligent Environments, was building and exploring a rule-based system that seems rudimentary compared to the systems of today. Maybe I was 10 years too early. 😊)
The modern Internet
First came the modern Internet, which had a “rising tide” effect on all things technology-related.

The Internet, in turn, was fueled by multiple innovations, including the World Wide Web, HTML (1990), and HTTP (1991); the first web browsers, Mosaic (1993), Netscape Navigator (1994), and Internet Explorer (1995); the first search engines, Yahoo! (1994), AltaVista (1995), and Google (1998); the investment of tens of billions of dollars in laying fiber-optic cables; and more.
The Internet also made it much easier to collaborate remotely, leading to increased international collaboration in the research community.
The rise of Big Data
Next, the explosive growth of the Internet led to the rise of Big Data: an explosive growth of data generated. (“From the dawn of civilization to 2003, five exabytes of data were created. The same amount was created in the last two days.” – then Google CEO Eric Schmidt in 2010.) The rise of Big Data, which has only continued and increased since then, has provided helpful training data for hungry convolutional neural network models.
The Cloud
The Internet also gave us cloud computing services, or pay-as-you-go models, to rent computing power and storage on demand. The first one was Amazon Web Services (AWS), launched in 2006, which initially offered S3 (storage) and EC2 (compute). The Cloud made computing and storage even more accessible to individuals and small teams.
The GPU and CUDA
The end of the 1990s also saw the introduction of the first “Graphics Processing Unit” (GPU), the GeForce 256 by NVIDIA (1999). While its use was mainly for graphics, this marked the beginning of a new type of processor that excelled in parallel processing and would later drive more AI growth. Several years later, NVIDIA launched CUDA (2007), a parallel computing platform and API for GPUs, making development on GPU even easier.

AI advancements
There were also AI advancements in this era, including hidden Markov models (HMMs) (1990), a probabilistic framework for modeling sequences that helped with speech and language processing, and support vector machines (SVMs) (1995), a highly accurate and powerful supervised learning algorithm for classification in high-dimensional spaces, such as text categorization, image recognition, and bioinformatics. (However, while these were impressive improvements, they have since become less important thanks to the rise of deep learning.)
Later AI work during this period proved to be more foundational. Deep belief networks, introduced in 2006 by Geoffrey Hinton and colleagues, were among the first models to demonstrate effective unsupervised learning. This innovation overcame the difficulties associated with training deep models by showing it was possible to pre-train deep neural networks layer by layer—this revitalized interest in neural networks and deep learning.
ImageNet, by Fei Fei Li and others (2009), provided something vital for future AI research: a large visual database of millions of hand-annotated images. They achieved this massive work using one of the first cloud infrastructure services, Amazon Mechanical Turk. (One of the co-authors of the ImageNet paper was early Timescale angel investor Kai Li.)

AI in pop culture: Deep Blue vs. Garry Kasparov
The late 1990s also saw a landmark event in AI and pop culture when IBM’s chess-playing computer Deep Blue defeated the world champion Garry Kasparov (1996-1997). While Deep Blue was a specialized system that primarily relied on brute force search and hard-coded knowledge, this event showcased AI’s growing capabilities and power.

Resurrection: Deep Learning Revolutions (2010s)
Neural networks, the microprocessor, the computer, the Internet, Big Data, the Cloud, the GPU, ImageNet: all these innovations across multiple decades and multiple winters laid the groundwork for the Deep Learning Revolutions in the 2010s. And again, collaboration and the open sharing of ideas drove the groundbreaking AI progress of this period.
Revolution 1: The rise of deep learning (2012-2017)
The first revolution was the rise of deep learning, the use of neural networks with many layers (“deep”) to model and understand complex patterns in large datasets, as an effective architecture. (Deep learning is a subset of machine learning, which in turn is a subset of AI.)
AlexNet
The first revolution began in 2012, the year Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton introduced AlexNet. AlexNet was one of the first GPU implementations of a CNN (based on the architecture introduced by Yann LeCun in 1989) and written with CUDA. It dramatically outperformed other methods in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). These results made both CNNs and CUDA/GPUs popular among AI researchers and generated a lot of excitement in AI.

(And then the floodgates opened. Please fasten your seatbelts.)
DeepMind
The following year, in 2013, DeepMind (a London-based startup first founded in 2010 by Demis Hassabis, Shane Legg, and Mustafa Suleyman) published a breakthrough paper outlining a system called Deep Q-Network (DQN). DQN used a deep CNN with reinforcement learning, enabling it to learn and play several Atari 2600 games directly from pixel input. This system was the first deep learning model to learn directly from high-dimensional sensory input and was able to beat human players in many of the games.
Google acquisitions and research
The groundbreaking work by the AlexNet and DeepMind researchers got the attention of Google, who started acquiring their companies as a way to incorporate their AI expertise. Acquisitions included DNN Research (acquired for $44M in 2013), a company started by the AlexNet authors to field acquisition offers (fun story of the acquisition here, which was run as an auction inside of a Lake Tahoe casino); and DeepMind (acquired for ~$500M in 2014).
Also in 2013, a team at Google developed word2vec, which introduced new techniques for generating high-quality, high-dimensional vector representations on large data sets with billions of words (also known as an “embedding”). This representation preserved even semantic information that could be used in vector arithmetic (e.g., “king” – “man” + “woman” ≈ “queen”). (This concept was later used by the Transformer architecture, which serves as the foundation for modern large language models.)
The year 2014 saw the first generative adversarial network (GAN), by Ian Goodfellow (also employed as a researcher at Google) and colleagues, a class of machine learning framework where two neural networks compete against each other by generating new data made to look as authentic as real data (e.g., generating new photographs designed to look like photographs). This research laid the foundation for generative AI.
Note: For all the head start that Google had in AI, it is remarkable that they are not the leader in AI today.
In 2015, Yann LeCun, Yoshua Bengio, and Geoffrey Hinton, now considered three of the godfathers of modern AI, published an overview paper on the latest research called Deep Learning. The same three would go on to win the Turing Award in 2018, an award that is considered the Nobel Prize of Computing, named after Alan Turing (the British researcher we covered earlier).
AlphaGo (and the move that shocked the world)
The DeepMind team, now at Google, achieved another breakthrough in 2016: they built AlphaGo, which beat one of the world’s top Go players in a five-game match. This was a monumental achievement. Go is an incredibly complex ancient Chinese board game. While chess has about 10120 possible positions, Go has 10170 or 50 orders of magnitude more.
DeepBlue was able to beat Garry Kasparov in chess using brute force search, but that approach could not work with Go. Instead, AlphaGo relied on deep learning and reinforcement learning. More specifically, AlphaGo relied on a novel approach where it learned to play Go by playing against itself, improving its performance without human intervention.
This approach allowed it to learn Go strategies, which even human players had not discovered in the last 2,500 years. (Its move 37 in the second game was so unique that experts thought the program had made a mistake. It also shocked Lee Sedol to such an extent that he left the match room and then took 15 minutes just to respond.)

The DeepMind team then took these learnings and built the first iteration of AlphaFold (2018), which became especially successful at predicting protein structure, one of the most difficult problems of computational biology. This showed that the power of AI wasn’t just to win board games but that it could also lead to real scientific progress.
Revolution 2: The age of Transformers and large language models (2017-2022)
Deep learning, and the AI Industry in general, reached another inflection point in 2017, with the publication of a landmark technical paper with an unusual title: Attention Is All You Need.
The Transformer model
That paper, authored by eight Google scientists, introduced the Transformer, a new deep learning algorithm based on a concept called “attention” (first proposed in 2014). This architecture is what enables astonishing AI innovations today, like generative text and image products ChatGPT, Midjourney, and Dall-E. (Both the architecture and paper names are inspired by pop culture: the “Transformers” toys from Hasbro and the song All You Need Is Love by The Beatles. Another fun read here.)
The Transformer architecture takes a sequence of text (also known as the “context window”) as an input. But rather than processing the text in that sequence, it analyzes each word (also known as a “token”) in the sequence in parallel to understand the relative importance of each word within the context of the sequence.
It does this using “self-attention,” where each word (token) in the input sequence (context window) scores with each other word (token). These scores then determine how much importance or “attention” each token should pay to the others. The first step in this process is converting each word into an embedding, the same concept initially pioneered by word2vec.
(Despite being a breakthrough, the Transformer architecture did not initially take off at Google. All of the Transformer paper authors have since left Google, mostly to start new companies.)
Large language models (LLMs)
Transformers then led to another modern-day major advancement in AI: large language models (LLMs), a type of model that is trained on large-scale datasets to understand and generate human language, text, images, audio, video, and other types of data.
One of the first LLMs published to the world was GPT-1 (Generative Pre-Trained Transformer 1) by OpenAI in June 2018, featuring Ilya Sutskever (of AlexNet and DNN Research fame) as a co-author and key contributor. Soon after, Google released BERT (Bidirectional Encoder Representations from Transformers) in October 2018.
While both GPT and BERT share the Transformer architecture, each is engineered to optimize for different tasks. GPT builds its context understanding by unidirectionally processing text (left to right), allowing it to predict the next word based on the preceding context. BERT builds its context by processing text bidirectionally (left to right and right to left), enabling it to have a more comprehensive understanding of the context around a word.
These are both improvements over word2vec, which generates a single embedding per dictionary word, regardless of context. Then again, word2vec is much simpler, making it more computationally efficient.
As a result, BERT excels in understanding context, making it more useful for natural language processing (NLP) and understanding. The GPT family of models is groundbreaking for its text-generation ability and few-shot learning approach (the ability to learn with very few training examples).
Since 2018, the adoption and development of both have taken off. As of October 2020, almost every single English-based Google query was processed by a BERT model (source).
And the GPT architecture has gone through a few iterations, each much larger than the one before: GPT-1 (2018), 117 million parameters, trained on the BooksCorpus dataset (7,000 unpublished books); GPT-2 (2019), 1.5 billion parameters, trained on the WebText dataset (8 million web pages); GPT-3 (2020), 175 billion parameters, trained on a diverse dataset including Internet text, books, articles, and websites; GPT-4 (2023), parameter count and training dataset not shared by OpenAI; and GPT-4o (2024), which improves on GPT-4 by processing not just text but also images and audio, with a larger context window, in less time, and at 50 percent the cost.
Other LLMs from this time include RoBERTa (2019) from Meta AI, and OpenAI Codex (2021), which is trained to translate text to software code (and powers GitHub Copilot).
These are all impressive technological achievements that represent major advances in the state of AI. But it was one of them—GPT-3 and a product called ChatGPT based on it—that launched the AI Renaissance that we find ourselves in today.
Renaissance: The Magical Black Box Era (2022 to Today)
ChatGPT
Nearly everyone in tech can remember the moment they first used ChatGPT. For me, it was at a Thai restaurant in San Francisco with colleagues, and the moment felt magical, reminding me of the first time I used the Internet in 1996. I knew this would change everything, even though I had no idea how.
Initially released on November 30, 2022, ChatGPT was a tornado that turned the tech world, and later, the business world, upside down. It was a relatively straightforward idea: building a chat product on top of GPT-3, fine-tuned for conversational interactions. But the scope of what it could do was beyond remarkable: summarize text; write new text in the form of a famous person, dead or alive; explain complex topics and tailor those explanations based on the age of the reader; put together travel itineraries; plan your weekly meals; and so much more.
ChatGPT and these GPT models were smart. One research paper from 2023 showed how well GPT models performed on various standardized tests (and how that performance was improving over time).
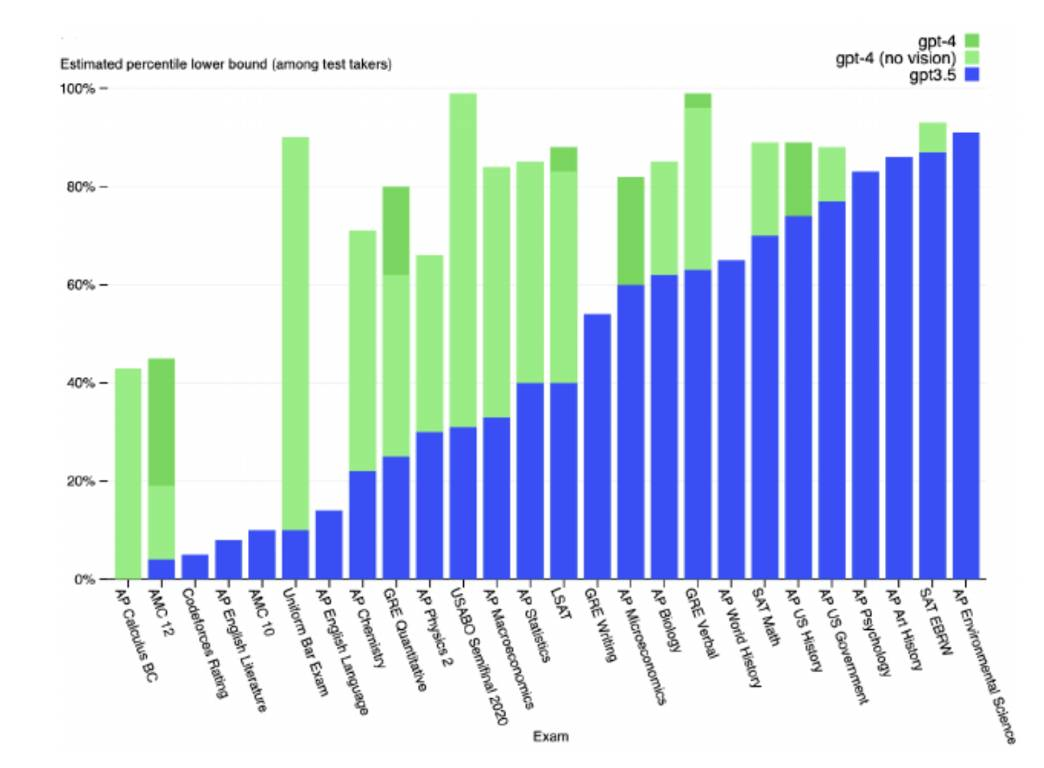
“Really good auto-complete” systems become Magical Black Boxes
Here is the crazy part: unlike the rule-based expert systems of the past, which had a level of transparency that allowed us to understand how they worked, ChatGPT and LLMs in general are essentially “black boxes.”
They are systems trained on large-scale datasets that take in a series of tokens and then generate output by predicting each subsequent token. They are just advanced token prediction systems—or, put another way, “really good auto-complete.” Yet, they can seemingly answer many questions accurately. And we don’t know how.
The black-box nature of LLMs has given rise to a new field called prompt engineering, which is the process and knowledge of creating the right input prompts to an LLM to get the desired output. These prompts vary from simple to complex.
Some academics believe that it is impossible for humans to understand how an LLM works:
“There are hundreds of billions of connections between these artificial neurons, some of which are invoked many times during the processing of a single piece of text, such that any attempt at a precise explanation of an LLM’s behavior is doomed to be too complex for any human to understand.” (Source)
How do they work? Magic.
Generative AI boom
ChatGPT and LLMs launched the generative AI boom we are in today.
This boom includes the creation of new LLMs, backed by hundreds of billions of investment capital, such as Llama (2023) from Meta AI; Google’s Bard, later re-launched as Gemini (2023), now incorporated into Google Search; Anthropic’s Claude (2023), which many consider the leading LLM at the moment (Anthropic was founded by former OpenAI employees with a focus on AI safety; Claude named after Claude Shannon); and various models from Mistral AI (started by ex-Google and ex-Meta folks in 2023).
It’s also led to an explosion of companies building generative AI-driven applications/features and software infrastructure.

This boom also led to OpenAI achieving the fastest path to 100 million users, which ChatGPT reached in a mind-blowing fast two months (it took the telephone 75 years to reach 100 million users). It has also led to billions in revenue, $3.4 billion (annualized run rate) from OpenAI alone in (June 2024).
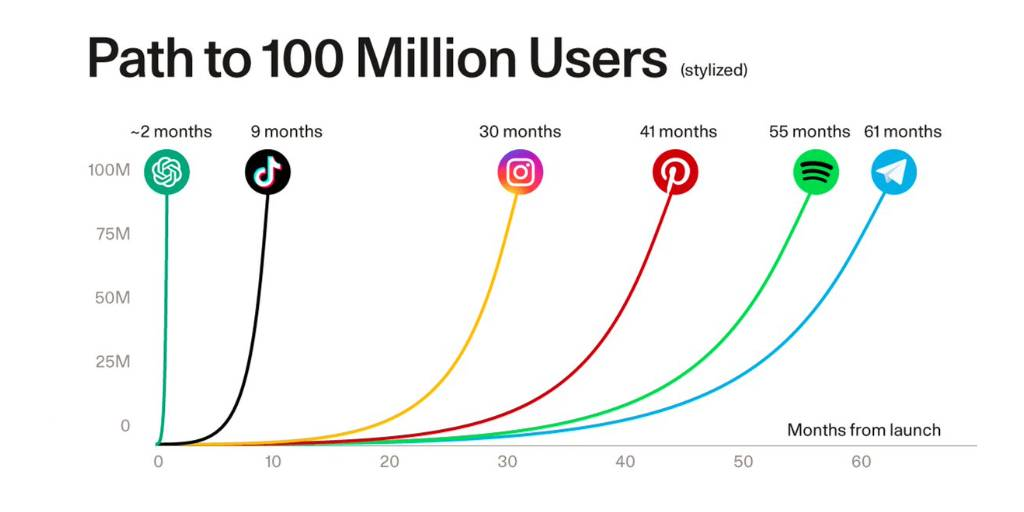
This growth has all happened in less than two years. That alone is astounding. The next question is obvious: Where do we go from here? To answer that, let’s first understand what we have learned so far.
AI History: Lessons Learned
We have just covered 80 years of the AI industry in over 4,000 words. Here’s what we learned:
Lesson 1: The power of collaboration and open sharing of ideas
One of the most striking lessons from the History of AI is the crucial role collaboration and the open sharing of ideas have played in its development. From the early days of Turing and Shannon all the way to the collaborative nature of modern research today, AI has thrived on collective intellectual effort. The success of deep learning and other AI advancements can be traced to a culture of sharing breakthroughs and building upon each other’s work rather than siloed, proprietary research.
Similarly, AI inspires curiosity across many disciplines, and AI advancements have drawn insights from various fields: mathematics, neuroscience, psychology, computer science, and philosophy. The structure of the human brain has inspired the design of neural networks, and reinforcement learning borrows concepts from behavioral psychology. This cross-pollination and sharing of ideas has been crucial in advancing the state of the art.
This is a lesson worth remembering, especially in today’s era of proprietary services (that reduce collaboration) vs. open-source projects (which increase collaboration). (This is also a reason why we have made our AI work at Timescale open-source.)
Lesson 2: Winter is coming Winter doesn’t matter
I have often been asked, “When is the next AI Winter?” or, in another form, “AI is all hype.”
But when you look at the history of AI, you see that while AI has seasonality, great work happens in the Summer and in the Winter.
- AI has seasonality: Hype has always surrounded AI, starting with the naming of the term itself. But when hype creates expectations that reality cannot match, it leads to disappointment. As we saw, the “hype/disappointment” dynamic is a central theme of AI. This leads to seasonality, exacerbated by macroeconomic conditions: economic booms increase enthusiasm; economic recessions decrease enthusiasm. This can make research and investment difficult, but this is the nature of AI.
- But great work happens in the Summer and Winter: Despite AI’s seasonality, great work has happened in both good times and bad. Foundational work in neural networks (backpropagation, convolutional neural networks, deep belief nets) and other areas (hidden Markov models, support vector machines, ImageNet) all happened during an AI Winter. There has also been foundational technological progress during Winters—the microprocessor, the computer, the Internet, Big Data, Cloud Computing, and the GPU—which helped accelerate future AI work.
So yes, AI is often surrounded by hype (and later, disappointment). But progress marches on. In this world, we need to keep calm, keep building and investing, and carry on.
Lesson 3: The pace is only increasing
The pace of AI innovation has increased, especially in the past two decades. This acceleration has transformed AI from a niche area of academic research to a pervasive technology with wide-reaching implications.
In the early days, the 1950s to 1960s, work was slow and steady, and largely confined to academic circles. In contrast, from 2010 to today, the pace has been breathtaking, making it hard even for people in academic circles, let alone society at large, to keep up. We can see this trend by looking at the number of AI papers published over time:
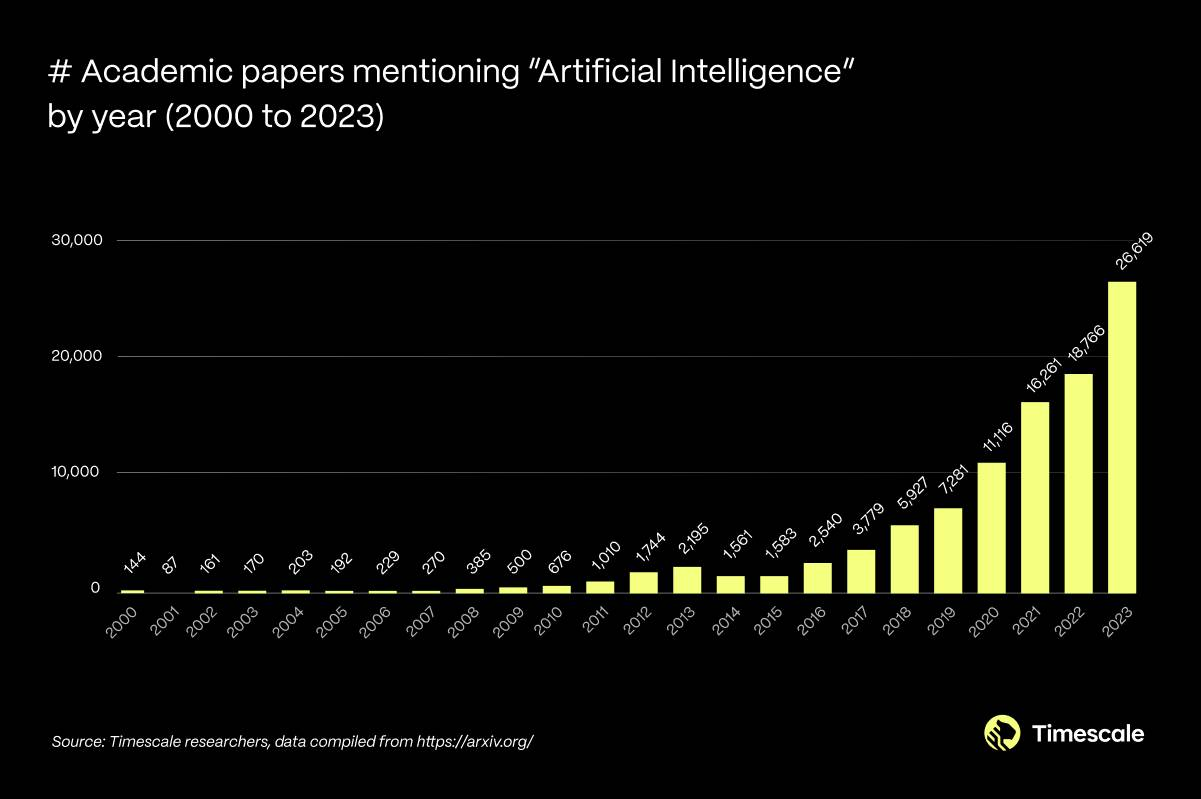
Today, there is a sentiment that AI is experiencing its own faster version of Moore’s Law. The capabilities of AI models are improving at an astonishing rate. Combined with improvements in fundamental technology, including compute and storage, we are likely embarking on a period of continued exponential growth.
What this means is that what seems like science fiction today will soon become a reality. This rapid progress introduces both opportunities and challenges: potential areas of innovation for solving important problems but also important ethical and existential questions about the impact of AI on human society.
Future: Where Do We Go From Here?
The story of AI is a story rooted in ancient history. Today’s research helps us fulfill our ancient dream. That is the reward we are all striving for, consciously or subconsciously.
But for every Pygmalion, there is Prometheus: the mythological figure who stole power from the Gods and shared that knowledge with humans—and, as a result, was punished for eternity.
Hand in hand with the Ancient Dream is the Ancient Nightmare: that creating artificial life leads to humanity’s doom. To understand AI is to understand both the dream and the nightmare.
Looking ahead to the future, AI opens exciting possibilities but also reawakens old fears. We have the opportunity to harness this power for profound good. But doing so will require open collaboration across all disciplines, consistent building and investing despite the season, and continuous learning to keep up with the rapid pace.
So what might the future hold? Will our world be full of AI agents working for us? How do we, as individuals, take advantage of all this change in our professional and personal lives? That’s the topic for part two.
Thanks for reading to the end. Feedback, suggestions, or corrections? Please just let me know. And Dad, sorry this post ended up so long. I’ll have to summarize it for you in person. 😊
Appendix: Reading list!
Dawn of Thinking Machines (1950 to 1960s)
- Alan Turing (1950) – “Computing Machinery and Intelligence”
- Turing, A. M. (1950). Computing Machinery and Intelligence. Mind, 59(236), 433-460. doi:10.1093/mind/LIX.236.433
- Claude Shannon (1948) – “A Mathematical Theory of Communication”
- Shannon, C. E. (1948). A Mathematical Theory of Communication. The Bell System Technical Journal, 27(3), 379-423. doi:10.1002/j.1538-7305.1948.tb01338.x
The Founding of AI: The 1956 Dartmouth Workshop
- Allen Newell and Herbert Simon (1956) – “The Logic Theory Machine: A Complex Information Processing System”
- Newell, A., & Simon, H. A. (1956). The Logic Theory Machine: A Complex Information Processing System. IRE Transactions on Information Theory, 2(3), 61-79. doi:10.1109/TIT.1956.1056799
- Arthur Samuel (1959) – “Some Studies in Machine Learning Using the Game of Checkers”
- Samuel, A. L. (1959). Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development, 3(3), 210-229. doi:10.1147/rd.33.0210
- Frank Rosenblatt (1958) – “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain”
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review, 65(6), 386-408. doi:10.1037/h0042519
- Marvin Minsky and Seymour Papert (1969) – “Perceptrons: An Introduction to Computational Geometry”
- Minsky, M., & Papert, S. (1969). Perceptrons: An Introduction to Computational Geometry. MIT Press.
The Long AI Winter (1970s to 2000s)
- David Rumelhart, Geoffrey Hinton, and Ronald Williams (1986) – “Learning Representations by Back-Propagating Errors”
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning Representations by Back-Propagating Errors. Nature, 323, 533-536. doi:10.1038/323533a0
- Yann LeCun et al. (1989) – “Handwritten Digit Recognition with a Back-Propagation Network”
- LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., & Jackel, L. D. (1989). Handwritten Digit Recognition with a Back-Propagation Network. Advances in Neural Information Processing Systems (NIPS), 396-404.
- Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner (1998) – “Gradient-Based Learning Applied to Document Recognition”
- LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-Based Learning Applied to Document Recognition. Proceedings of the IEEE, 86(11), 2278-2324. doi:10.1109/5.726791
- Fei-Fei Li et al. (2009) – “ImageNet: A Large-Scale Hierarchical Image Database”
- Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., & Fei-Fei, L. (2009). ImageNet: A Large-Scale Hierarchical Image Database. 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248-255. doi:10.1109/CVPR.2009.5206848
Resurrection: Deep Learning Revolutions (2010s)
- Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton (2012) – “ImageNet Classification with Deep Convolutional Neural Networks”
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. Communications of the ACM, 60(6), 84-90. doi:10.1145/3065386
- DeepMind Researchers (2013) – “Playing Atari with Deep Reinforcement Learning”
- Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., Riedmiller, M. (2013) Playing Atari with Deep Reinforcement Learning. arXiv preprint arXiv:1312.5602.
- Ian Goodfellow et al. (2014) – “Generative Adversarial Networks”
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y. (2014). Generative Adversarial Networks. arXiv preprint arXiv:1406.2661.
- Yann LeCun, Yoshua Bengio, and Geoffrey Hinton (2015) – “Deep Learning”
- LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep Learning. Nature, 521, 436-444. doi:10.1038/nature14539
- Vaswani et al. (2017) – “Attention Is All You Need”
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention Is All You Need. arXiv preprint arXiv:1706.03762.
- OpenAI (2018) – “Improving Language Understanding by Generative Pre-Training”
- Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI.
- Jacob Devlin et al. (2018) – “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
Renaissance: The Magical Black Box Era (2022 to today)
- OpenAI (2020) – “Language Models are Few-Shot Learners”
- Brown, T. B., et al (2020). Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165.
These references provide a solid foundation for readers interested in exploring the key developments and contributions in the history of AI.
Ingest and query in milliseconds, even at terabyte scale.